Topic Overview
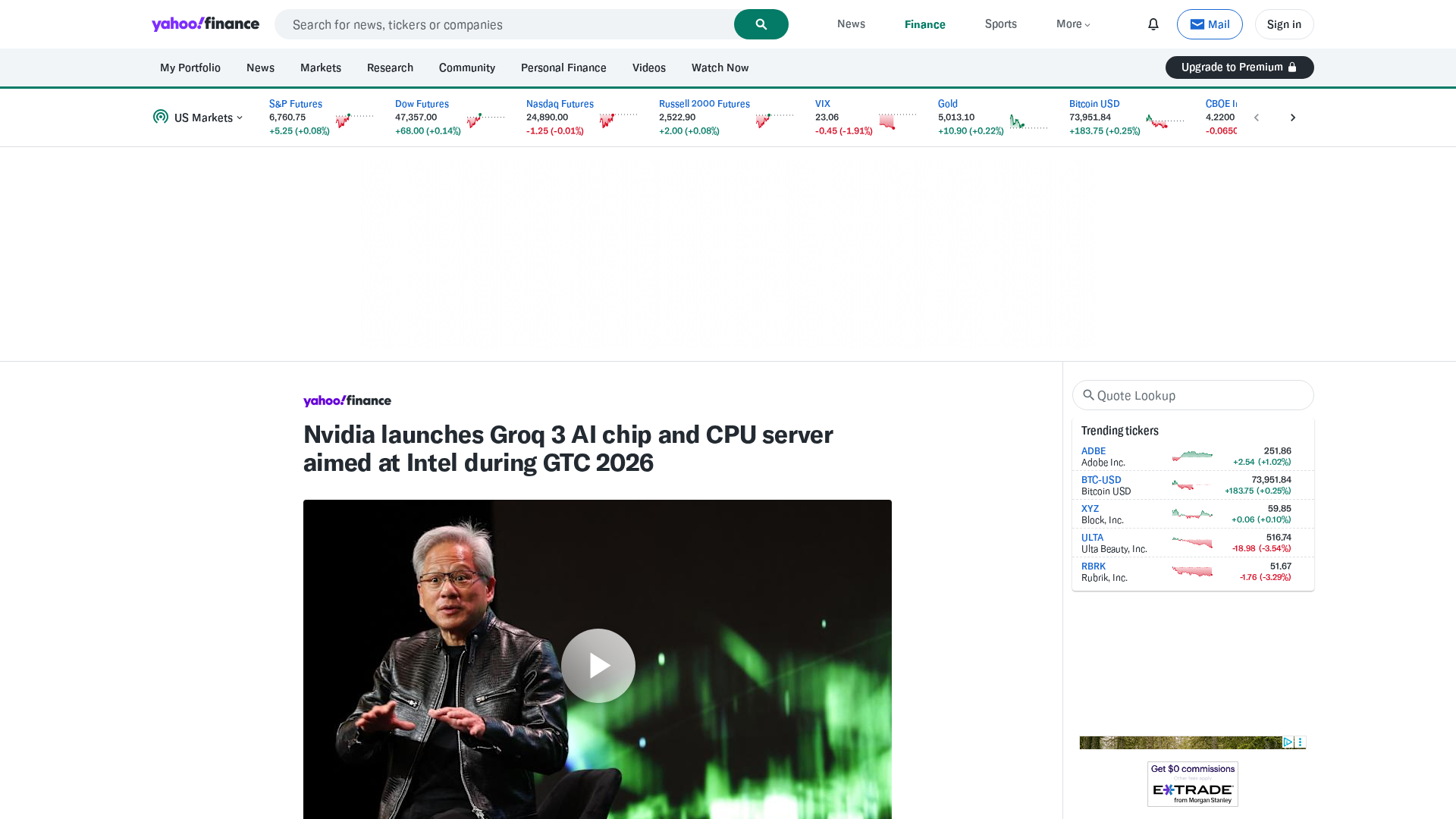
This topic surveys the contemporary landscape of inference accelerators and how they integrate with decentralized AI infrastructure and edge vision platforms as of 2026‑03‑17. Advances in chip design (Groq‑3 and other minimalist, low‑latency inference ICs), general‑purpose GPU families and software ecosystems (NVIDIA), and vertically integrated, model‑specific ASICs from large operators (Meta, Tesla) have driven a split between high‑throughput datacenter inference and low‑power, on‑device/edge inference. That bifurcation matters for latency, cost, privacy, and energy use. Practical deployments increasingly pair hardware choices with platform services: Together AI offers a full‑stack acceleration cloud with serverless inference APIs and fine‑tuning paths for open and specialized models; Mistral AI provides enterprise‑oriented, efficiency‑focused models and a production platform emphasizing privacy and governance; Cohere supplies private, customizable LLMs plus embeddings and retrieval services for enterprise search. These tools illustrate how model providers and cloud stacks abstract heterogeneous silicon — from Groq‑style inference chips to NVIDIA GPU clusters and proprietary Meta/Tesla ASICs — so organizations can choose tradeoffs between local/edge inference and centralized training. Key trends to watch are interoperability (ONNX, Triton and serverless adapters), model specialization for constrained hardware, and hybrid deployments that balance privacy and latency by placing parts of pipelines on edge accelerators while keeping training or retrieval in scalable cloud fleets. Understanding the differences in chip architecture, software stack support, and platform services is essential for architects selecting the right mix of accelerator, model, and deployment pattern for vision, retrieval, and real‑time inference workloads.
Tool Rankings – Top 3
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
Enterprise-focused provider of open/efficient models and an AI production platform emphasizing privacy, governance, and
Enterprise-focused LLM platform offering private, customizable models, embeddings, retrieval, and search.
Latest Articles (37)

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.

A practical, prompt-based playbook showing how Gemini 3 reshapes work, with a 90‑day plan and guardrails.
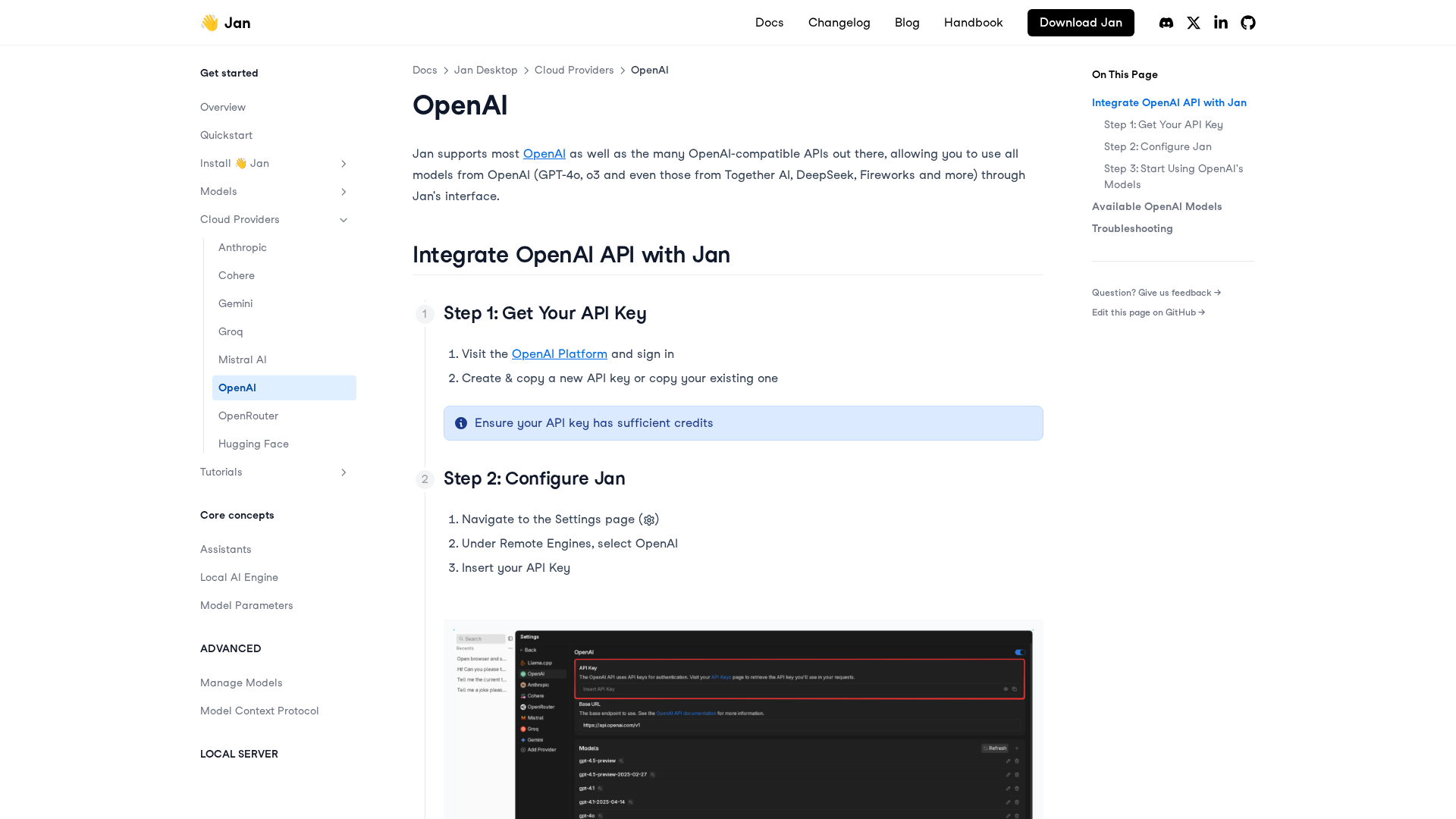
A practical, step-by-step guide to integrating OpenAI APIs with Jan for remote models, including setup, configuration, model selection, and troubleshooting.
...
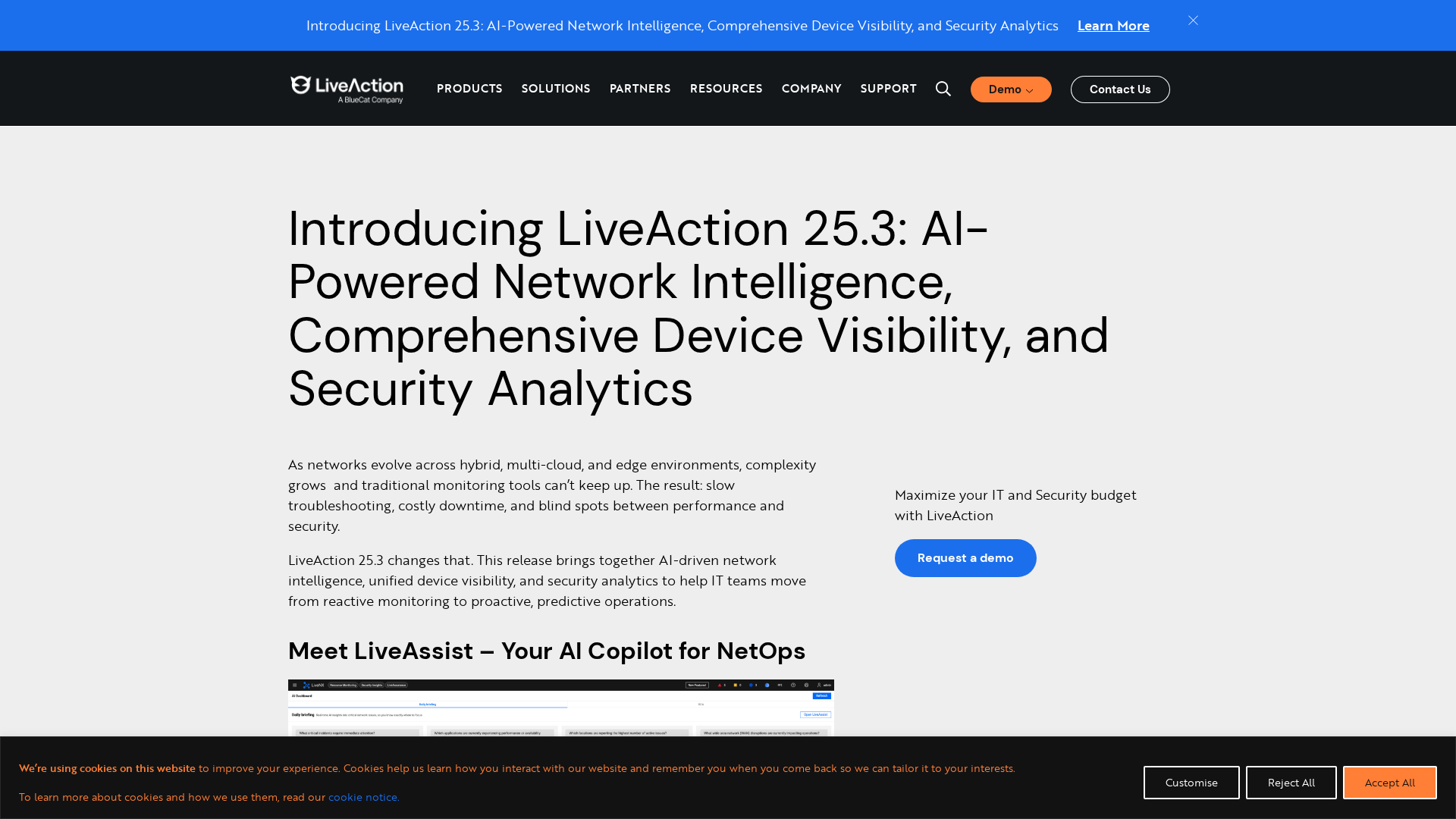
LiveAction 25.3 launches LiveAssist AI Copilot, Network Resource Monitoring, and Security Insights for proactive, AI-driven NetOps.