Topic Overview
Open-source ASR and forced-alignment tooling in 2026 covers a spectrum from low-latency streaming models to offline, privacy-preserving transcribers and post-process alignment engines that produce word-level timestamps and speaker labels. This topic explains how models such as Qwen ASR and WhisperX are used in real-time and batch pipelines, and how they integrate with application-level tooling for meetings, content workflows, and conversational agents. Relevance in 2026 stems from three converging trends: matured open-source foundation models that close the quality gap with commercial services; widespread demand for accurate timestamps and speaker-aware transcripts for analytics and subtitles; and stronger privacy and edge-compute requirements that push transcription on-device. Practical tool categories include real-time voice engines (Voila — persona-aware, ultra-low-latency full-duplex voice models), on-device/offline transcribers (Bocca — local transcription and prompt generation for privacy-focused workflows), lightweight browser utilities (Speech Transcription, Speech Typing) and enterprise capture and intelligence platforms (Recall.ai for multi-source meeting capture; Krisp for noise reduction, live transcription, and meeting notes). Common pipelines pair streaming ASR for immediate captions with a later forced-alignment pass to refine word boundaries, punctuation, and speaker segments. Integrations prioritize SDKs and APIs that capture multi-platform meeting audio, apply noise suppression and speaker separation, and surface structured metadata for search and conversation intelligence. For developers and product teams, the key decisions are latency vs. accuracy, on-device privacy vs. cloud scalability, and whether to adopt end-to-end models or hybrid ASR+forced-alignment workflows for precise timestamps and downstream analytics.
Tool Rankings – Top 6

Open-source AI for real-time, expressive voice role-play
A push-to-talk tool that transforms your audio into text

Time speech transcription
API and SDK platform to capture, transcribe, stream, and surface meeting recordings and metadata (Zoom, Meet, Teams, etc
AI audio/meeting platform for noise cancellation, real-time transcription, meeting notes, accent conversion, and voice/音
Voice to text with google speech recognition
Latest Articles (9)
Bocca is an offline, on-device AI transcription and content tool that speeds prompts, transcripts, and multilingual tasks without internet access.
Snapshot of a GitHub repository page showing feedback prompts, blocking controls, abuse reporting, and a load error.
Freya raises $3.5M to scale AI voice agents for call centers, backed by Y Combinator and DOMiNO Ventures.
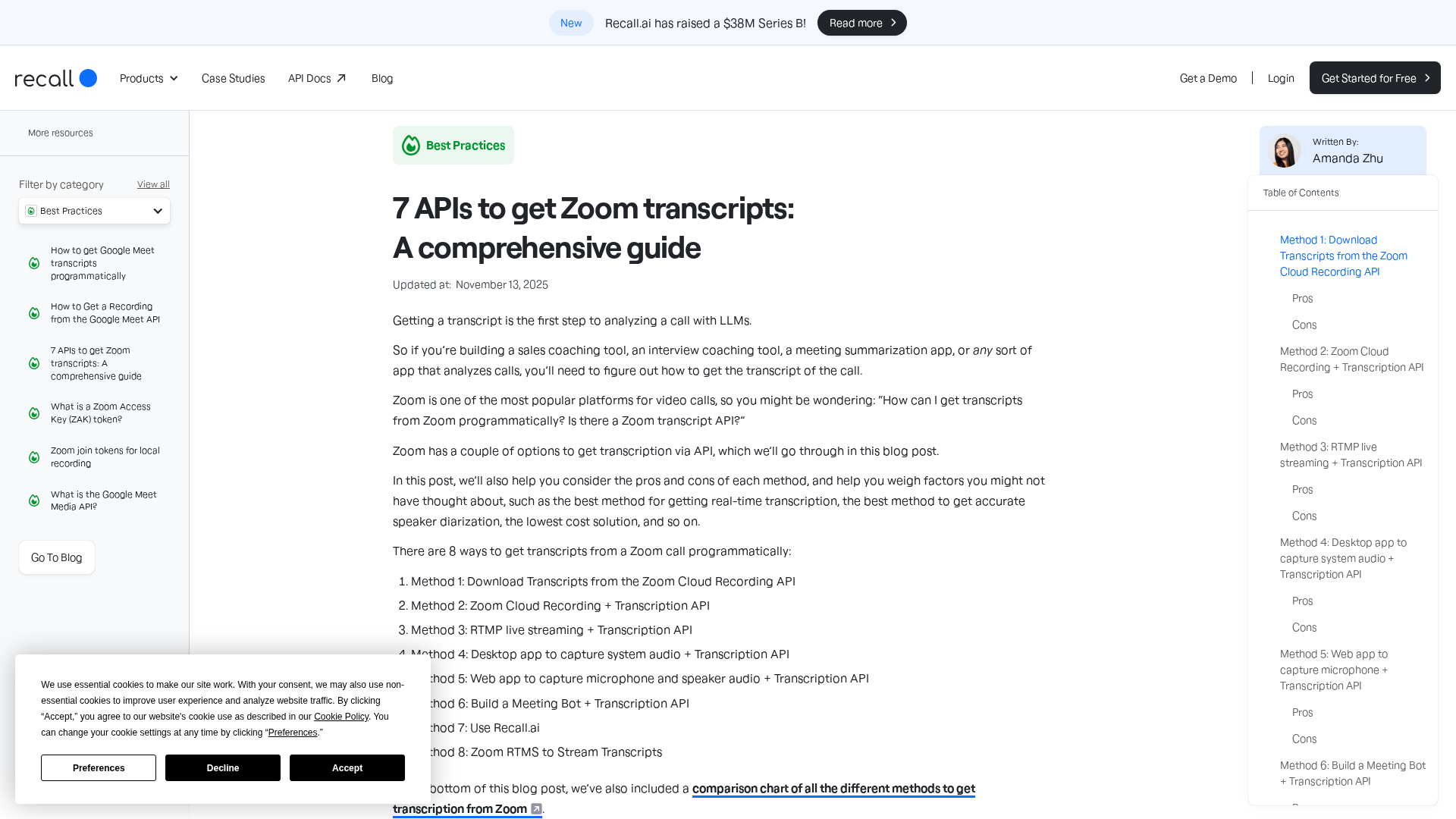
A comprehensive comparison of 8 Zoom transcript methods, from Cloud Recording to Recall.ai, covering real-time access, diarization, and costs.
A practical tutorial for integrating Recall.ai's Desktop Recording SDK to detect, record, transcribe, and retrieve meetings in Electron apps.