Overview
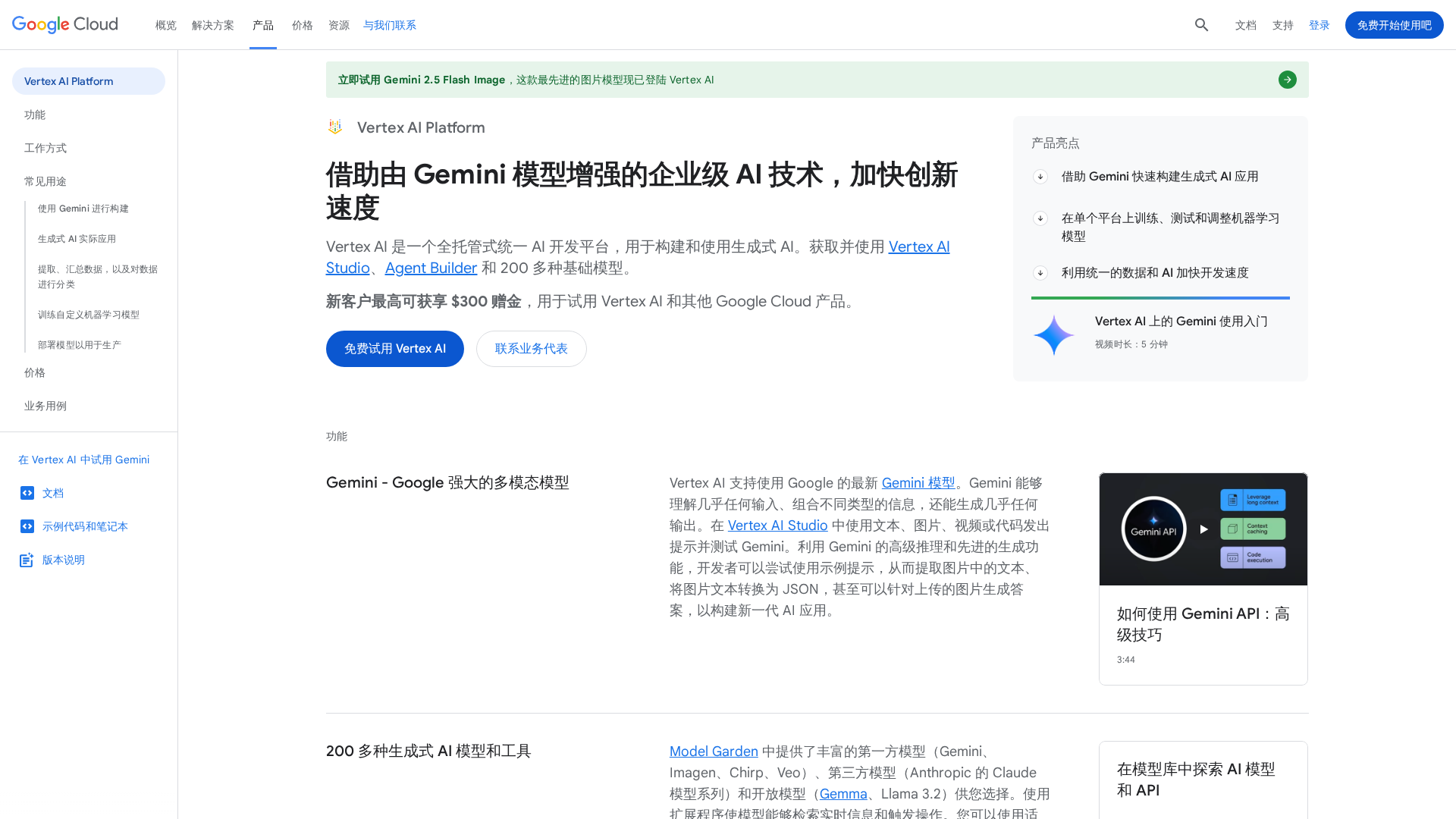
Vertex AI is Google Cloud’s end-to-end, fully managed machine learning and generative AI platform. It unifies tools for model discovery (Model Garden), training, fine-tuning, evaluation, deployment (online/batch prediction), MLOps (pipelines, model registry, monitoring), and low-code/no-code agent creation (Agent Builder). Vertex AI provides first-party and third-party models (including Gemini and Imagen), supports custom training with a wide range of VM and accelerator types, integrates with BigQuery, Cloud Storage, and Notebooks, and offers vector search, feature store, and evaluation services to support production ML workflows and enterprise use cases.
Key Features
Model Garden
Discover, test, and deploy first- and third-party models including Gemini and Imagen; supports model evaluation and fine-tuning.
Vertex AI Studio
Web UI for prototyping, testing, and deploying multimodal models and for interacting with Gemini-style models.
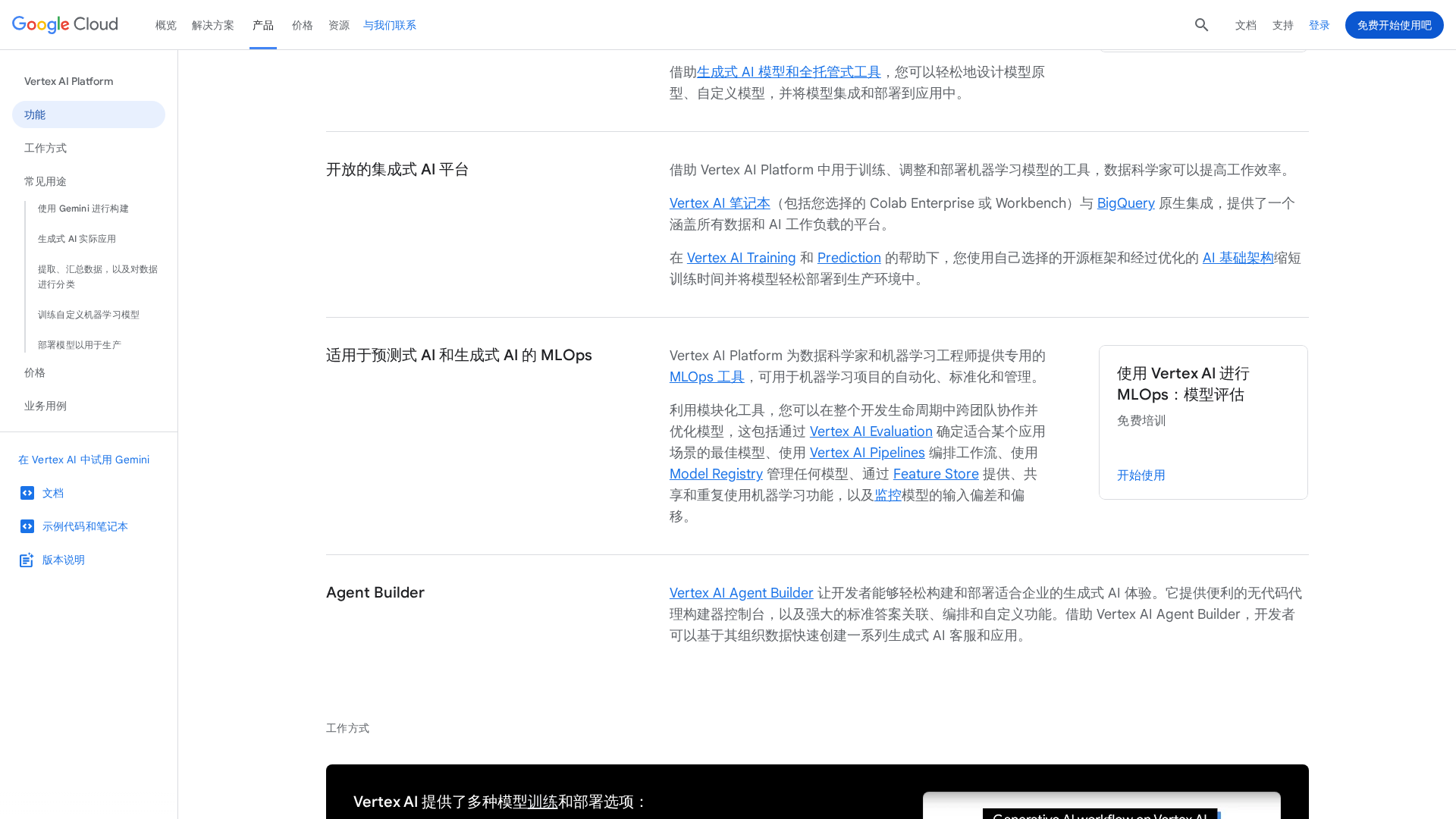
Agent Builder / Agent Engine
Low-code/no-code tools to build conversational agents and runtime for agent execution with free tier quotas.
MLOps Suite
Pipelines, Model Registry, Feature Store, Model Monitoring, and Evaluation tools to orchestrate and monitor model lifecycles.
Training & Inference Infrastructure
Flexible training and prediction options across many VM families, GPUs, TPUs, Ray clusters, and NAS; supports online and batch prediction.
Vector Search & Feature Store
Built-in vector search (indexing/storage/queries) and feature storage for production ML feature serving.
Who Can Use This Tool?
- Developers:Build, prototype, and deploy apps using managed ML models and Vertex AI Studio.
- ML Engineers:Train, tune, and deploy scalable models with MLOps pipelines and monitoring.
- Data Scientists:Experiment with AutoML, custom models, and Model Garden models for insights.
- Enterprises:Operationalize ML workflows with enterprise-grade monitoring, governance, and support.
Pricing Plans
Image classification training billed per training hour.
- ✓Training: US$3.465 per 1 hour (classification)
- ✓Predefined machine configs used
- ✓Pay only for actual compute hours
Object detection training billed per training hour.
- ✓Training: US$3.465 per 1 hour (object detection)
- ✓Predefined machine configs used
- ✓Pay only for actual compute hours
Edge-device model training billed per hour.
- ✓Edge-device training: US$18.00 per 1 hour
- ✓Optimized for on-device models
- ✓Billed per training hour
Deployed model hourly price for online predictions.
- ✓Deployment & online prediction: US$1.375 per 1 hour (classification)
- ✓Pay per endpoint node hour
- ✓Must deploy model to serve online predictions
Deployed object detection model hourly price for online predictions.
- ✓Deployment & online prediction: US$2.002 per 1 hour (object detection)
- ✓Pay per endpoint node hour
- ✓Must deploy model to serve online predictions
Batch prediction billed per node hour for image models.
- ✓Batch prediction: US$2.222 per 1 hour
- ✓Billed per prediction node hour
- ✓Used for large offline prediction jobs
AutoML Tables training charged per node-hour used.
- ✓Training: US$21.252 per 1 hour (per node)
- ✓Predefined machine node pricing
- ✓Pay only for actual node hours
Batch prediction uses 40 n1-highmem-8 machines (infrastructure note).
- ✓Batch prediction uses 40 n1-highmem-8 machines
- ✓Prediction cost based on used machines and hours
- ✓No single fixed per-node price listed
Tiered monthly pricing per 1,000 predicted counts.
- ✓0–1,000,000 count: US$0.20 per 1,000 count per month
- ✓1,000,000–50,000,000 count: US$0.10 per 1,000 count per month
- ✓50,000,000+ count: US$0.02 per 1,000 count per month
Forecast AutoML training charged per training hour.
- ✓Training: US$21.252 per 1 hour
- ✓Billed per training node hour
- ✓Pay only for actual training compute time
ARIMA+ predictions charged per 1,000 counts.
- ✓Prediction: US$5.00 per 1,000 count
- ✓Training: (not specified in table)
- ✓Time-series specific pricing
Compute-based metrics billed per 1,000 characters input/output.
- ✓Input: US$0.00003 per 1,000 input characters
- ✓Output: US$0.00009 per 1,000 output characters
- ✓Uses default auto scorer model Gemini 2.0 Flash
Older-model metrics charged per 1,000 characters.
- ✓Input: US$0.005 per 1,000 input characters
- ✓Output: US$0.015 per 1,000 output characters
- ✓Used for metrics based on older evaluation models
Monthly free quota for vCPU and RAM for Agent Engine runtime.
- ✓vCPU: first 180,000 vCPU-seconds free per month
- ✓RAM: first 360,000 GiB-seconds free per month
- ✓Helpful for trial and small workloads
vCPU billed per 3,600-second block above free tier.
- ✓0–50 hours equivalent per month: free
- ✓50 hour and above: US$0.0994 per 3,600 seconds (≈US$0.0994/hour)
- ✓Billed per project monthly
RAM billed per 3,600 gibibyte-seconds above free tier.
- ✓0–100 GiB-hour per month: free
- ✓100 GiB-hour and above: US$0.0105 per 3,600 gibibyte-seconds (≈US$0.0105/GiB-hour)
- ✓Billed per project monthly
Custom training VM price per hour for n1-standard-4.
- ✓n1-standard-4: US$0.21849885 per 1 hour
- ✓Use Compute Engine machine types
- ✓Accelerators charged separately if attached
Custom training VM price per hour for n1-standard-64.
- ✓n1-standard-64: US$3.4959816 per 1 hour
- ✓High vCPU/memory configuration
- ✓Pay per VM hour
A2 GPU VM price per hour (includes required GPUs).
- ✓a2-highgpu-8g: US$35.401991315 per 1 hour
- ✓Price includes fixed GPU cost for that instance type
- ✓Accelerator pricing embedded in instance
GPU accelerator price per hour (A100) plus management fee.
- ✓NVIDIA_TESLA_A100: US$2.933908 per 1 hour
- ✓Vertex management fee: US$0.4400862 per 1 hour
- ✓Combine with Compute Engine VM pricing
H100 80GB accelerator price per hour with management fee.
- ✓NVIDIA_H100_80GB: US$9.79655057 per 1 hour
- ✓Vertex management fee: US$1.4694826 per 1 hour
- ✓High-end GPU for training
Standard persistent disk billed per GiB-hour.
- ✓pd-standard: US$0.000063014 per 1 GiB-hour
- ✓Billed hourly by provisioned GiB
- ✓First 100 GiB per VM typically free (context-dependent)
SSD persistent disk billed per GiB-hour.
- ✓pd-ssd: US$0.000267808 per 1 GiB-hour
- ✓Higher performance than pd-standard
- ✓Billed hourly by provisioned GiB
Online/batch prediction node hour price for e2-standard-4.
- ✓e2-standard-4: US$0.1541128 per 1 hour
- ✓Billed per node hour for online or batch predictions
- ✓Spot and reserved options supported
N1 prediction node hour price for n1-standard-4.
- ✓n1-standard-4: US$0.219 per 1 hour
- ✓Used for online/batch prediction node pricing
- ✓Pay per node hour
N2 prediction node hour price for n2-standard-4.
- ✓n2-standard-4: US$0.2233708 per 1 hour
- ✓Used for online/batch prediction node pricing
- ✓Pay per node hour
A2 GPU prediction node hourly price (includes GPU cost).
- ✓a2-highgpu-1g: US$4.2244949 per 1 hour
- ✓Instance includes fixed GPU cost
- ✓Suitable for GPU-accelerated predictions
Optional GPUs for prediction charged per GPU-hour.
- ✓NVIDIA_TESLA_P4: US$0.69 per 1 hour
- ✓NVIDIA_TESLA_P100: US$1.679 per 1 hour
- ✓NVIDIA_TESLA_T4: US$0.402 per 1 hour; V100: US$2.852 per 1 hour
TPU v5e pricing per TPU type per hour.
- ✓ct5lp-hightpu-1t: US$1.38 per 1 hour
- ✓ct5lp-hightpu-4t: US$5.52 per 1 hour
- ✓ct5lp-hightpu-8t: US$5.52 per 1 hour (as listed)
Ray on Vertex AI training VM pricing per hour (example).
- ✓n1-standard-4: US$0.2279988 per 1 hour (Ray on Vertex)
- ✓Accelerators charged separately
- ✓Billed per VM hour for Ray clusters
NAS hourly machine price example for n1-standard-4.
- ✓n1-standard-4: US$0.2849985 per 1 hour (NAS)
- ✓Predefined and custom configs supported
- ✓Billed per VM hour for NAS jobs
NAS accelerator A100 hourly price (example).
- ✓NVIDIA_TESLA_A100: US$4.400862 per 1 hour (NAS listed GPU pricing)
- ✓Attachable to NAS VMs
- ✓Billed per accelerator hour
Pros & Cons
✓ Pros
- ✓Fully managed end-to-end ML platform (training, tuning, deployment, monitoring).
- ✓Native access to Google’s first-party models (Gemini, Imagen) via Model Garden.
- ✓Rich MLOps features: Pipelines, Model Registry, Monitoring, Evaluation, Feature Store.
- ✓Broad infrastructure choices (many VM types, GPUs, TPUs, Ray integration).
- ✓Generous free tiers and integration with Google Cloud $300 trial credits.
✗ Cons
- ✗Usage-based pricing can be complex to predict for large, variable workloads.
- ✗Many separate SKUs (compute, accelerators, disk, agent runtime) complicate billing.
- ✗Some targeted docs/pages (features overview) may surface 404s or vary by locale.
- ✗Enterprise features and committed-use discounts require contacting sales.
Compare with Alternatives
| Feature | Vertex AI | Google Gemini | Together AI |
|---|---|---|---|
| Pricing | N/A | N/A | N/A |
| Rating | 8.8/10 | 9.0/10 | 8.4/10 |
| Model Ecosystem | Yes | Yes | Yes |
| Multimodal Support | Yes | Yes | No |
| Agent Builder | Yes | Partial | No |
| Fine-tune Control | Yes | Partial | Yes |
| Deployment Flexibility | Yes | Partial | Yes |
| MLOps Tooling | Yes | Partial | Partial |
| Inference Scalability | Yes | Partial | Yes |
| Vector Search | Yes | Partial | Partial |
Related Articles (8)
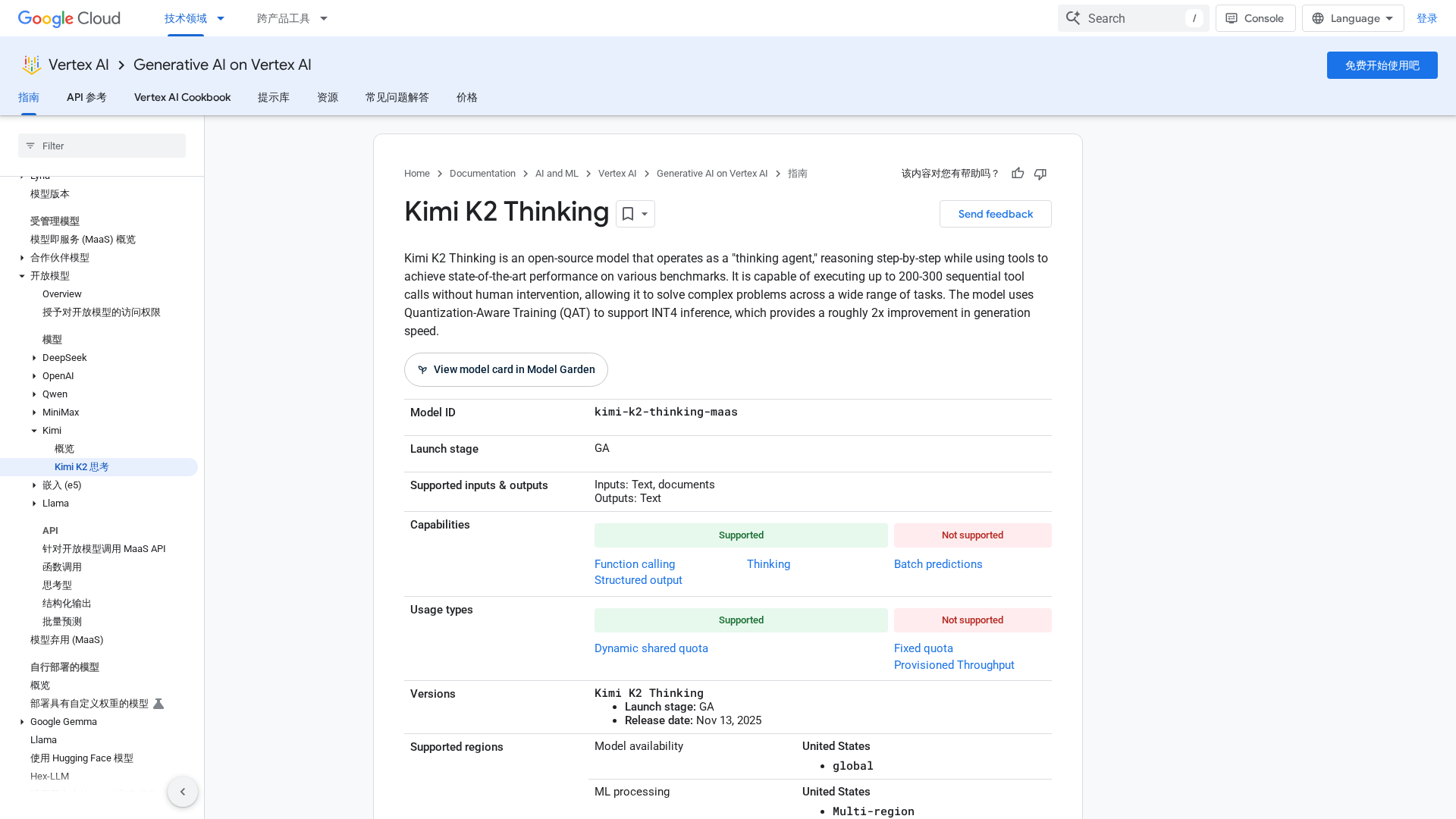
An open-source thinking agent on Vertex AI that performs long chain-of-thought reasoning with autonomous tool use and INT4-accelerated inference.
A 2025 guide comparing the top AEO tools to track, optimize, and secure AI citations.
Overview of Vertex AI's training options—AutoML, custom training, and Ray on Vertex AI—with guidance to choose the right path.
A16z’s 5th edition analyzes the Top 100 Gen AI apps, noting ecosystem stabilization, Google’s new entrants, Brink List shifts, and the rise of vibe coding.

Editorial overview of ambient AI scribes in healthcare, weighing transformative potential against accuracy, ethics, and implementation challenges.