Topic Overview
This topic examines the current landscape of AI accelerators and inference hardware in 2026, covering hyperscale GPUs, domain-specific ASICs, and edge-focused chips from vendors such as Groq, Nvidia, Meta, Tesla and newer entrants. It focuses on the tradeoffs that matter for real deployments—latency, throughput, energy use, TCO, and software ecosystem maturity—and how those tradeoffs shape choices for Edge AI Vision Platforms and decentralized AI infrastructure. Market and technical drivers include larger and more capable multimodal models, demand for on-device privacy and low-latency vision inference, rising energy costs, and a shift toward inference-optimized silicon and chiplet architectures. Software trends—serverless inference APIs, quantization and sparsity-aware runtimes, and co‑optimised compilers—are increasingly decisive: hardware without a robust stack limits real-world gains. Key tools referenced here illustrate the full-stack responses to these trends. Together AI offers a full‑stack acceleration cloud combining training, fine‑tuning, and serverless inference for open and specialized models, simplifying deployment across GPU and accelerator pools. Rebellions.ai focuses on energy‑efficient inference accelerators (chiplets, SoCs and servers) plus a GPU‑class software stack for high‑throughput LLM and multimodal inference at hyperscale. Stability AI’s Stable Code provides edge‑ready, instruction‑tuned code models (around the 3B‑parameter class) designed for fast, private code completion on constrained hardware. Taken together, the ecosystem is moving toward heterogeneous deployments: cloud GPUs for training, specialized inference ASICs and chiplets for cost‑efficient serving, and compact, instruction‑tuned models for on‑device tasks. Evaluations should weigh hardware performance alongside software maturity, energy footprint, and integration with edge and decentralized orchestration layers.
Tool Rankings – Top 3
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
Energy-efficient AI inference accelerators and software for hyperscale data centers.

Edge-ready code language models for fast, private, and instruction‑tuned code completion.
Latest Articles (34)

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.
ProteanTecs expands in Japan with a new office and Noritaka Kojima as GM Country Manager.
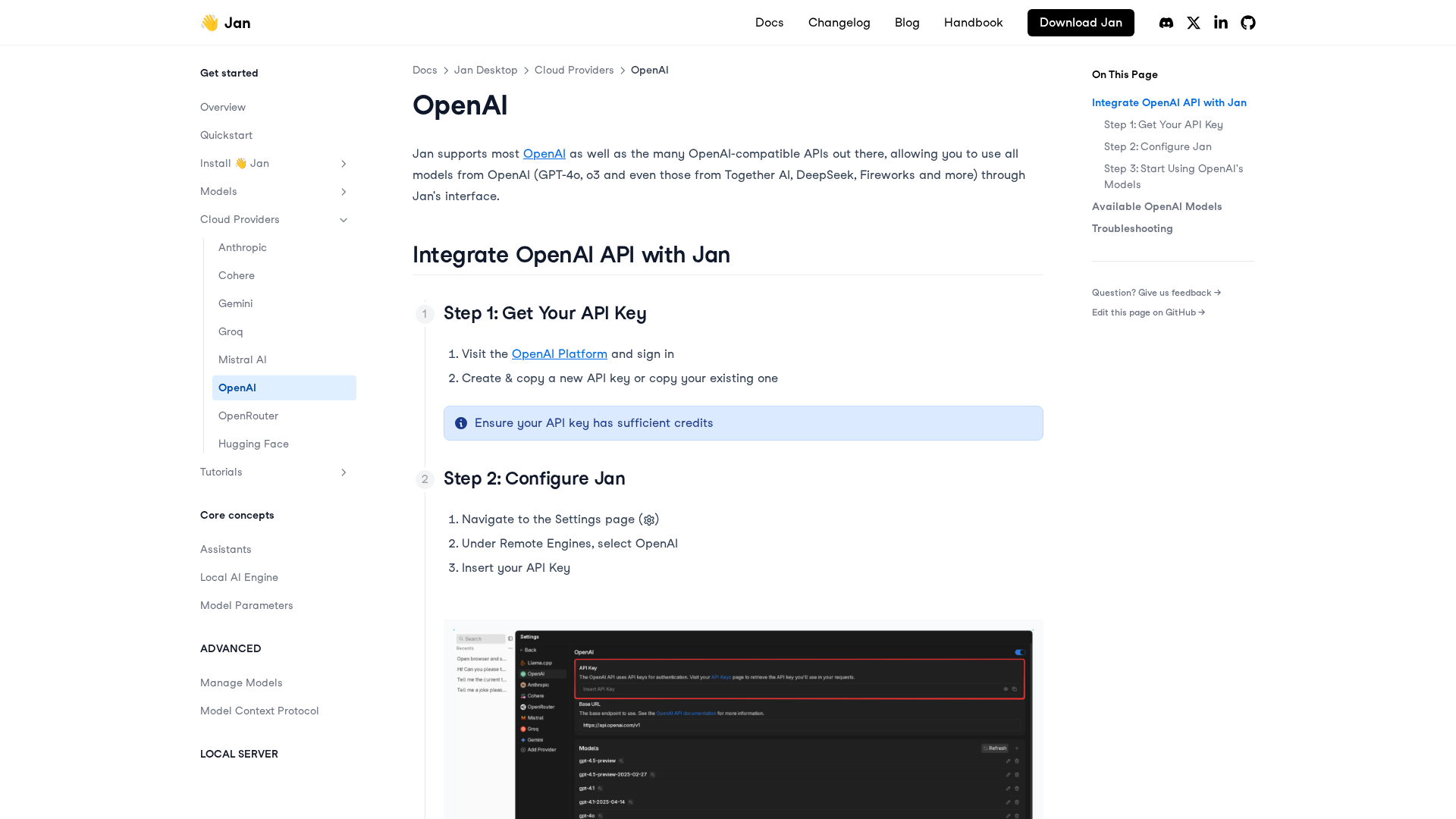
A practical, step-by-step guide to integrating OpenAI APIs with Jan for remote models, including setup, configuration, model selection, and troubleshooting.
...
LiveAction 25.3 launches LiveAssist AI Copilot, Network Resource Monitoring, and Security Insights for proactive, AI-driven NetOps.