
Overview
Mem0 is described as a "universal memory layer" for LLM applications that compresses and stores conversational memories so applications can preserve context, reduce token usage and latency, and personalize interactions across sessions, users, and agents. Core claims include memory compression to lower tokens and latency, hybrid retrieval combining vector search with an optional graph memory, production observability, and broad framework compatibility via a hosted managed platform and a self-hosted open-source distribution. Key capabilities described in the visited pages include multiple memory storage types (user, agent, session) that are timestamped, versioned, and exportable; memory compression and reranking to reduce prompt size and token costs; retrieval options including vector search (with optional reranker), graph memory (entity/relationship extraction mirrored to graph DBs such as Neo4j, Memgraph, Neptune, Kuzu) to enrich results while keeping vector ranking as primary, and advanced metadata/criteria filters. Mem0 supports multimodal inputs (e.g., images), async memory operations for high-throughput non-blocking writes, custom fact extraction and per-request toggles (for example, toggling graph writes), OpenAI-compatible endpoints for migration/self-hosting, and REST API plus SDKs (Python and JavaScript) with integration cookbooks and demos. Deployment options include a fully managed hosted Mem0 Platform and a self-hosted Mem0 OSS distribution suitable for on-prem, private cloud, Kubernetes, or air-gapped deployments; graph and vector stores can be self-managed or hosted (docs reference Neo4j Aura in a quickstart). Security and governance items called out in the docs and marketing include SOC 2, GDPR compliance, audit logs, workspace governance, HIPAA and BYOK mentioned as enterprise options, and traceability features (timestamped/versioned/exportable memories, audit logs, tracing for TTL/size/access). Pricing tiers listed on the pricing page include a Hobby free tier, Starter ($19/month), Pro ($249/month), and Enterprise flexible pricing; an alternative usage-based option is referenced for some customers. The site also advertises a Startup Program offering qualifying startups 3 months of Pro free. Benchmark claims on the homepage assert improvements versus OpenAI memory (the site cites statements such as "~26% higher response quality" and "~90% fewer tokens" in benchmarking claims); these are vendor claims and the docs note that such benchmark statements should be independently verified if needed. Integrations and ecosystem items referenced include LangGraph, CrewAI, LlamaIndex, Vercel AI SDK, Python and JavaScript SDKs, and multiple demos/cookbooks with demo code published to GitHub (docs reference a Mem0 demo GitHub repo). The docs include quickstarts, cookbooks, an open-source repo and contribution docs, and API reference and platform overview pages for CRUD and search endpoints. Known notes/caveats from the extraction: pricing page content is duplicated in multiple places on the site (an automated extraction encountered a validation error due to many features listed in a single plan), and homepage benchmark claims are vendor statements that should be verified externally.
Key Features
Memory storage types
User, agent, and session memories that are timestamped, versioned, exportable, and support per-request toggles.
Memory compression and reranking
Compression and reranking to reduce prompt size and lower token costs and latency.
Hybrid retrieval (vectors + graph)
Vector search with optional reranker, plus Graph Memory that mirrors entities/relationships to a graph DB to enrich results.
Graph Memory
Writes extracted entities/relationships into a graph DB (Neo4j, Memgraph, Neptune, Kuzu) while embeddings remain in vector store; graph augments vector results.
Multimodal support
Supports images and other media processing into memories for multimodal applications.
Async operations and customization
Async non-blocking writes for high throughput and custom fact extraction, memory updates, and feature toggles per request.
Who Can Use This Tool?
- LLM developers:Integrate scalable memory management, reduce token costs, and enable session continuity across agents and users.
- Startups:Prototype and scale conversational products using free/higher-tier startup program and SDK quickstarts.
- Enterprises:Deploy with governance, audit logs, and enterprise options including on-prem and BYOK for compliance.
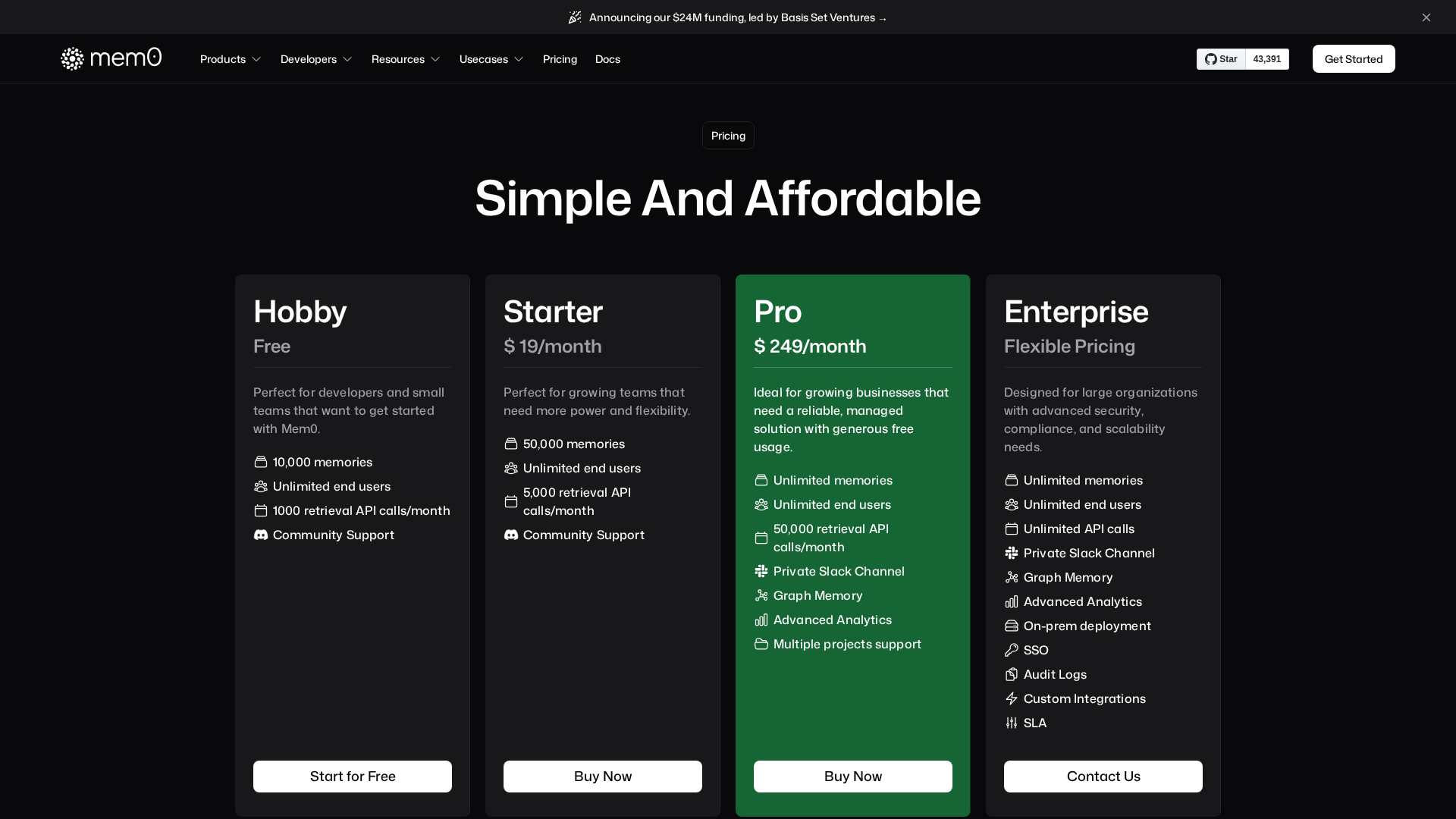
Pricing Plans
Free tier for hobby projects with limited quotas.
- ✓10,000 memories
- ✓Unlimited end users
- ✓1,000 retrieval API calls/month
- ✓Community support
Entry paid tier with increased quotas and API calls.
- ✓50,000 memories
- ✓5,000 retrieval calls/month
- ✓Increased memory quota vs Free
Pro tier for production usage with advanced features and larger quotas.
- ✓Unlimited memories & end users
- ✓50,000 retrieval calls/month
- ✓Private Slack channel
- ✓Graph Memory
- ✓Advanced analytics
- ✓Multiple projects
Flexible enterprise pricing with advanced controls and on-prem options.
- ✓Unlimited memories and users
- ✓Unlimited API calls (flexible)
- ✓Private Slack and direct support
- ✓Graph Memory and advanced analytics
- ✓On-prem deployment options
- ✓SSO, audit logs, custom integrations, SLA
Qualifying startups receive 3 months of Pro free via a quick application process.
- ✓3 months free Pro access for qualifying startups
- ✓Priority support and direct collaboration
Pros & Cons
✓ Pros
- ✓Memory compression and reranking to lower token costs and latency
- ✓Hybrid retrieval: vector search plus optional Graph Memory for richer results
- ✓Hosted managed platform plus self-hosted open-source distribution for flexible deployments
- ✓REST API, Python and JavaScript SDKs, quickstarts, and cookbooks for developer onboarding
- ✓Enterprise controls and traceability (SOC 2, GDPR mentions, audit logs, versioned memories)
✗ Cons
- ✗Homepage benchmark claims are vendor-provided and should be independently verified
- ✗Pricing page content is duplicated across the site and caused automated extraction validation issues
- ✗Some enterprise compliance statements (e.g., HIPAA, BYOK) are referenced as options and should be validated with Mem0 sales
Compare with Alternatives
| Feature | Mem0 | Cohere | Personal AI |
|---|---|---|---|
| Pricing | $19/month | N/A | N/A |
| Rating | 8.3/10 | 8.8/10 | 8.1/10 |
| Memory Architecture | Graph and vector compressed memory | Embeddings and retrieval architecture | Personal memory stack and SLM |
| Hybrid Retrieval | Yes | Partial | Partial |
| Compression & Rerank | Yes | Partial | Partial |
| Multimodal Support | Yes | No | No |
| Deployment Flexibility | Self-hosted and cloud options | Private and on-prem enterprise options | Enterprise cloud deployments |
| API/SDK Surface | REST API and SDKs | APIs and SDKs for developers | Developer APIs and training studio |
| Observability & Hooks | Observability and async hooks | Enterprise tooling and monitoring | Security-focused controls and docs |
Related Articles (5)
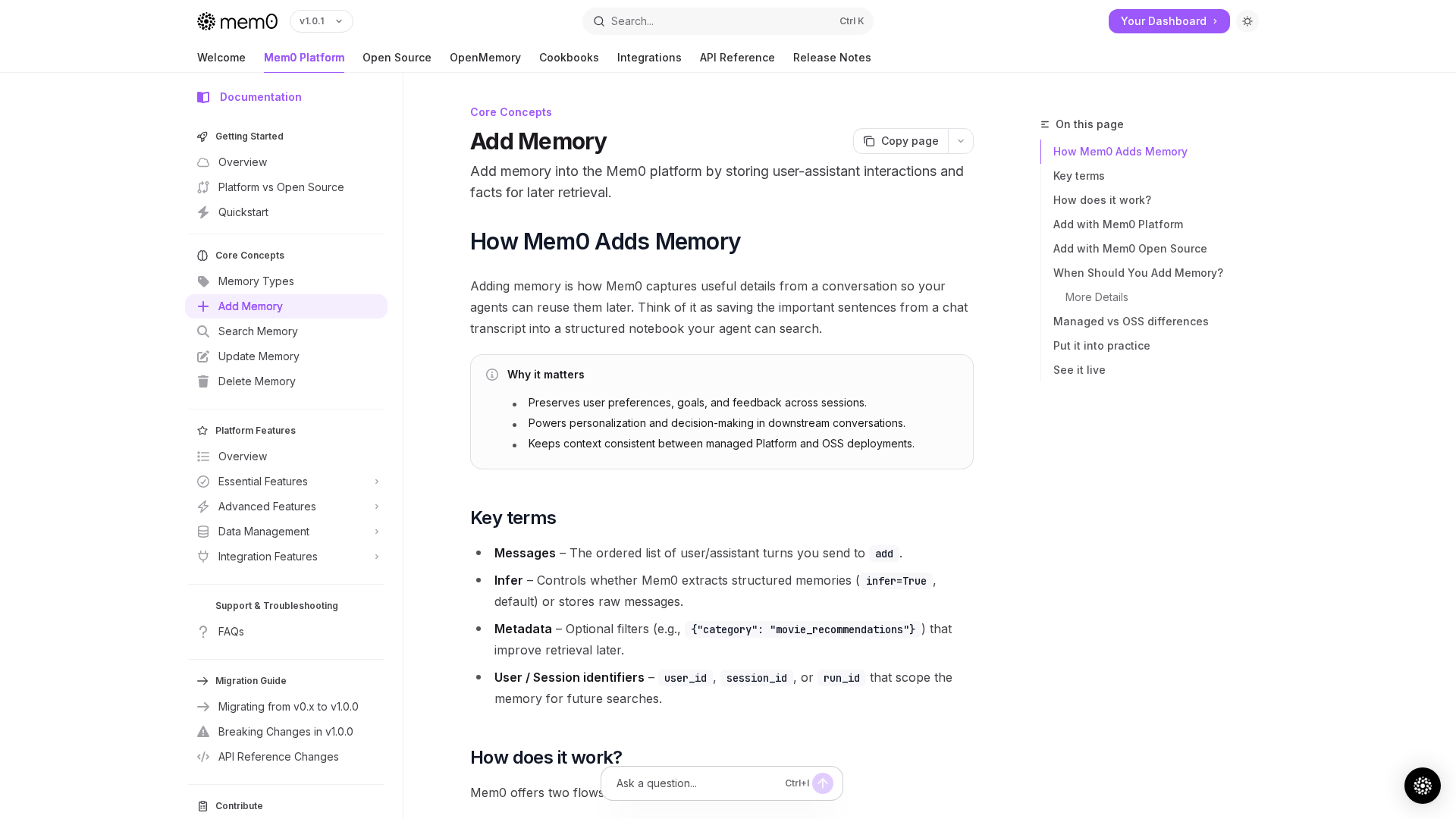
Learn how Mem0 captures, stores, and retrieves key memories from conversations to personalize and streamline future interactions.
Mem0 raises $24M to become the default memory layer for AI agents, enabling persistent memory with three lines of code.
Mem0 is a universal memory layer for LLM apps that reduces token costs, personalizes experiences, and scales securely across deployments.
Mem0's OpenMemory auto-captures coding memories and delivers project-scoped memories to AI agents for on-context coding.

Mem0's Graph Memory creates a network of memory relationships to enhance contextually relevant AI search results.