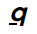%201.png)
Overview
Summary derived from https://www.flex.ai/ and linked pages. FlexAI positions itself as a software-defined, hardware-agnostic AI infrastructure platform (slogan: “One platform. Any cloud. Any hardware. Anywhere.”) that routes workloads to optimal compute to speed deployments, improve utilization, and lower cost. Marketing claims include job launches under 60 seconds, high GPU utilization (marketing cites up to ~90%), heterogeneous hardware orchestration (NVIDIA, AMD, TPUs, Tenstorrent, BYO), fractional GPUs, autoscaling, Smart Sizing and Workload Co‑Pilot for automated placement, Dedicated and Serverless inference endpoints, blueprints and one-click deployment templates, cross-cloud caching to reduce egress fees, managed checkpoints and self-healing infrastructure, and observability/platform services (Checkpoint Manager, Secret Manager, Dataset Manager, Code Registry, remote storage connectors, metrics dashboards). Key site pages reviewed: Home (marketing overview, $100 get-started credit), Pricing (tiered, usage-driven: Starter, Scale-ups/Essential, WhiteGlove/Enterprise; per-GPU per-minute/hour rates present on the page but detailed line-by-line extraction failed due to validation limits), Why FlexAI (comparisons and competitive positioning vs Run:AI, Anyscale, Modal, Rafay), Any Compute (product details: Workload Co‑Pilot, Smart Sizing, fractional GPUs, autoscaling, fallback pools, serverless vs dedicated endpoints), Blueprints (templates for agents, RAG/QA, transcription, training and fine-tuning examples), Calculator (savings/TCO estimator), Docs hub (developer & ops docs, support channels, examples), and Startup Program (up to $20k in GPU credits over 12 months; beta with eligibility guidance). Company facts reported on site and press: co-founders Brijesh Tripathi (co-founder & CEO) and Dali Kilani (co-founder); engineering leadership includes hires from NVIDIA, Apple, Tesla, Intel; announced exit from stealth in April 2024 with a reported $30M seed round; site references ~60+ customers and teams in 25+ countries and partnerships (mentions Google, Microsoft, AMD, and partner-backed FlexAI Cloud). Contact/support emails referenced in docs: [email protected] and [email protected]. Notes and caveats: some marketing claims (utilization and cost savings) are customer/marketing claims and will vary; some pages (e.g., Inference Sizer) returned 404 during collection; automated extraction of full Pricing page feature tables and per-GPU line items hit validation/size limits — contact sales or view Pricing page for exact per-minute/per-hour GPU rates and full feature tables.
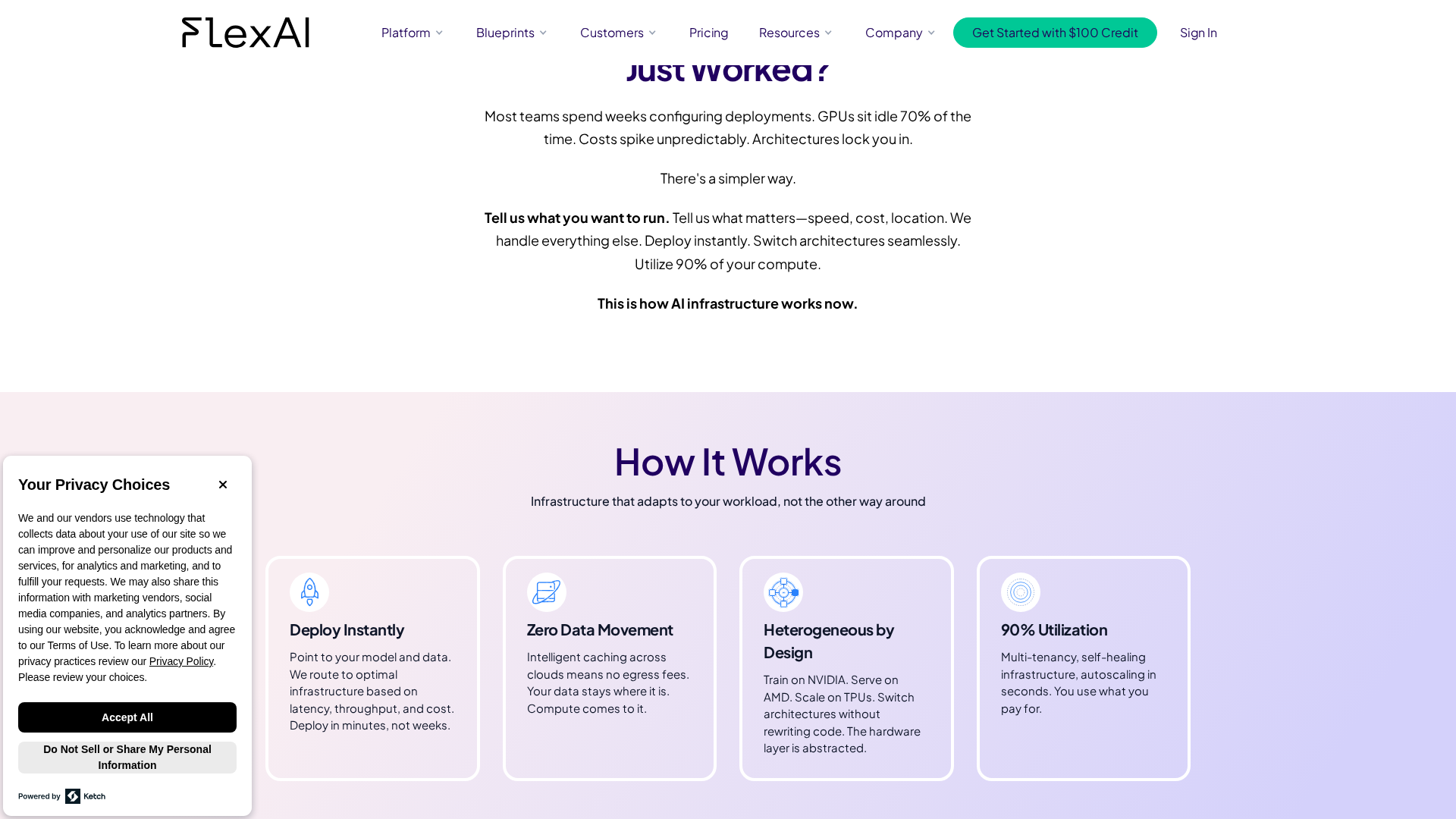
Key Features
Hardware-agnostic orchestration
Schedules workloads across NVIDIA, AMD, Tenstorrent, TPUs, and BYO compute without changing model code.
Smart Sizing & Workload Co-Pilot
Recommends compute mix based on latency, throughput, and cost constraints to optimize placement.
Fractional GPUs & autoscaling
Fractional GPU support, autoscale in seconds, and fallback pools to reduce overprovisioning and improve availability.
Dedicated and Serverless inference endpoints
Provides both dedicated and serverless inference endpoints with one-click deployment templates and blueprints.
Cross-cloud caching and data locality
Caches across clouds to reduce egress fees and keep data locality when possible.
Managed checkpoints & self-healing infra
Managed checkpoint service and self-healing features to maintain long-running workload resilience.
Who Can Use This Tool?
- Startups:Apply to Startup Program for GPU credits (up to $20k over 12 months) and use templates/zero-DevOps onboarding.
- Developers / Individual devs:Use Starter tier (includes $100 credit), blueprints, and docs to prototype and launch models quickly.
- Teams / Scale-ups / Enterprises:Use Scale-ups/Essential or WhiteGlove/Enterprise tiers for multi-seat management, higher SLAs, enterprise security, and negotiated pricing.
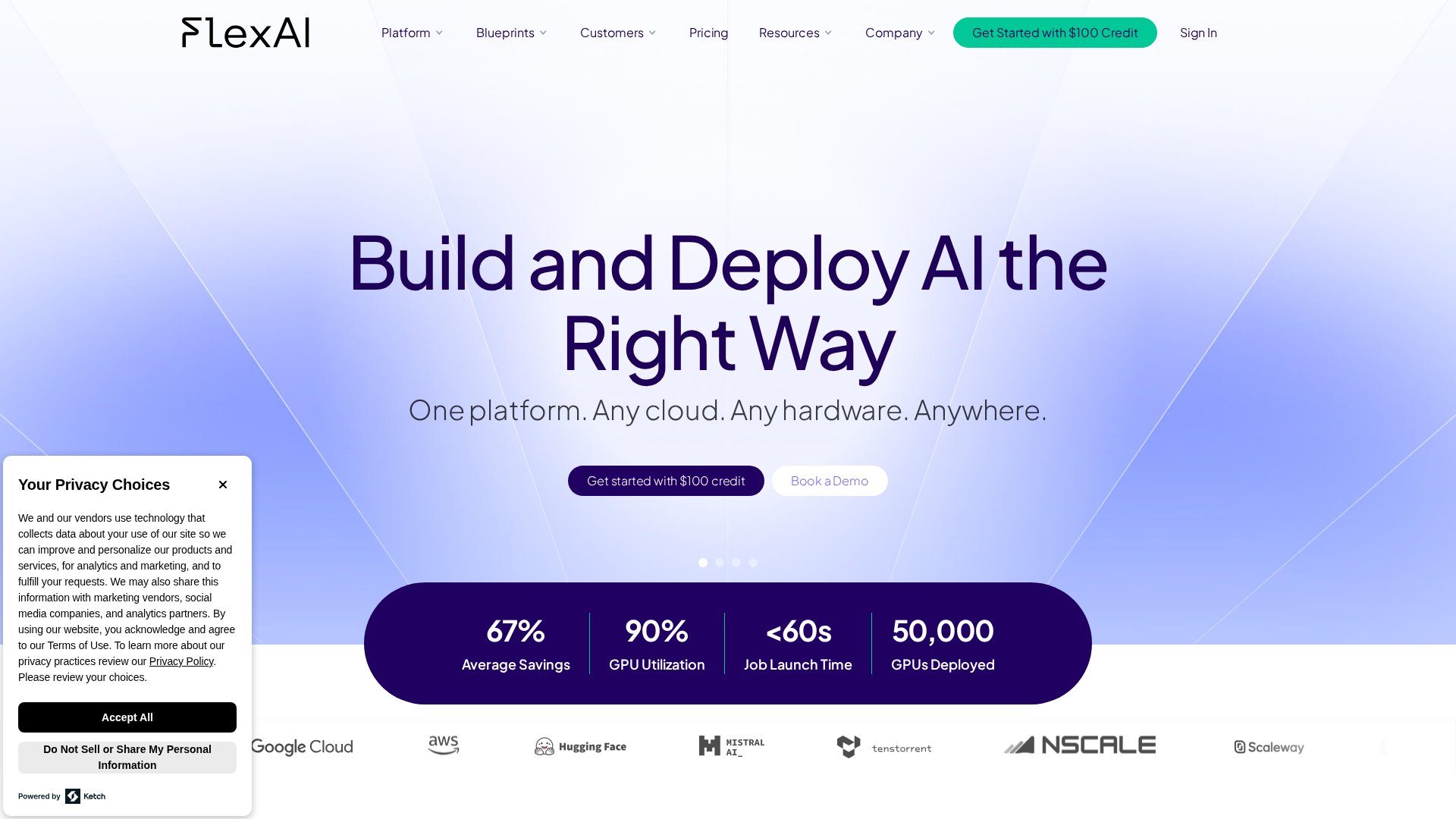
Pricing Plans
Entry-level tier for startups and individual developers with get-started credit and basic platform features.
- ✓$100 credit for new signups (get-started credit)
- ✓2 workspace seats
- ✓Basic monitoring and support
- ✓Standard security/GDPR features
- ✓Access to blueprints and templates
- ✓Per-GPU per-minute/hour usage (detailed rates on Pricing page)
- ✓Ability to BYO infrastructure or use FlexAI Cloud
- ✓Access to docs and developer blueprints
Mid-tier for growing teams; adds more seats, concurrency/fractional GPU support, higher SLA and premium support.
- ✓More seats (example cited: 8 seats)
- ✓Concurrency and fractional GPU support
- ✓Smart Co-pilot and Smart Sizing
- ✓Higher SLA example noted (e.g., 99.5%)
- ✓Premium support (private Slack) and faster response
- ✓Discounting for reservations/committed usage
- ✓HIPAA/DORA notes referenced for compliance
- ✓Per-GPU usage pricing with volume discounts (details via sales)
Enterprise-tier with unlimited seats, geo-redundant endpoints, higher SLA, enterprise security/compliance, managed services and custom licensing.
- ✓Unlimited seats and geo-redundant endpoints
- ✓Higher SLA example noted (e.g., 99.9%)
- ✓Audit logs, admin policies, and advanced monitoring/billing
- ✓Managed checkpoints, self-healing, and customer success team
- ✓Enterprise security and compliance features
- ✓Custom licensing, discounts, and negotiated pricing
- ✓Managed onboarding and priority support
- ✓Detailed per-GPU rates and reservations typically handled via sales
Pros & Cons
✓ Pros
- ✓Hardware-agnostic orchestration across multiple accelerator types and clouds
- ✓Smart Sizing and Workload Co-Pilot for automated placement and cost/latency optimization
- ✓Fractional GPUs and fast autoscaling to improve utilization and reduce overprovisioning
- ✓Ready blueprints, templates, and documentation for common ML pipelines
- ✓Startup program and get-started credits lower barrier for early users
- ✓Observed emphasis on enterprise controls, security, and compliance for larger customers
✗ Cons
- ✗Marketing claims (e.g., >90% utilization, 50%+ cost reductions) are customer/marketing claims and outcomes will vary
- ✗Detailed per-GPU per-minute/hour rates and full pricing line items were not fully extractable; sales contact often required for exact quotes
- ✗Some pages (e.g., Inference Sizer) returned 404 during collection
- ✗Automated extraction of long feature lists and full line-item GPU rates hit validation/size limits
Compare with Alternatives
| Feature | FlexAI | Run:ai (NVIDIA Run:ai) | Inference.ai |
|---|---|---|---|
| Pricing | N/A | N/A | N/A |
| Rating | 8.1/10 | 8.4/10 | 8.4/10 |
| Multi-cloud Routing | Yes | Yes | No |
| Fractional GPUs | Yes | Yes | Yes |
| Autoscaling Intelligence | Yes | Yes | Partial |
| Serving Endpoints | Yes | Partial | Partial |
| Workload Co-pilot | Yes | No | No |
| Observability Depth | Full-stack observability and platform services | Enterprise observability and governance | Basic monitoring and utilization metrics |
| Platform Extensibility | APIs and BYO infrastructure blueprints | Kubernetes-native extensibility and multi-cluster control | Web-console focused, limited extensibility |
Related Articles (15)

A deep dive into Akash Network, the decentralized cloud marketplace challenging traditional cloud models.
Analyzes data centers' AI-driven demand, energy and water needs, policy barriers, and routes to equitable digital infrastructure.
Nokia unveils Autonomous Networks Fabric to accelerate AI-powered, zero-touch network automation.
Affordable, on-demand GPUs for ML training, inference, and containerized apps via Akash Network.
HUMAIN and xAI plan 500MW hyperscale GPU data centers in Saudi Arabia and nationwide Grok deployment to create a unified national AI layer.