Overview
Repository and research release summary for Salesforce CodeT5 and CodeT5+. Main repository: https://github.com/salesforce/CodeT5 (license indicated on the GitHub page: BSD-3-Clause). Primary papers: CodeT5 (EMNLP 2021) available at https://arxiv.org/abs/2109.00859 (introduces identifier-aware encoder–decoder pretraining with identifier masking and bimodal dual generation unified for code understanding and generation) and CodeT5+ (2023) at https://arxiv.org/abs/2305.07922 (describes flexible encoder–decoder large models with mixed pretraining objectives, instruction tuning, and large open checkpoints). Available Hugging Face checkpoints and model cards: Salesforce/codet5-small (https://huggingface.co/Salesforce/codet5-small), Salesforce/codet5-base (https://huggingface.co/Salesforce/codet5-base), Salesforce/codet5-large (https://huggingface.co/Salesforce/codet5-large), Salesforce/codet5-large-ntp-py (https://huggingface.co/Salesforce/codet5-large-ntp-py), and Salesforce/codet5p-220m (CodeT5+ checkpoint) (https://huggingface.co/Salesforce/codet5p-220m). Main capabilities documented across the repo, papers, and model cards include: text-to-code generation (NL -> code), code autocompletion (including full function completion from name/signature), code summarization (code -> NL), code translation (PL -> PL), refinement/repair, defect detection, clone detection, retrieval, and instruction-tuned variants (CodeT5+) for improved zero-shot/instruction behavior. Notable technical details: CodeT5 introduces identifier-aware pretraining and bimodal tasks to improve NL–PL alignment and preserve code semantics. CodeT5+ uses a mixture of pretraining objectives (span denoising, contrastive learning, text-code matching, causal LM) and can initialize from frozen LLM components to scale efficiently; it reports state-of-the-art numbers among open models on many code tasks according to the authors. Salesforce provides a demo (including a VS Code plugin) and invites sharing builds via [email protected]. The repository and model cards include ethical/usage guidance and restrictions (e.g., not to use models to promote violence, hate, environmental destruction, human-rights abuses, or harmful health recommendations) and advise following AI deployment documentation for high-stakes systems. What could not be obtained automatically here: the raw README and LICENSE file contents — automated raw-file fetch attempts triggered GitHub’s abuse-detection or returned 404 when pulling raw files via the scraper used; the GitHub HTML page indicates BSD-3-Clause but raw downloads of specific files failed in this automated fetch. Recommended ways to fetch full repo files: clone the repo locally (git clone https://github.com/salesforce/CodeT5.git) or browse the README and LICENSE via the GitHub web UI, or use the GitHub API with authentication (token) to avoid abuse-detection throttling. Example minimal Transformer usage for loading a CodeT5 checkpoint (from the repository notes/model cards): install transformers/accelerate, then in Python: from transformers import AutoTokenizer, AutoModelForSeq2SeqLM; tokenizer = AutoTokenizer.from_pretrained("Salesforce/codet5-base"); model = AutoModelForSeq2SeqLM.from_pretrained("Salesforce/codet5-base"); inputs = tokenizer("def add(a, b):", return_tensors="pt"); outputs = model.generate(**inputs, max_new_tokens=64); print(tokenizer.decode(outputs[0], skip_special_tokens=True)). If you want further follow-ups, options include retrying to fetch README/LICENSE with permission or a token, producing fine-tuning commands and data-prep for a specific downstream task, or retrieving more detailed model-card fields (ethical considerations, dataset descriptions, tokenizer info) for a chosen checkpoint.
Key Features
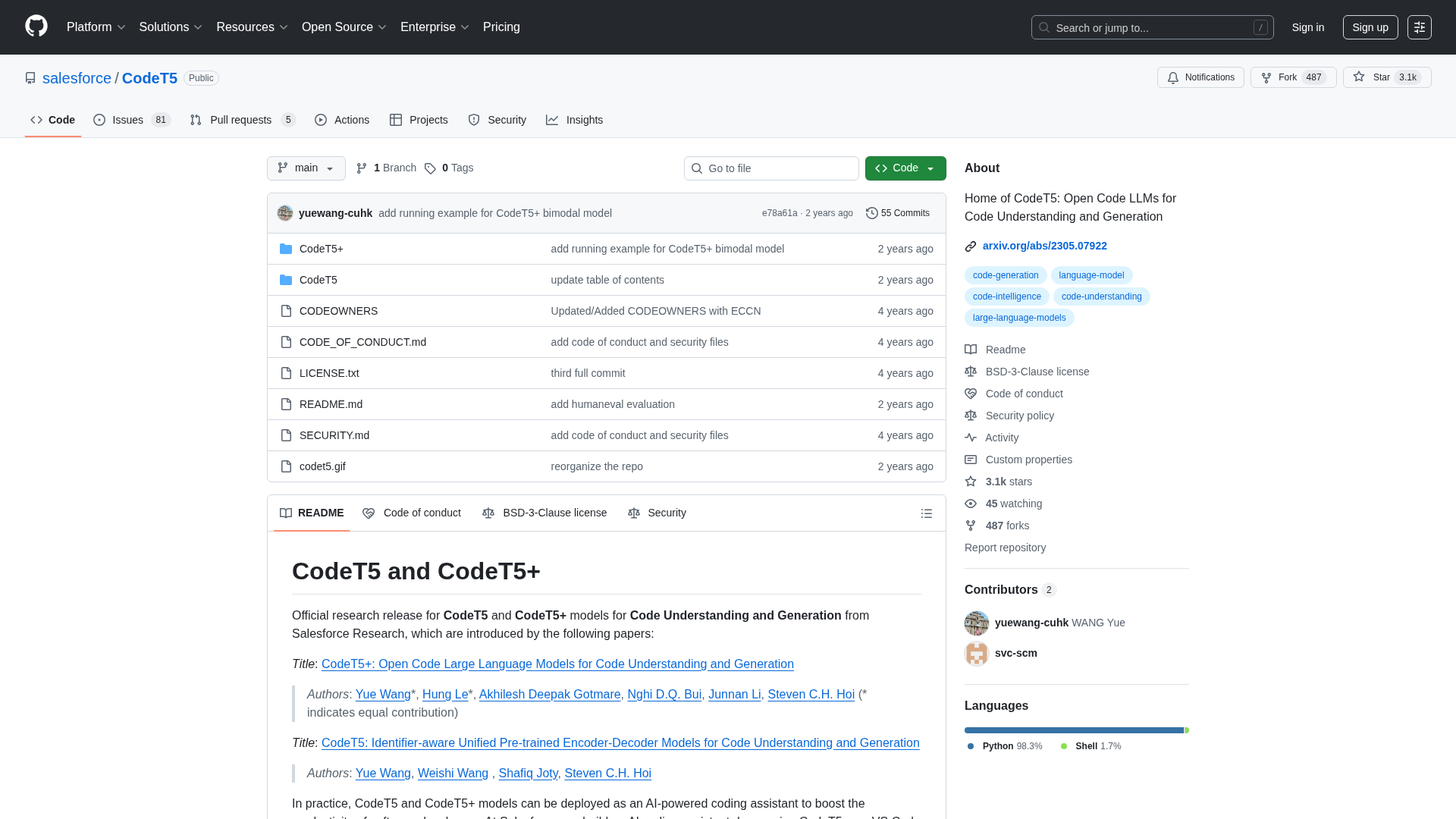
Text-to-code generation
Natural-language to code generation supported by encoder–decoder checkpoints for multiple languages and tasks.
Code autocompletion
Autocompletion including full function completion from a name/signature, per model-card examples.
Code summarization
Convert code to natural-language summaries (code -> NL) for documentation and comprehension tasks.
Code translation and repair
PL-to-PL translation, code refinement/repair, defect detection, clone detection, and retrieval use cases.
Instruction-tuned variants (CodeT5+)
Instruction-tuned CodeT5+ variants improve zero-shot and instruction-following behavior for downstream tasks.
Identifier-aware pretraining
CodeT5 uses identifier masking and bimodal dual-generation tasks to improve NL–PL alignment and preserve semantics.
Who Can Use This Tool?
- Developers:Code generation, completion, summarization, translation, and repair using Hugging Face checkpoints locally.
- Researchers:Research encoder–decoder pretraining, identifier-aware methods, and evaluate code-model benchmarks for papers and experiments.
Pricing Plans
Pricing information is not available yet.
Pros & Cons
✓ Pros
- ✓Open research release with multiple publicly available checkpoints on Hugging Face.
- ✓Identifier-aware pretraining and bimodal objectives improve NL–PL alignment and semantic preservation.
- ✓CodeT5+ offers scalable mixed-objective pretraining and instruction tuning for stronger open-model performance.
- ✓Model cards and repo include ethical/usage guidance and recommended deployment considerations.
✗ Cons
- ✗Automated retrieval of raw README and LICENSE failed here due to GitHub abuse-detection/404s; raw file contents were not obtained.
- ✗Model cards and repo contain usage restrictions and guidance that must be reviewed before deployment in high-stakes contexts.
- ✗Some operational details (e.g., exact README/LICENSE raw text) require manual fetch (git clone, web UI, or authenticated API) to obtain reliably.
Compare with Alternatives
| Feature | Salesforce CodeT5 | Code Llama | StarCoder |
|---|---|---|---|
| Pricing | N/A | N/A | N/A |
| Rating | 8.6/10 | 8.8/10 | 8.7/10 |
| Model Architecture | Encoder-decoder seq2seq | Decoder-only transformer family | Decoder-only multi-query attention |
| Instruction Tuning | Yes | Partial | Partial |
| Identifier Awareness | Yes | Partial | Partial |
| Context Window | Standard context window | Varied context sizes | Long context window |
| Fill-in-the-Middle | Partial | No | Yes |
| Local Inference | Yes | Yes | Yes |
| Tooling & Integrations | Partial'} | Yes | Yes |
Related Articles (10)
A concise primer on CodeT5+, Salesforce’s flexible AI for code generation, completion, and summarization, with a practical VS Code plugin example.
A practical, step-by-step guide to building a private code search assistant using open-source RAG on your laptop.
An enormous, up-to-date bibliography of LLM research papers spanning prompts, reasoning, evaluation, multimodal models, safety, and applications.
GitHub Releases page for Salesforce CodeT5 shows no releases yet and explains how to publish one.

Empirical evaluation of Waterfall-style multi-agent LLM workflows for class-level Python code generation using ClassEval.