
Overview
Guardrails is an open-source Python framework and ecosystem that provides validators ("guardrails") around LLM inputs and outputs to prevent hallucinations, PII/data leaks, toxic or non-compliant content, prompt injections, and other risks. It produces structured outputs and provides low-latency, real-time validation, including streaming-safe validation that runs validators incrementally on streaming tokens. Core capabilities include Input Guards, Output Guards, a Validator/Guardrails Hub (65+ open-source validators), streaming-safe validation, and support for hosting validators/models remotely (including GPU hosting for low-latency inference). Guardrails can be run as an OSS local or server mode (Guardrails Server), self-hosted in a private VPC, or used via Guardrails Pro, a managed enterprise offering that provides a Private Hub for custom validators distribution, observability dashboards and alerts, multi-tenant support, CI/CD integration, and centralized governance. Integrations and compatibility include OpenAI-compatible endpoints, LangChain integration, support for Anthropic and Hugging Face models, and documented remote validation inference. Important notes: no public pricing information was found on the site; the Guardrails Pro page describes features and deployment options and invites scheduling demos or contacting sales for pricing and commercial terms. The site includes release notes and blog posts documenting releases (v0.2.0, v0.3.0), Guardrails Server 0.5.0, and the Guardrails Pro announcement.
Key Features
Input Guards & Output Guards
Validators for both inputs and outputs to enforce policies, structure outputs, and block risky content.
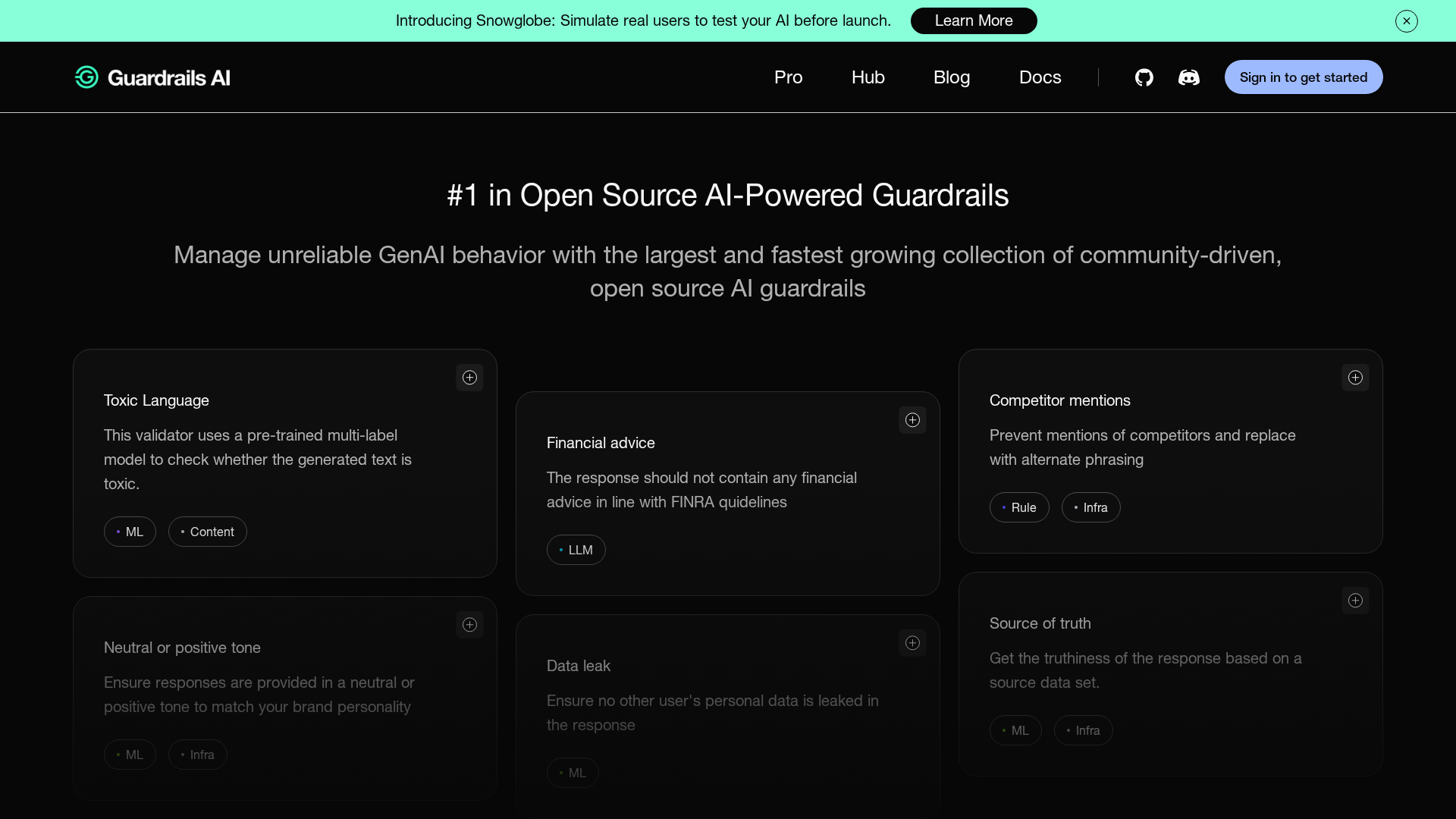
Guardrails Hub (65+ validators)
Library/hub of 65+ open-source guardrails covering multiple use cases and risk types; Private Hub option in Pro.
Streaming-safe, real-time validation
Supports streaming LLM responses and runs validators incrementally on chunks to detect failures as tokens stream.
Remote validation and GPU hosting
Support for hosting validation models remotely or using hosted validators, including GPU hosting for low-latency inference.
Guardrails Server (service mode)
Local/server mode (Guardrails Server) provides API-compatible endpoints and a server/start CLI (0.5.0 release noted).
Integrations and compatibility
OpenAI-compatible endpoints, LangChain integration, support for Anthropic/Hugging Face, and other documented integrations.
Who Can Use This Tool?
- Developers:Integrate validators into LLM pipelines to enforce policies and produce structured outputs.
- Enterprises:Use Guardrails Pro for private hubs, observability, governance, and VPC deployment at scale.
Pricing Plans
Installable open-source Python framework for local or server use; community-provided validators and Hub.
- ✓Installable OSS framework
- ✓Access to open-source Guardrails Hub validators
- ✓Local and Guardrails Server modes
Managed, enterprise-grade offering with Private Hub, observability, multi-tenant support, and VPC deployment. Pricing not listed publicly; contact sales.
- ✓Private Hub for custom guardrails distribution
- ✓Observability dashboards and alerts
- ✓Multi-tenant support and centralized governance
- ✓One-click VPC deployment and CI/CD integrations
- ✓GPU-based validators for low latency
Pros & Cons
✓ Pros
- ✓Provides structured outputs and policy enforcement for LLM inputs and outputs
- ✓Real-time, streaming-safe validation to catch failures as tokens stream
- ✓Large library of open-source validators (65+ at time of collection)
- ✓Supports remote validation and GPU hosting for low-latency inference
- ✓Integrations with OpenAI-compatible endpoints, LangChain, Anthropic, Hugging Face
- ✓Guardrails Pro adds observability, multi-tenant governance, Private Hub, and managed VPC deployment
✗ Cons
- ✗No public pricing information found; Guardrails Pro requires contacting sales for pricing
- ✗Enterprise features and Private Hub are gated behind Guardrails Pro (sales/demo flow)
- ✗Low-latency validation at scale may require additional infrastructure (e.g., GPU hosting)
Compare with Alternatives
| Feature | Guardrails | RagaAI | Langtail |
|---|---|---|---|
| Pricing | N/A | N/A | $99/month |
| Rating | 8.0/10 | 8.2/10 | 8.2/10 |
| Enforcement Mode | Yes | Yes | Partial |
| Validator Coverage | 65+ validators | Step-level validators | Assertions & evaluations |
| Streaming Validation | Yes | Yes | Partial |
| Remote Hosting | Yes | Partial | Partial |
| Observability Depth | Observability and governance | Agentic step-level tracing | Prompt analytics and monitoring |
| Integration Flexibility | Extensive integrations | Orchestration and SDKs | Multi-provider model support |
| Governance Controls | Governance and audit controls | Enterprise compliance controls | Security and sandboxing |
Related Articles (4)
A managed enterprise service to deploy centralized Guardrails in your VPC, with real-time risk monitoring.
Deploy guarded LLMs with an OpenAI-compatible API, telemetry, cross-language support, and JSON output for open-source models.
A practical guide to enabling OpenTelemetry observability for Guardrails-powered LLM apps.
Real-time validation for streaming LLM outputs with Guardrails AI safeguards.