Topic Overview
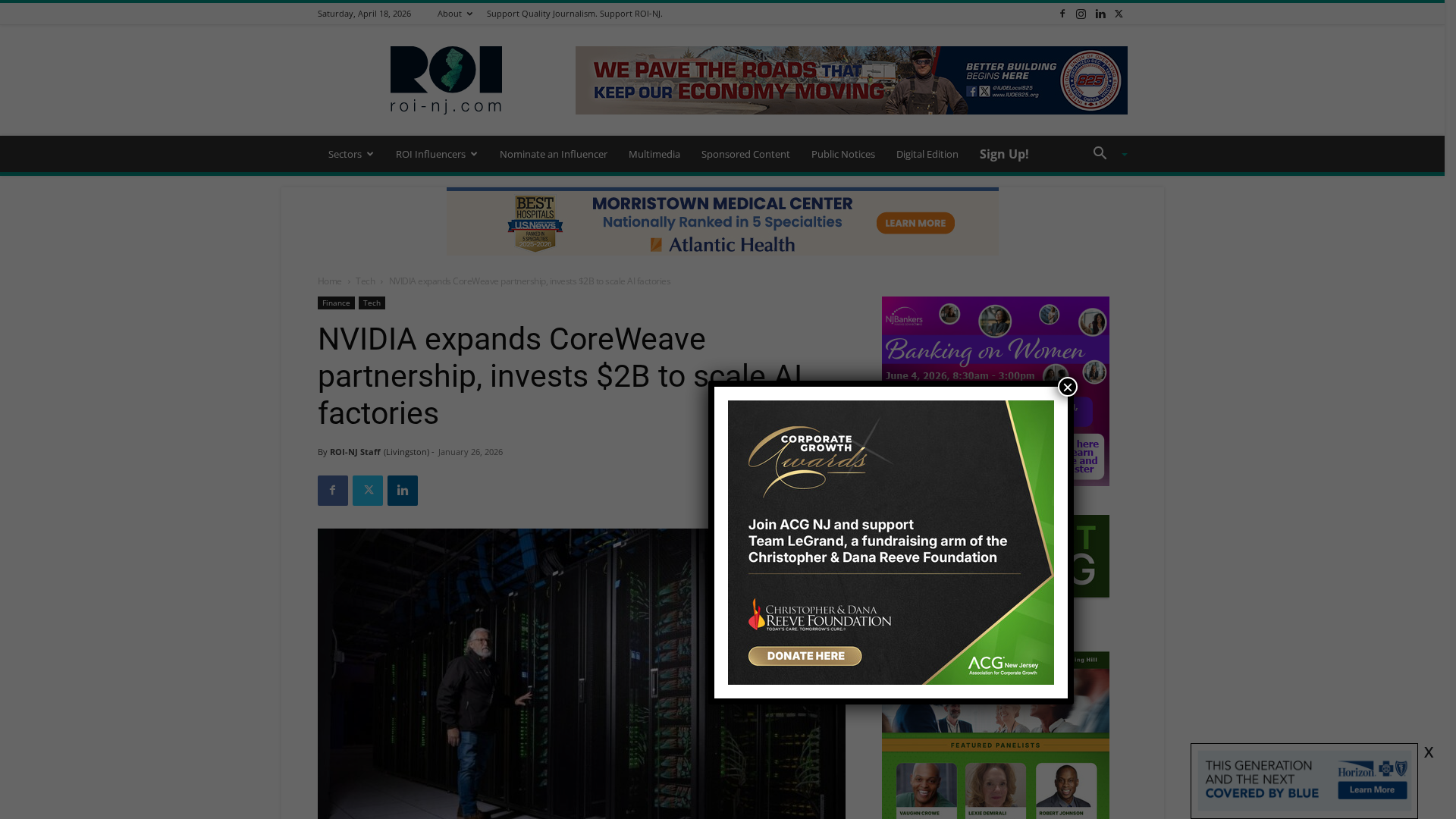
This topic covers the infrastructure and service landscape for AI inference in 2026: cloud GPU providers (CoreWeave, AWS and others), specialized accelerators (NVIDIA data‑center GPUs and newer third‑generation inference chips such as Groq‑3), and on‑prem server deployments — plus the software integrations that bind models to storage, streaming and operational tooling. Demand for low‑latency, high‑throughput inference and tighter cost control has pushed organizations toward hybrid architectures that mix public‑cloud GPU capacity, colocated GPU clouds and on‑prem racks. Investment activity in dedicated GPU clouds has accelerated capacity growth and competition, while new accelerator architectures are reshaping performance and software stacks. Practical orchestration and safety around these infrastructures increasingly rely on standardized integrations. The Model Context Protocol (MCP) ecosystem provides concrete examples: an AWS MCP server exposes S3 and DynamoDB operations so LLMs can manage cloud resources; a Pinecone MCP server connects assistants to vector search projects and docs; a Cloud Run MCP server enables agent-driven deployments; a Confluent MCP server links agents to Kafka and Confluent Cloud APIs; and production-ready components like mcp-memory-service provide hybrid, lock‑free semantic memory with local fast reads and cloud sync. Together these tools illustrate how inference platforms are no longer only about raw GPUs — they are about connecting models to data pipelines, memory stores, streaming systems and deployment endpoints. As of 2026-04-18, teams evaluating inference infrastructure should weigh hardware choice (cost, latency, software support), hybrid cloud vs on‑prem tradeoffs, and the maturity of integration layers (MCP and vector/memory services) that enable secure, observable and cost‑efficient model operations.
MCP Server Rankings – Top 5

Perform operations on your AWS resources using an LLM.

MCP server that connects AI tools with Pinecone projects and documentation.

Deploy code to Google Cloud Run

Interact with Confluent Kafka and Confluent Cloud REST APIs.

Production-ready MCP memory service with zero locks, hybrid backend, and semantic memory search.