Overview
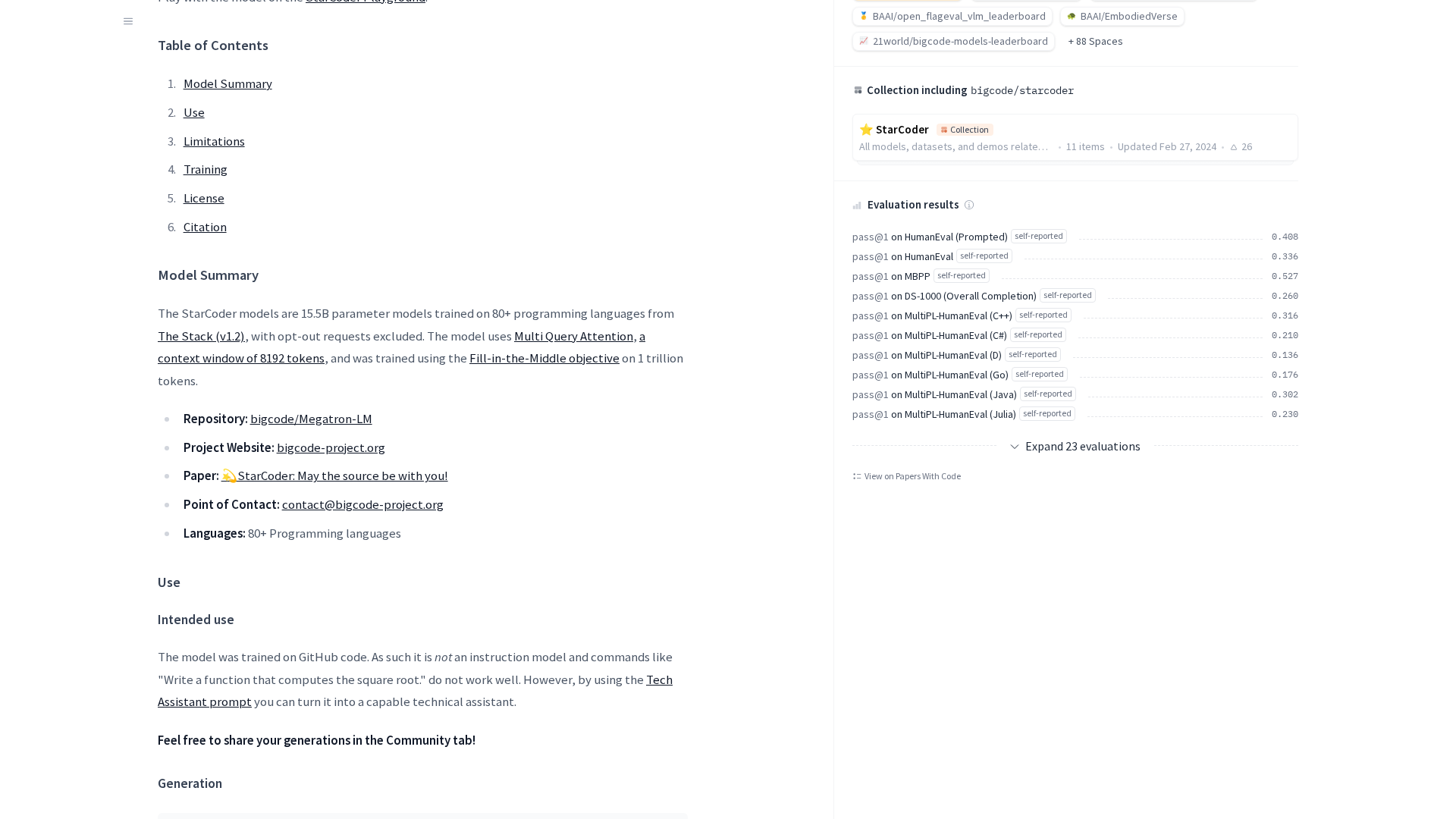
StarCoder is an open-source 15.5B-parameter code LLM (StarCoder / StarCoderBase) trained primarily on The Stack (v1.2) with an opt-out mechanism. It was trained with Fill-in-the-Middle (FIM) objective and uses multi-query attention to support long-context code tasks (commonly described as ≈8k context). StarCoderBase was trained on roughly 1 trillion tokens (paper) and StarCoder is a fine-tuned variant (StarCoderBase → StarCoder) with additional fine-tuning on ~35B Python tokens to improve Python performance. The project uses the Megatron-LM framework and standard mixed-precision training stacks (Megatron-LM, PyTorch, NVIDIA tooling/apex) with training and inference optimizations discussed on the model card. The release includes data-preprocessing code, an attribution tool, a PII-redaction pipeline, evaluation harness, and governance materials. The model is released under the BigCode OpenRAIL-M v1 license; certain weights/files are gated behind a license acceptance on Hugging Face. Typical uses include code completion, infilling, program editing, natural-language explanations of code, and building technical-assistant flows (e.g., via a Tech Assistant prompt). Benchmarks reported on the model card/paper include HumanEval, MBPP, DS-1000, and MultiPL-HumanEval (paper reports, for example, ~40% pass@1 on HumanEval under the reported prompting conditions). The model card and paper provide evaluation details, limitations, intended uses, and guidance for attribution and governance.
Key Features
Model size and family
StarCoder family; main released model is ~15.5B parameters with StarCoderBase as the base model.
Context window
Long-context capability commonly described as ≈8,192 tokens (often noted as '8k+').
Architecture and training objective
Built with Megatron-LM, uses multi-query attention and trained with the Fill-in-the-Middle (FIM) objective.
Training data
Trained primarily on The Stack (v1.2), a permissively licensed GitHub code corpus with an opt-out mechanism.
Training scale and fine-tuning
StarCoderBase trained on ~1 trillion tokens; StarCoder is fine-tuned from StarCoderBase with ~35B Python tokens to boost Python performance.
Precision and infra
Trained and optimized using standard mixed-precision tooling (Megatron-LM, PyTorch, NVIDIA tooling/apex); model card discusses training/inference optimizations.
Who Can Use This Tool?
- developers:Use for code completion, infilling, editing, and automated code generation in multiple languages.
- researchers:Evaluate code modeling, long-context transformer techniques, and study code attribution and governance.
- organizations:Integrate into developer tooling and assistants, with attention to licensing, attribution, and safety workflows.
Pricing Plans
Pricing information is not available yet.
Pros & Cons
✓ Pros
- ✓Open-source release with model card, code, and governance materials.
- ✓Large 15.5B model optimized for code tasks and long contexts (~8k).
- ✓Trained on a large permissively licensed code corpus (The Stack) with an opt-out mechanism and attribution tooling.
- ✓Includes supporting artifacts: preprocessing code, PII-redaction pipeline, evaluation harness, and attribution tools.
- ✓Fine-tuned variant optimized for Python performance (additional ~35B Python tokens).
✗ Cons
- ✗Generated code can be buggy, insecure, inefficient, or infringing; output requires human review and testing.
- ✗No guaranteed automated mechanism to detect previously generated content or licensing provenance for every output.
- ✗Some weights/files are gated and require accepting the BigCode OpenRAIL-M license on Hugging Face to access.
- ✗Benchmarks and figures are self-reported on the model card/paper; performance depends on prompts and use-case.
Compare with Alternatives
| Feature | StarCoder | Stable Code | Code Llama |
|---|---|---|---|
| Pricing | N/A | N/A | N/A |
| Rating | 8.7/10 | 8.5/10 | 8.8/10 |
| Model Sizes | 15.5B model | Multiple edge-optimized sizes | Multiple sizes up to large |
| FIM Support | Yes | Yes | Partial |
| Context Window | Long context window | Long context windows | Larger context window |
| Instruction Tuning | No | Yes | Yes |
| Edge Deployment | No | Yes | Yes |
| Multilingual Coverage | Multilingual code support | Multi-language code coverage | Wide code language support |
| Safety & Attribution | Yes | Partial | Yes |