Topic Overview
This topic covers the rapidly maturing stack of AI audio models and consumer audio devices that power voice synthesis, transcription, music generation and always‑on personal assistants. Advances in high‑fidelity text‑to‑speech (TTS) and voice cloning are enabling lifelike audio for podcasts, accessibility, and live assistants, while low‑latency models are being embedded into earbuds and mobile services for real‑time interactions. At the same time, diffusion and transformer‑based music models are accelerating music and sound‑effect creation and iteration. Key tools illustrate the ecosystem: ElevenLabs offers production‑grade expressive TTS, high‑fidelity voice cloning, Speech‑to‑Text (Scribe) and voice agents; Smallest.ai provides low‑latency, multilingual TTS with emotion control and a voice library; EchoPod automates transforming long‑form text into studio‑quality podcast episodes; ACE‑Step is an open, diffusion‑based music foundation model focused on speed and coherence; Amadeus Code (formerly Evoke Music) supplies curated AI sound generation, Topline MIDI and SFX libraries; Musci and other studios provide text‑to‑music workflows; MasteringBOX supplies automated mastering; and specialist services (YouTube transcript generators, Sophie the 24×7 AI voice operator) handle transcription and conversational phone workflows. Mistral AI’s emphasis on open, efficient models and governance reflects growing attention to privacy, model stewardship and deployment controls. As of 2026, the primary trends are real‑time TTS in consumer devices, end‑to‑end content pipelines (text→voice→distribution), broader availability of open music models, and heightened focus on consent, copyright and on‑device inference. Practical considerations—latency, personalization, safety, and integration with device hardware—will determine which tools and services succeed in consumer audio scenarios.
Tool Rankings – Top 6
Industry-leading AI audio platform for ultra-realistic text-to-speech, voice cloning, transcription, and voice agents.
Hyper-realistic AI voiceovers
Transform written content into captivating AI podcasts
Fast, high-coherence AI music, now more accessible
Website rebranded as Amadeus Code offering FUJIYAMA AI SOUND generation, curated music & SFX library, Topline MIDI, and付
music generator,song generator,ai music gengerator
Latest Articles (37)
MasteringBox launches a free, web-based AI mastering app for quick, accessible music mastering.
MasteringBox has launched its first Android mastering app, expanding its mobile production toolkit.
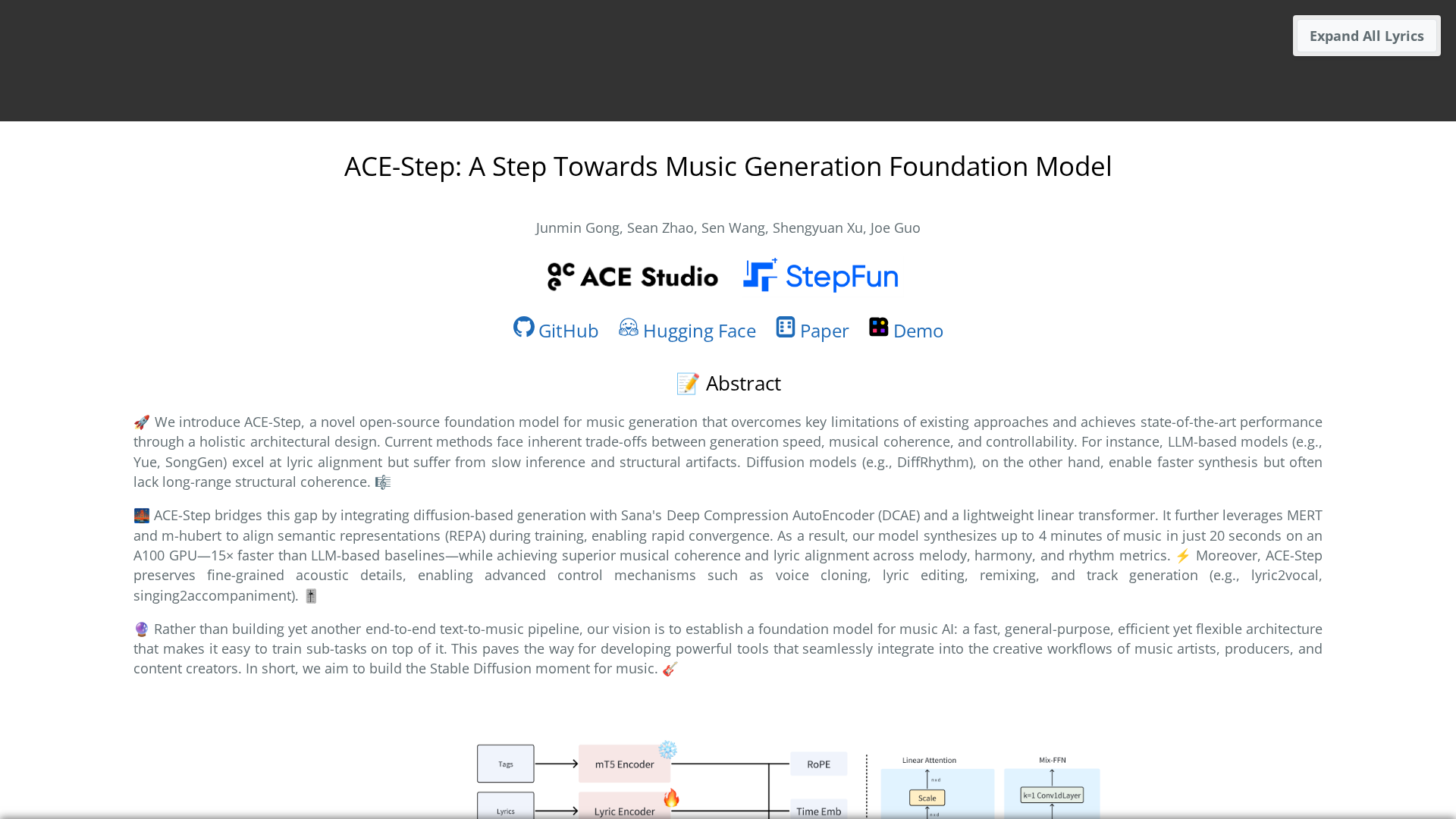
Open-source foundation model for fast, coherent, and controllable music generation blending diffusion, DCAE, and lightweight transformers.
A practical guide to implementing ACE-Step in ComfyUI using native and custom nodes, including multilingual inputs, LoRA, and prompts.
A practical tutorial comparing native and custom-node ACE-Step workflows in ComfyUI, with multilingual input and step-by-step usage.