Overview
DatologyAI offers an automated, enterprise-focused data curation platform that converts raw datasets into model-ready training data using specialty curation algorithms. The site positions DatologyAI as a data-curation-as-a-service provider that helps customers "Train faster, Train better, Train smaller." Public materials emphasize that data quality is the main bottleneck for model performance and cost. Key capabilities described include scalable, automated pipelines (signal filtering, synthetic-data generation, deduplication, goal-specific prioritization/curation, curriculum sequencing, multilingual curation), research collaboration, and on-call researcher support. Deployments can be BYOC or on-prem to preserve data sovereignty and compliance; the platform is described as able to scale to petabyte / foundation-model scale. The company publishes research, case studies, and technical deep-dives (blog and insights) documenting methodology and customer results (examples: BeyondWeb, Arcee case study). Leadership and advisors referenced on the site include founders from FAIR/DeepMind/MosaicML and noted advisors/investors (Jeff Dean, Geoff Hinton, Yann LeCun, Adam D’Angelo, Aidan Gomez). Public-facing gaps include no published pricing tiers or trial offers, limited granular technical specifications or SLAs on public pages, and no surfaced public API or developer docs; pricing and detailed technical/operational terms appear to be provided via sales engagement (contact/book-a-call).
Key Features
Automated multi-step curation pipeline
Combines signal filtering, synthetic-data generation, deduplication, prioritization, and curriculum sequencing to prepare model-ready training data.
Scales to petabyte / foundation-model workloads
Platform is described as able to handle very large datasets and foundation-model scale curation workloads.
BYOC and on-prem deployment
Supports customer-hosted or on-prem deployments to preserve data sovereignty and compliance.
Goal-specific prioritization and curriculum learning
Allows curation tuned to specific model goals, using prioritization and sequencing to compound improvements.
Multilingual and multimodal curation
Includes workflows and techniques for multilingual data and text/image-text curation as described in posts.
Research collaboration and on-call support
Offers research collaboration and on-call researcher support as part of engagements.
Who Can Use This Tool?
- Enterprises:Procurement teams seeking enterprise-grade data curation with on-prem or BYOC deployment and support.
- ML/Research teams:Research and engineering teams wanting automated, scalable curation to improve model training efficiency and quality.
Pricing Plans
Enterprise, sales-led pricing; public pricing not available, contact required.
- ✓Custom deployment and pricing via sales engagement
- ✓Research collaboration and on-call support options
- ✓Data-sovereignty-friendly deployment (BYOC/on-prem)
Pros & Cons
✓ Pros
- ✓Automated, multi-step data curation designed to improve training speed, accuracy, and model size.
- ✓Scalable to very large (petabyte/foundation-model) datasets according to site claims.
- ✓Supports BYOC/on-prem deployments to preserve data sovereignty and compliance.
- ✓Offers research collaboration and on-call researcher support as part of engagements.
- ✓Publishes research, case studies, and technical deep-dives providing documented methodology and examples.
✗ Cons
- ✗No published pricing tiers, trial offers, or clear billing terms on the public site.
- ✗Limited granular technical specifications, SLAs, or developer/API documentation exposed publicly.
- ✗Public-facing materials suggest sales-led engagement is required for detailed operational, pricing, and deployment information.
Compare with Alternatives
| Feature | DatologyAI | Ocular AI | Snorkel AI |
|---|---|---|---|
| Pricing | N/A | N/A | N/A |
| Rating | 8.4/10 | 8.0/10 | 8.0/10 |
| Curation Pipeline | Yes | Partial | Yes |
| Scale & Throughput | Petabyte-scale throughput | GPU-backed scalable training | Enterprise-scale programmatic labeling |
| Deployment Flexibility | Yes | Partial | Partial |
| Curriculum Prioritization | Yes | Partial | Partial |
| Multimodal Support | Yes | Yes | Partial |
| Human-in-Loop | Partial | Yes | Partial |
| Evaluation & Benchmarks | Partial | Partial | Yes |
| Governance Traceability | Yes | Yes | Yes |
Related Articles (10)
DatologyAI offers automated, end-to-end data curation to train better AI models faster and more cost-effectively.

DatologyAI provides data curation as a service to improve model performance, speed, and cost efficiency by prioritizing high-value training data.
DatologyAI provides data-curation-as-a-service to speed up training, improve accuracy, and cut inference costs with scalable, on-prem or BYOC deployment.
A comprehensive hub of DatologyAI’s research updates, data-curation advances, and company milestones shaping data-centric AI.
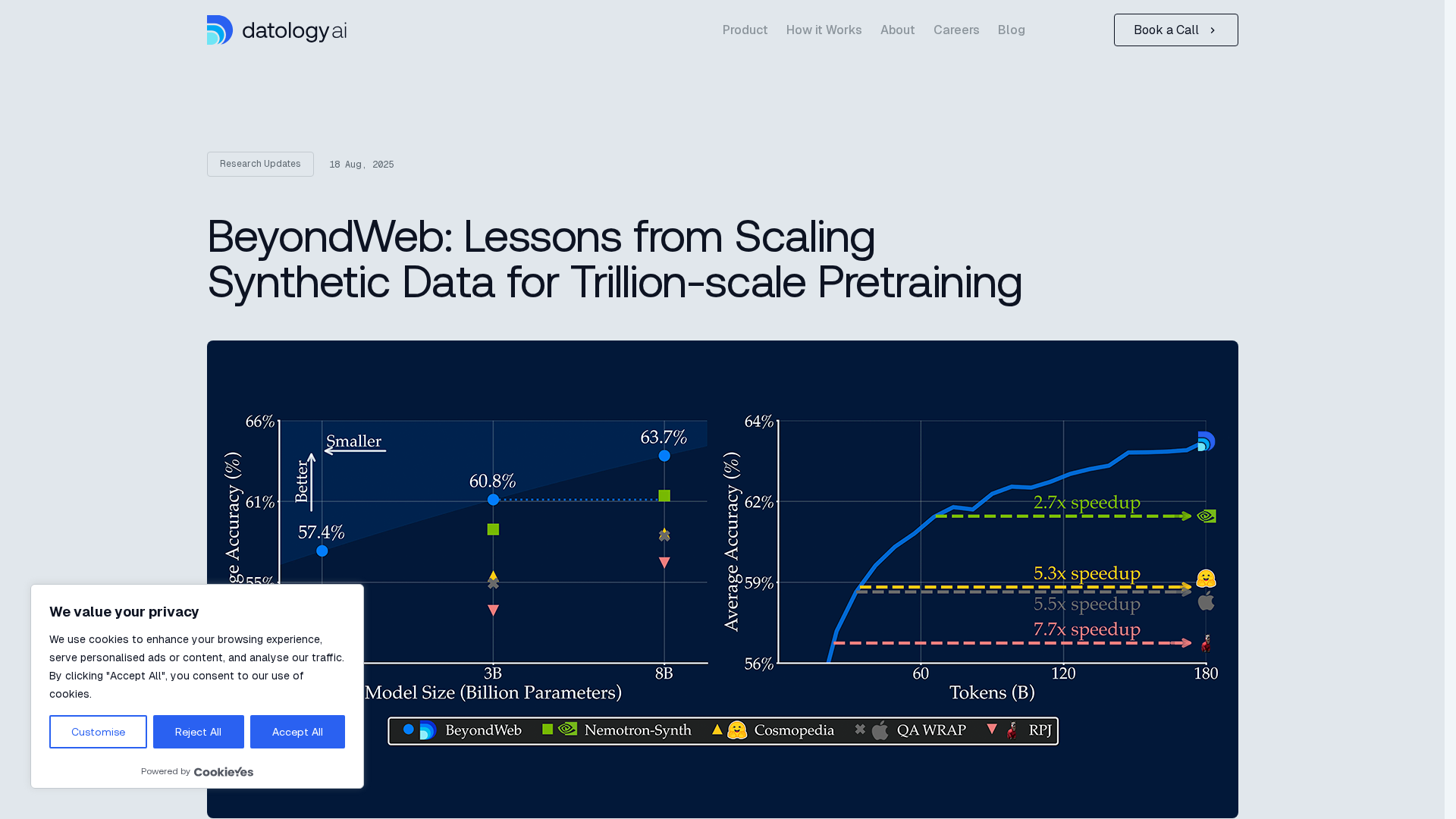
A rephrasing-based synthetic data pipeline (BeyondWeb) that improves trillion-token pretraining efficiency and accuracy across model scales.