Topic Overview
This topic surveys the current landscape of AI audio and voice models for developers, covering text-to-speech (TTS), speech-to-text, voice cloning, real-time voice agents, and conversation-intelligence tooling. In 2026 these capabilities are increasingly production-ready: low-latency, expressive TTS and high-fidelity cloning are used in customer agents and media workflows, while lightweight browser and on-device transcription support privacy-sensitive applications. Key categories and representative tools: Voice Synthesis and Transcription (ElevenLabs for ultra-realistic TTS, cloning, and transcription; Transcribe Audio for quick in-browser STT); Text-to-Speech Tools (Murf AI and Smallest.ai for multilingual, studio-grade TTS, dubbing, and emotion control); Real-time/Agent Frameworks (Voila as an open-source, low-latency family of voice-language models for persona-aware conversations); and Conversation Intelligence / Audio Quality (Krisp for noise cancellation, meeting transcription, and audio enhancement). Also relevant are audio asset marketplaces that surface licensed voices and sound assets for reuse and localization. Why it matters now: developers are balancing fidelity, latency, cost, and legal/ethical constraints—voice consent, licensing, and on-device inference are major design drivers. Platform incumbents (OpenAI, Apple, and specialist providers) influence API ergonomics and privacy defaults; specialist vendors focus on production-grade pipelines, multilingual dubbing, or ultra-low-latency interaction. Choosing the right stack depends on use case: media dubbing and voiceovers prioritize fidelity and licensing, voice agents need low latency and conversational state, and enterprise meetings require robust noise reduction and transcription. This comparison helps developers map requirements to the trade-offs and vendor capabilities available in early 2026.
Tool Rankings – Top 6
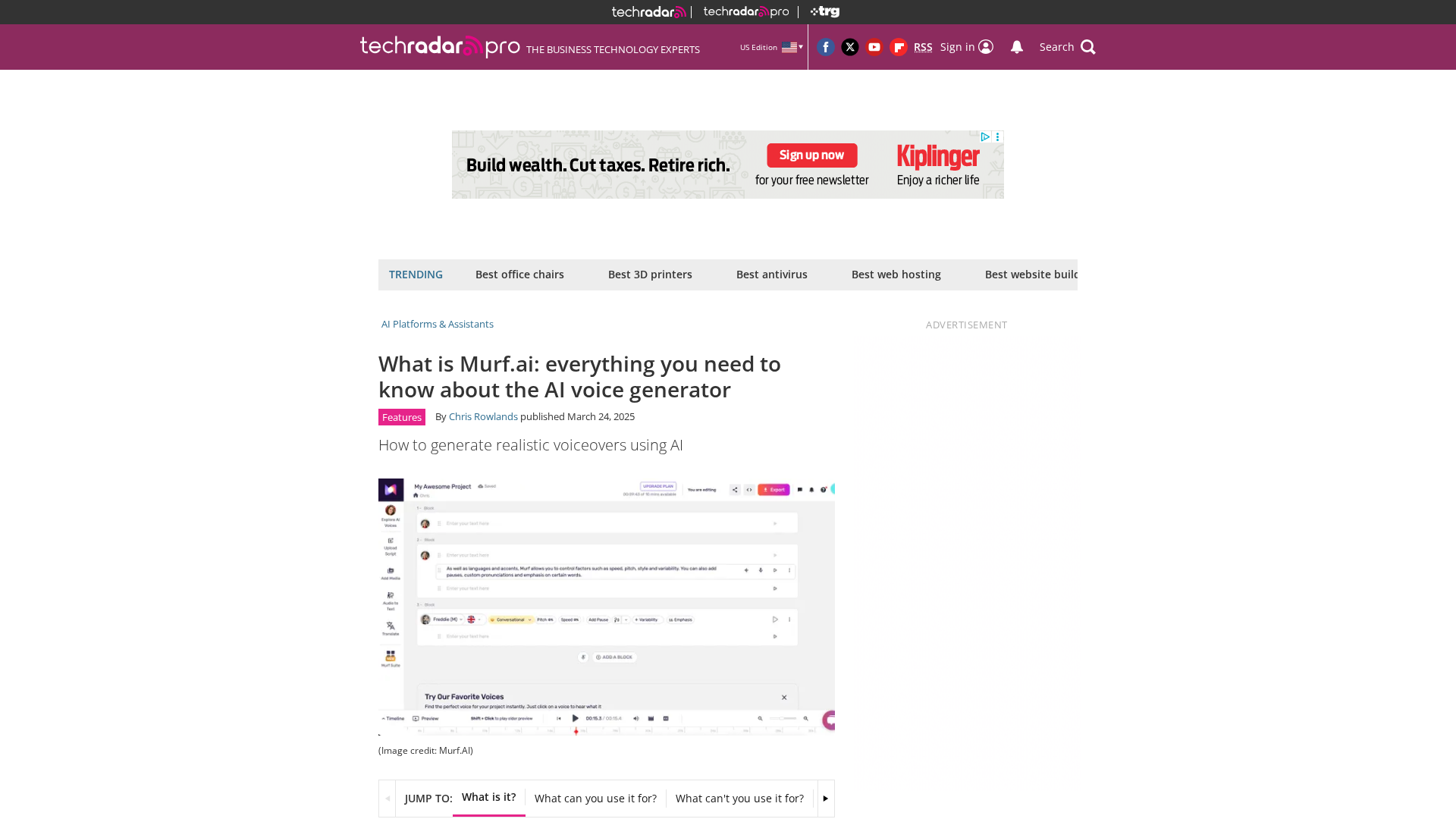
Industry-leading AI audio platform for ultra-realistic text-to-speech, voice cloning, transcription, and voice agents.

Realistic AI text-to-speech, dubbing, and voice APIs with 200+ voices and multilingual support.

Time speech transcription
AI audio/meeting platform for noise cancellation, real-time transcription, meeting notes, accent conversion, and voice/音

Open-source AI for real-time, expressive voice role-play
Hyper-realistic AI voiceovers
Latest Articles (19)
Ultra-fast, on-premise AI voice agents delivering secure, scalable enterprise speech solutions with rapid latency.
Real-time, full-duplex multimodal voice AI for enterprise contact centers with sub-300ms responses.

ElevenLabs launches a worldwide hackathon with MBZUAI's Abu Dhabi chapter to prototype conversational agents for prize winnings.
Freya raises $3.5M to scale AI voice agents for call centers, backed by Y Combinator and DOMiNO Ventures.
Stream Vision Agents now use ElevenLabs TTS for real-time, lifelike voices, delivering 10x faster voice setup and low-latency multimodal AI.