Overview
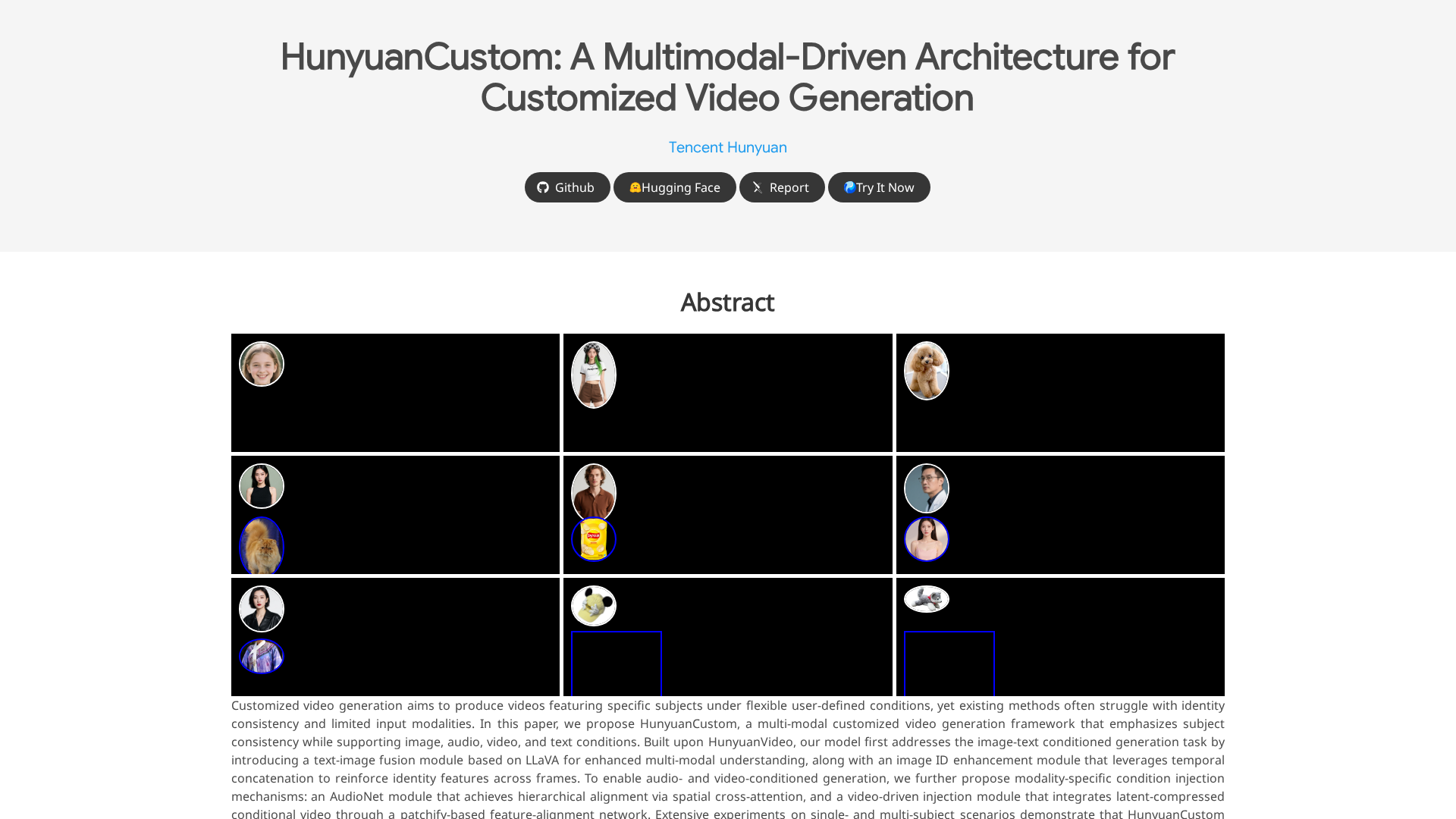
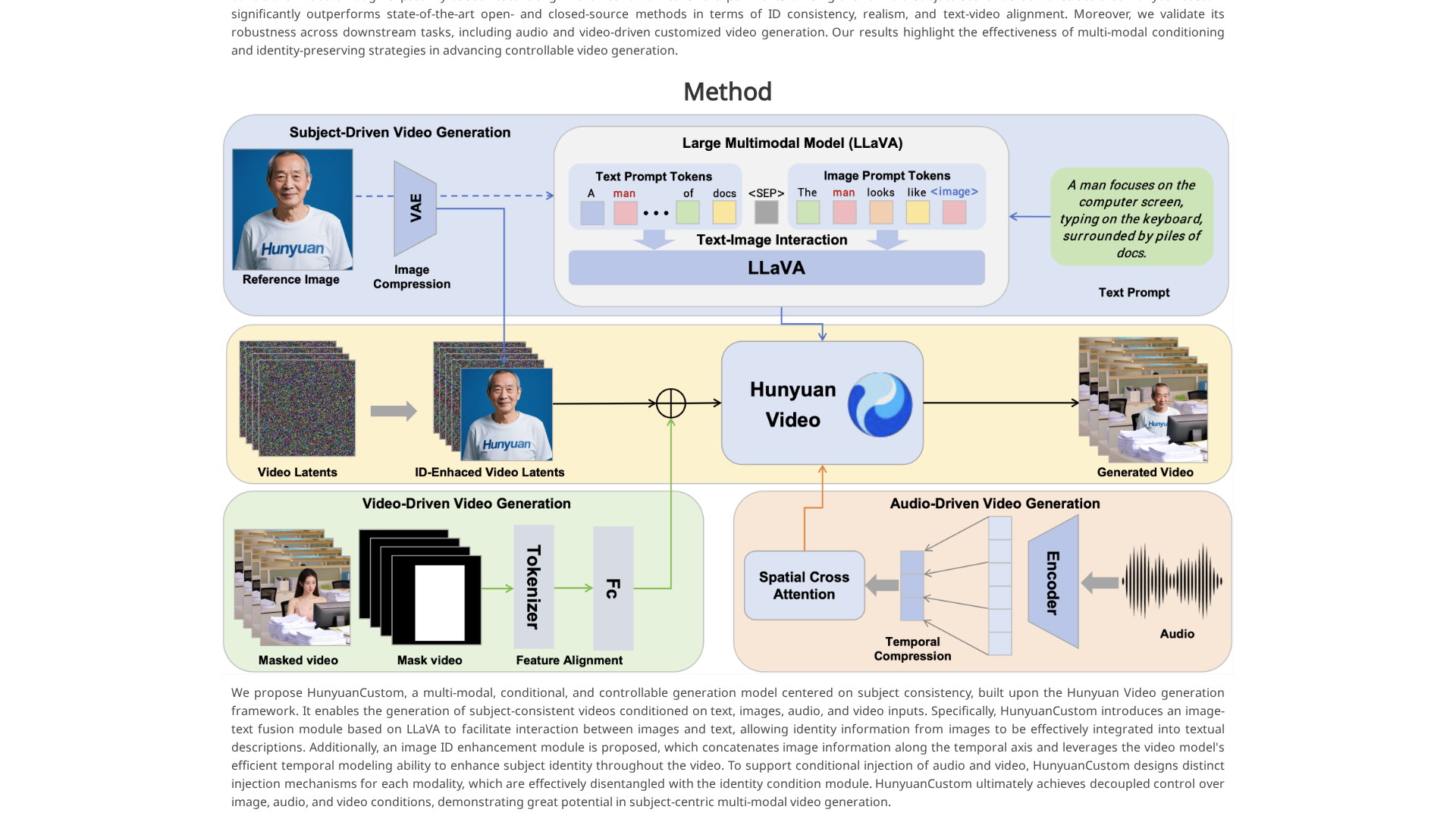
HunyuanCustom is a multimodal conditional video-generation pipeline designed to preserve subject identity while supporting flexible conditioning from text, images, audio, and video. Built on a HunyuanVideo backbone, it introduces modules to close modality gaps and prevent identity drift so generated videos remain faithful to a provided subject image(s). Key components include a Text–image fusion module (LLaVA-based) for injecting image identity cues into text prompts, an Image ID enhancement module that temporally concatenates image features across frames, AudioNet for audio-conditioned alignment of audio and visual features, and a patchify-based video-driven injection for latent-conditioned editing. The framework uses a disentangled identity representation to decouple identity information from other modalities, enabling independent control over image, audio, and video inputs. Supported workflows include single-subject video customization, video-driven editing with masks, and audio-driven customization, with downstream use cases such as singing avatars and virtual advertisements. Deployment details cover Linux, CUDA, PyTorch, multi-GPU setups, and Docker/Gradio-based tooling.
Key Features
Text–image fusion module
LLaVA-based module that injects image identity cues into textual prompts to improve image+text conditioned generation.
Image ID enhancement
Temporally concatenates image features across frames to strengthen subject identity consistency.
AudioNet
Audio-conditioned module aligning audio and visual features hierarchically with spatial cross-attention for singing/avatar-style generation.
Video-driven injection
Patchify-based feature alignment to inject latent conditional video features for video-driven editing and guidance.
Disentangled identity representation
Separates identity information from other modalities to enable decoupled control over image, audio, and video inputs.
Pricing Plans
Pricing information is not available yet.
Pros & Cons
✓ Pros
Pros will be listed here once they are curated.
✗ Cons
Cons will be listed here once they are curated.
Related Articles (5)
Newsletter signup page offering trending papers on hierarchical cross-attention; no article content provided.
Non-distilled, high-quality Z-Image-Base now with Day-0 ComfyUI support and full ecosystem tooling.
A multi-modal framework for subject-consistent customized video generation from text, image, audio, and video inputs.
A meta-guide showing how user feedback and docs shape metadata for article content.
A multimodal, subject-consistent video generation framework that fuses image, text, audio, and video inputs for controllable synthesis.