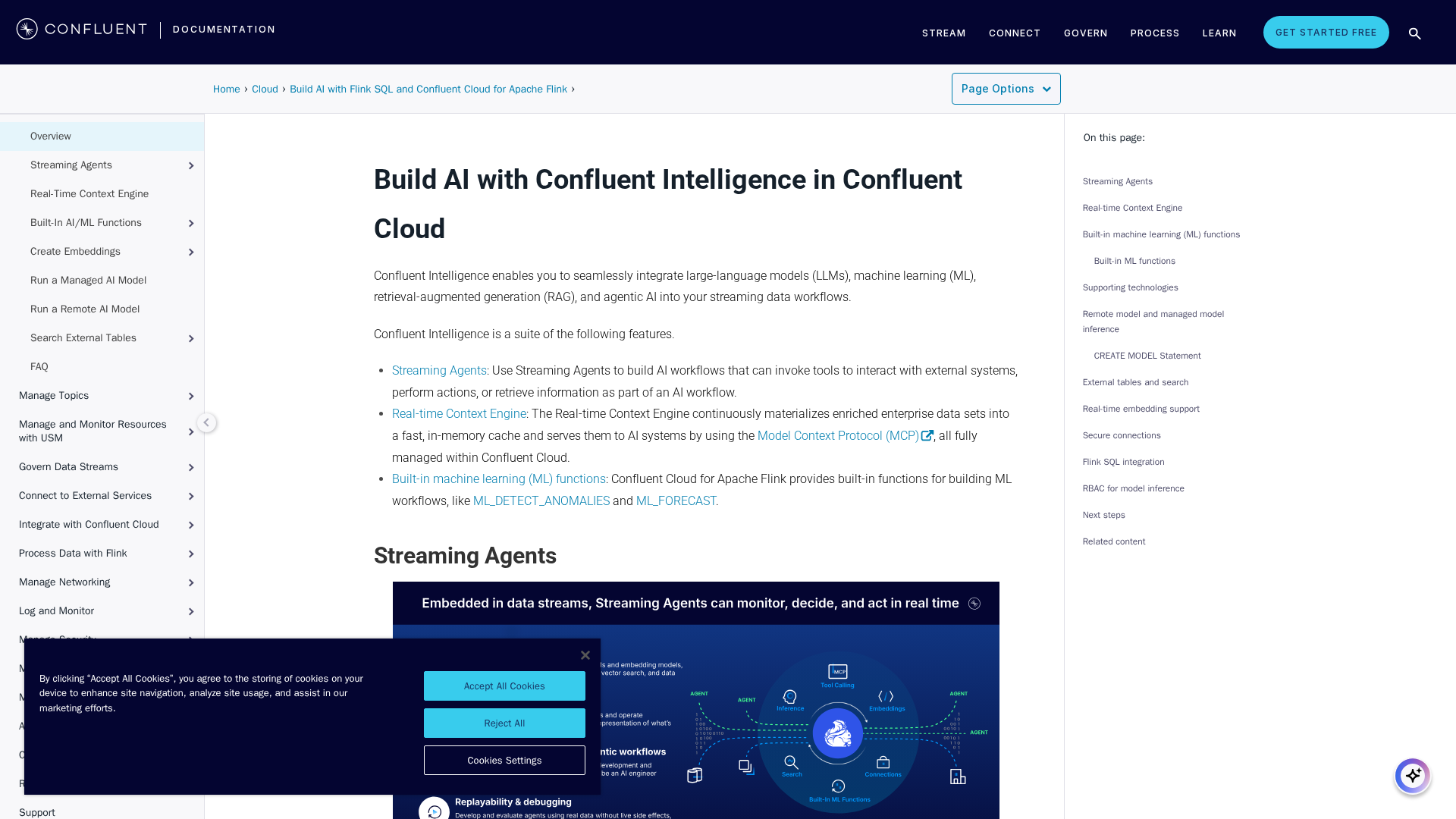
Topic Overview
This topic covers the infrastructure and partner ecosystem that organizations use to run scalable AI inference: hardware vendors (notably NVIDIA), cloud platforms (Google Cloud and AWS), and connector/adapter projects that bridge models to services via standards such as the Model Context Protocol (MCP). As production LLM and embedding usage grows, teams need predictable latency, cost controls, and operational integrations that span GPUs, serverless execution, vector stores and streaming systems. NVIDIA remains central to inference stacks through optimized GPUs, runtimes (e.g., inference engines and orchestration tools) and certification partnerships with cloud providers. Cloud platforms provide managed deployment patterns: Google Cloud Run for serverless containerized inference, and AWS integrations that expose resource operations to LLM-driven workflows. Complementary MCP servers and adapters — exemplified in this collection — connect AI tools to services like Pinecone (vector DBs), Confluent (Kafka/streaming), Neon (serverless Postgres), and Grafbase (GraphQL gateways), enabling assistants and agents to query state, persist embeddings, and call APIs with a common protocol. The combined trend is toward modular, interoperable stacks: specialized inference hardware or managed instances for high-throughput models, serverless endpoints for bursty workloads, and standardized connectors (MCP) to reduce bespoke integration work. For teams evaluating options, key considerations are latency SLAs, model lifecycle and versioning, cost per query, data locality and compliance, and ecosystem fit for streaming or vector data. This topic synthesizes vendor roles and open connector projects to help practitioners compare approaches for deploying reliable, scalable inference without prescriptive claims about any single provider.
MCP Server Rankings – Top 6

Deploy code to Google Cloud Run

Perform operations on your AWS resources using an LLM.

MCP server that connects AI tools with Pinecone projects and documentation.

Interact with Confluent Kafka and Confluent Cloud REST APIs.

Interact with the Neon serverless Postgres platform

Turn your GraphQL API into an efficient MCP server with schema intelligence in a single command.