Topic Overview
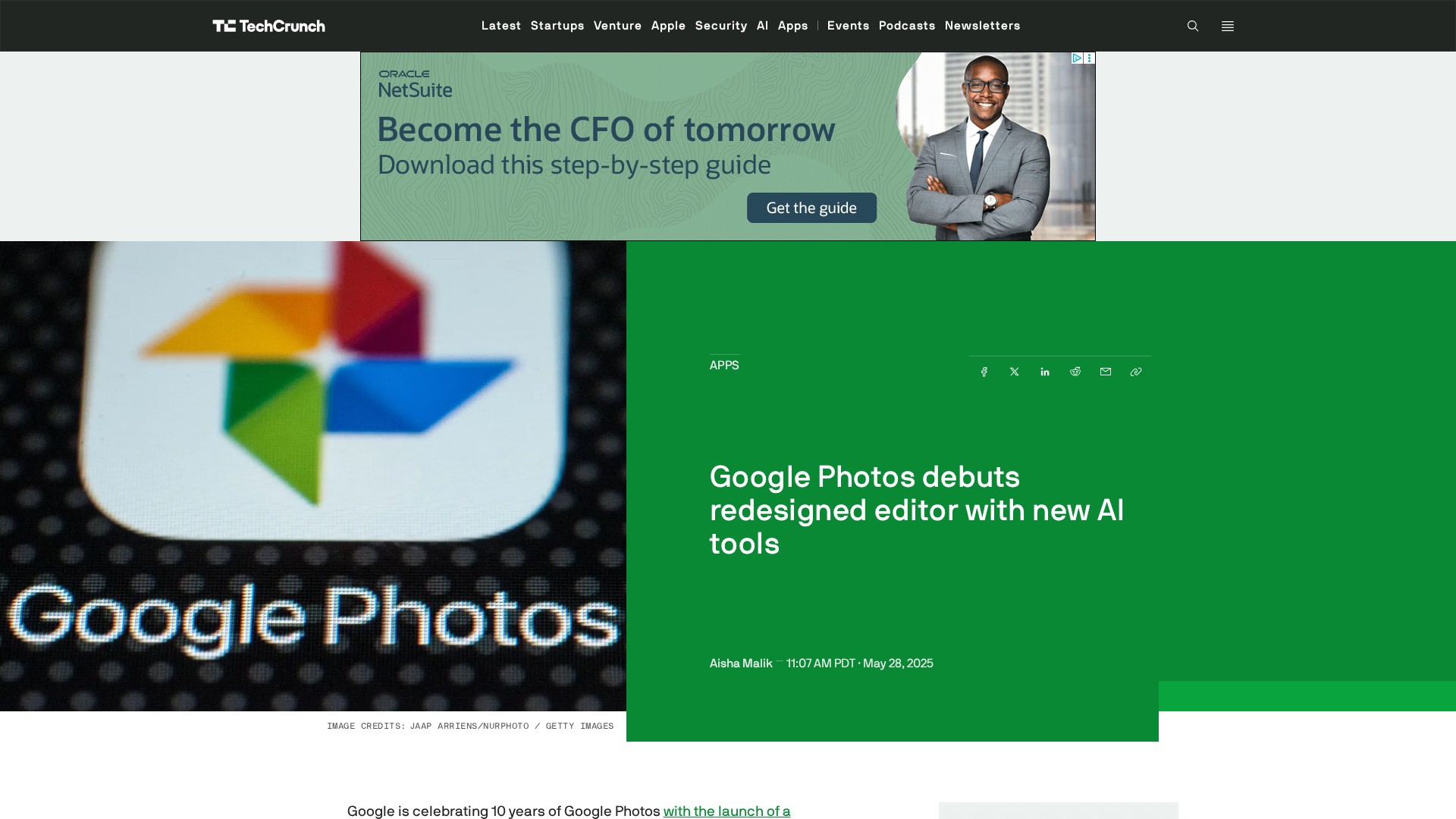
Multimodal vision+text AI combines image understanding and natural-language capabilities so systems can search, describe, edit and generate visual content alongside text. By 2026 these models are being deployed across consumer apps, creative studios and enterprise workflows: consumer-facing features in Google Photos accelerate visual search, automatic edits and organization; generative models such as Google Gemini and GPT-family multimodal variants enable image-aware conversational assistants and API-driven asset creation; Adobe Firefly-style tools supply on-demand creative imagery and style-consistent variations. Relevant categories intersect: Edge AI Vision Platforms push inference on-device for lower latency and privacy-sensitive use cases; Marketing Attribution Tools exploit visual signals (product images, UGC, video frames) combined with multimodal analytics to link creative variations to conversions; Generative AI Resources supply models, APIs and creative toolchains used by designers and marketers. Practical tool examples include Google Gemini (multimodal model family and developer APIs), Anthropic’s Claude family (conversational multimodal assistants), remove.bg (automated background removal for image pipelines), PDF.ai (conversational access to document content) and PolyAI (voice-first agents that can incorporate multimodal context). Adoption considerations include compute and latency tradeoffs (cloud vs edge), data governance and privacy when indexing user images, and model capabilities/limitations for fine-grained visual reasoning. For practitioners, the current trend is toward hybrid stacks: cloud-hosted multimodal models for heavy generation and analytics, plus edge vision for real-time inference and privacy. Integrating these capabilities into marketing and creative workflows requires attention to tooling (APIs, asset pipelines, attribution measurement) and to evaluation of robustness, bias and compliance across visual and textual modalities.
Tool Rankings – Top 5
Google’s multimodal family of generative AI models and APIs for developers and enterprises.
Anthropic's Claude family: conversational and developer AI assistants for research, writing, code, and analysis.
Chat with your PDFs using AI to get instant answers, summaries, and key insights.
AI-powered single-click background removal and replacement for images (transparent PNGs, bulk workflows, API).
Voice-first conversational AI for enterprise contact centers, delivering lifelike multilingual agents across voice, chat
Latest Articles (56)
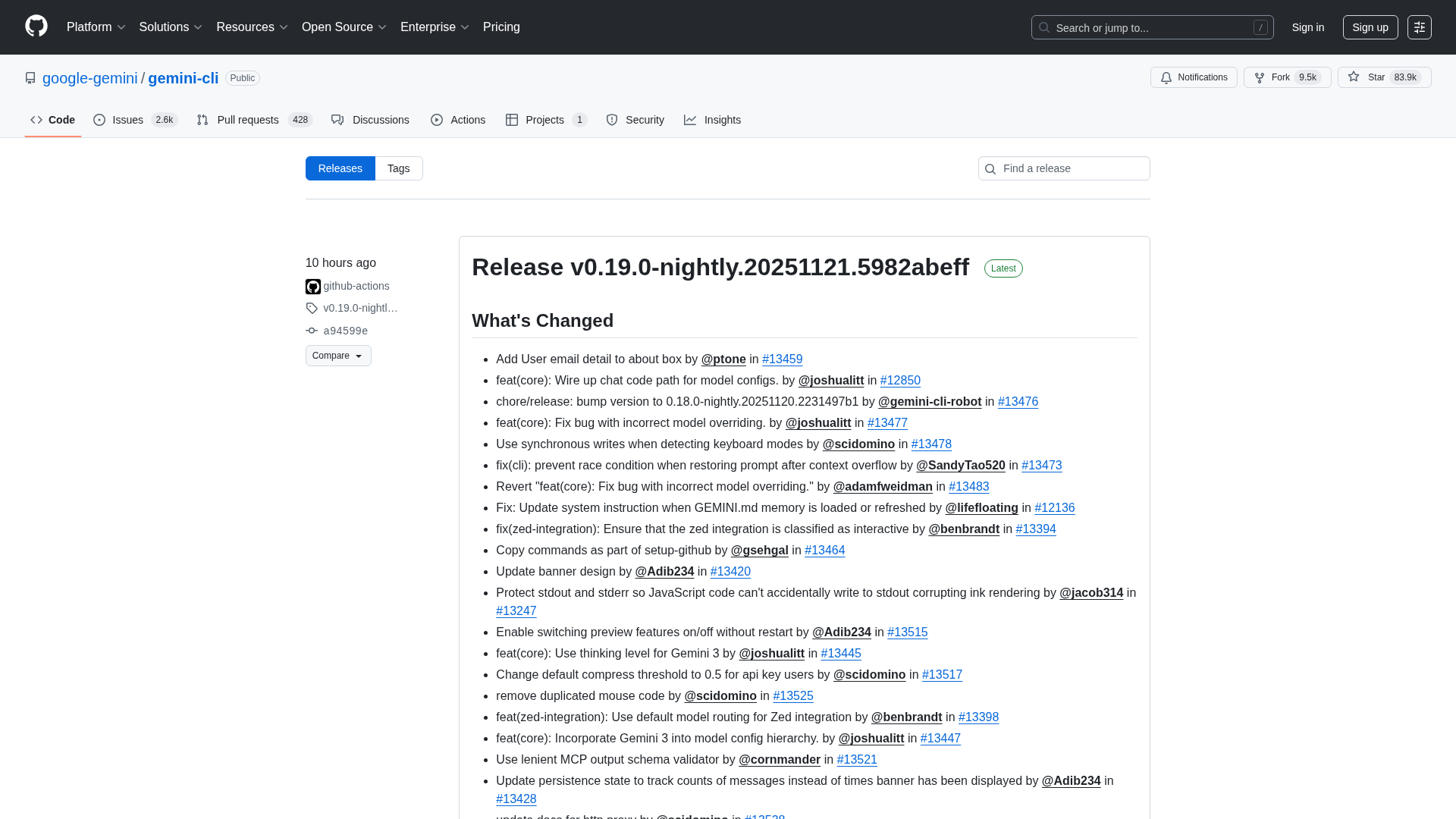
Overview of the Gemini CLI v0.36.0-preview release series, highlighting architectural, CLI, and UI changelogs across multiple pre-release versions.
A practical, step-by-step guide to fine-tuning large language models with open-source NLP tools.
OpenAI rolls out global group chats in ChatGPT, supporting up to 20 participants in shared AI-powered conversations.
A detailed, use-case-driven comparison of Gemini 3 Pro and GPT-5.1 across context windows, multimodal capabilities, tooling, benchmarks, and pricing.

Google’s Gemini 3 Pro debuts with top benchmarks and wider integration, signaling a potential edge in the AI arms race.