Overview
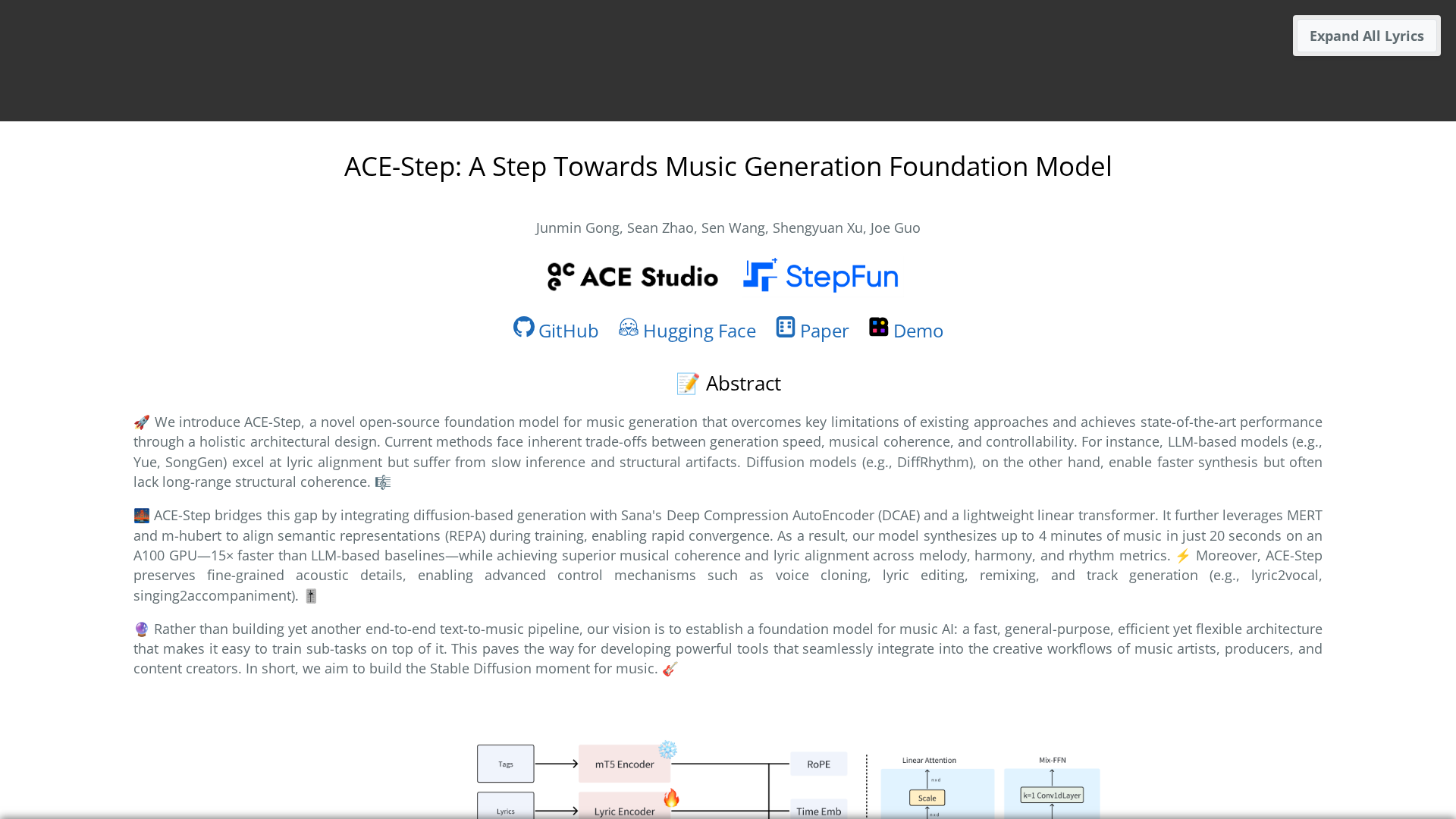
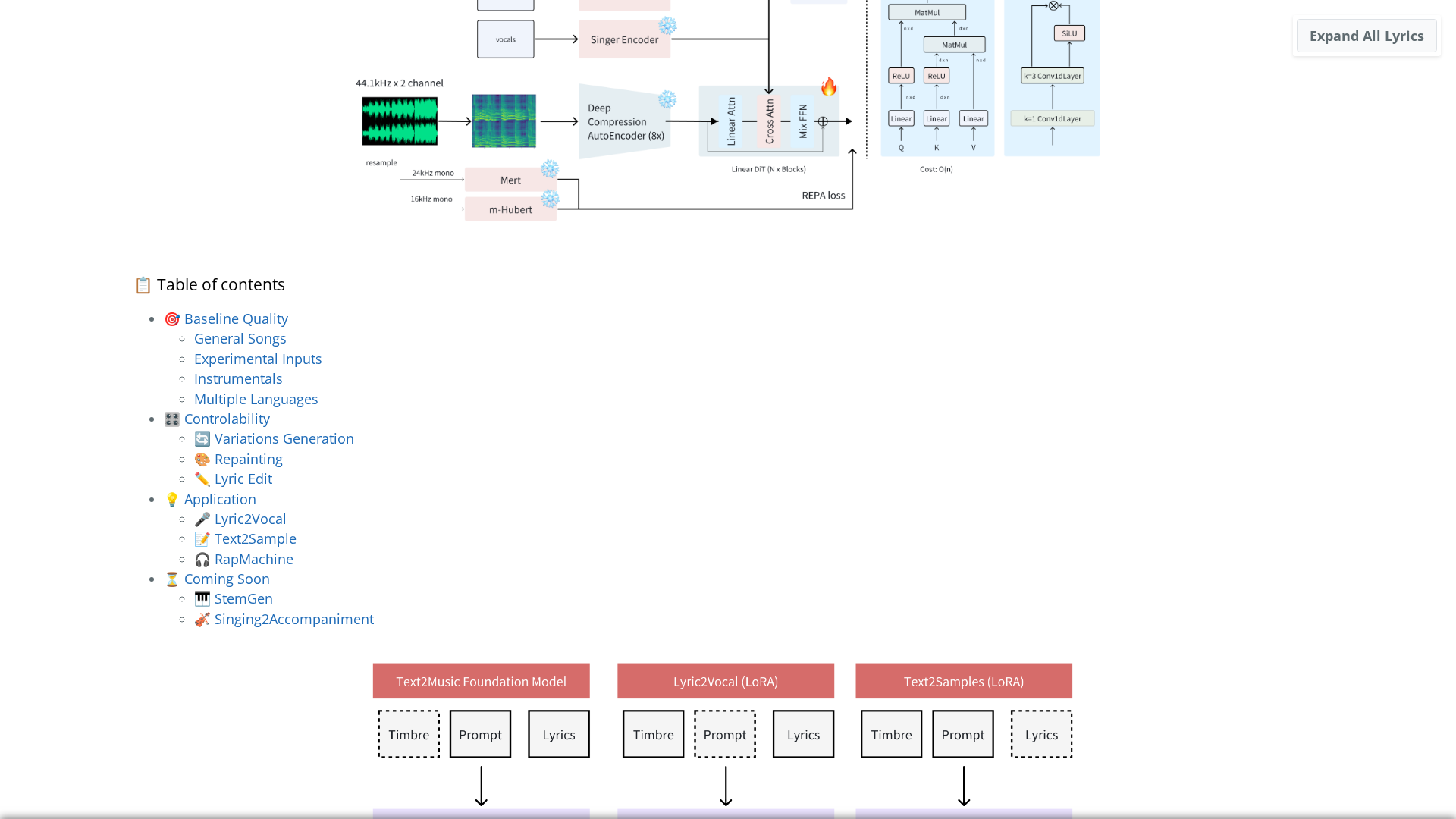
ACE-Step is a fast, coherent open-source foundation model for music generation. It uses a diffusion-based generation process conditioned by a lightweight linear transformer and leverages Sana’s Deep Compression AutoEncoder (DCAE) to encode audio into compact latents. It also employs representation alignment components (MERT and m-hubert), referred to as REPA, to align semantic and lyric signals during training. The main public model ACE-Step v1-3.5B delivers high throughput, synthesizing roughly 4 minutes of music in about 20 seconds on an NVIDIA A100, roughly 15× faster than several LLM-based baselines it compares to. The project supports full-song generation from natural-language prompts with duration control, lyric alignment and lyric-conditioned vocal generation, voice cloning, lyric editing, remixing, and track generation (e.g., lyric2vocal, singing2accompaniment). It includes training-free editing operations (retake, repaint, edit, extend) and fine-tuning/LoRA possibilities discussed in the community. Apache 2.0 license; no pricing; code, weights, and demos are distributed via GitHub/Hugging Face with community resources and demos.
Key Features
Full-song generation from natural-language prompts
Text-to-music generation with duration control.
Lyric alignment and lyric-conditioned vocal generation
Supports aligning lyrics to music and generating singing vocals.
Voice cloning, lyric editing, remixing, track generation
Includes lyric2vocal, singing2accompaniment, and related capabilities.
Training-free editing operations
Retake, repaint, edit, and extend audio.
Fine-tuning / LoRA support
Community discussions mention LoRA training and usage.
Who Can Use This Tool?
- Researchers:Experiment with diffusion-based music generation and open-source AI music pipelines
- Musicians/Content creators:Generate musical ideas, auto-lyrics alignment and vocal accompaniment
- Educators:Demonstrate open-source AI-based music generation workflows
Pricing Plans
Basic open-source access with code, weights, and demos.
- ✓Source code access
- ✓Weights availability
- ✓Demos and docs
Pros & Cons
✓ Pros
- ✓Open-source Apache 2.0 license
- ✓High-throughput diffusion-based music generation
- ✓Supports full-song generation and lyric alignment
- ✓Voice cloning and lyric editing features
- ✓LoRA/fine-tuning potential via community discussions
✗ Cons
- ✗Output variability due to random seeds
- ✗Weaker performance on some genres/languages (e.g., Chinese rap)
- ✗Continuity/artifacts during repaint/extend
- ✗Vocal quality not perfect; some limitations in synthesis
- ✗Coherence may degrade for durations beyond ~5 minutes
- ✗Potential copyright and misuse risks; need for disclosure and ethical considerations
Related Articles (5)
Open-source foundation model for fast, coherent, and controllable music generation blending diffusion, DCAE, and lightweight transformers.
A practical tutorial comparing native and custom-node ACE-Step workflows in ComfyUI, with multilingual input and step-by-step usage.
A practical guide to implementing ACE-Step in ComfyUI using native and custom nodes, including multilingual inputs, LoRA, and prompts.
ACE-StepとComfyUIのネイティブおよびカスタムノードで多言語対応の音楽生成を解説するチュートリアル
Early Ace-Step 1.5 preview focusing on fast setup and new features.