Topic Overview
This topic examines the evolving landscape of AI accelerators and inference server platforms—spanning incumbent vendors (NVIDIA), specialized designs (Groq‑3 style pipelined accelerators), and vertically integrated chips from hyperscalers/OEMs (Meta‑class, Tesla‑class silicon). It focuses on how hardware architecture, power efficiency, and the supporting software stack shape deployment choices for Edge AI Vision Platforms and Decentralized AI Infrastructure. Relevance (2026): demand for real‑time multimodal inference, lower operational carbon intensity, and distributed/edge deployments has accelerated investment in purpose‑built inference silicon and server software. Outcomes are driven less by raw FLOPS and more by latency, deterministic throughput, energy per token/frame, and interoperability with cloud and edge orchestration layers. Key tools and roles: Rebellions.ai targets energy‑efficient inference with purpose‑built chiplets, SoCs and a GPU‑class software stack for hyperscale LLM and multimodal workloads; Vertex AI provides a managed cloud layer for model training, deployment and monitoring that abstracts underlying accelerators; Together AI offers an acceleration cloud and serverless inference APIs for fast inference, fine‑tuning and scalable training; Mistral AI supplies efficiency‑focused open models that enable lower compute and better fit to specialized silicon. Practical tradeoffs and trends: buyers must weigh architecture tradeoffs (throughput vs latency vs determinism), software ecosystem maturity (drivers, runtimes, model formats), and deployment targets (on‑vehicle/edge vision vs hyperscale inference). The market is moving toward tighter hardware–software co‑design, standards for model portability, and hybrid stacks that combine decentralized edge inference with cloud orchestration and model governance. Understanding these layers is essential for selecting the right accelerator and inference platform for specific edge and decentralized AI use cases.
Tool Rankings – Top 4
Energy-efficient AI inference accelerators and software for hyperscale data centers.
Unified, fully-managed Google Cloud platform for building, training, deploying, and monitoring ML and GenAI models.
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
Enterprise-focused provider of open/efficient models and an AI production platform emphasizing privacy, governance, and
Latest Articles (40)

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.
ProteanTecs expands in Japan with a new office and Noritaka Kojima as GM Country Manager.
...
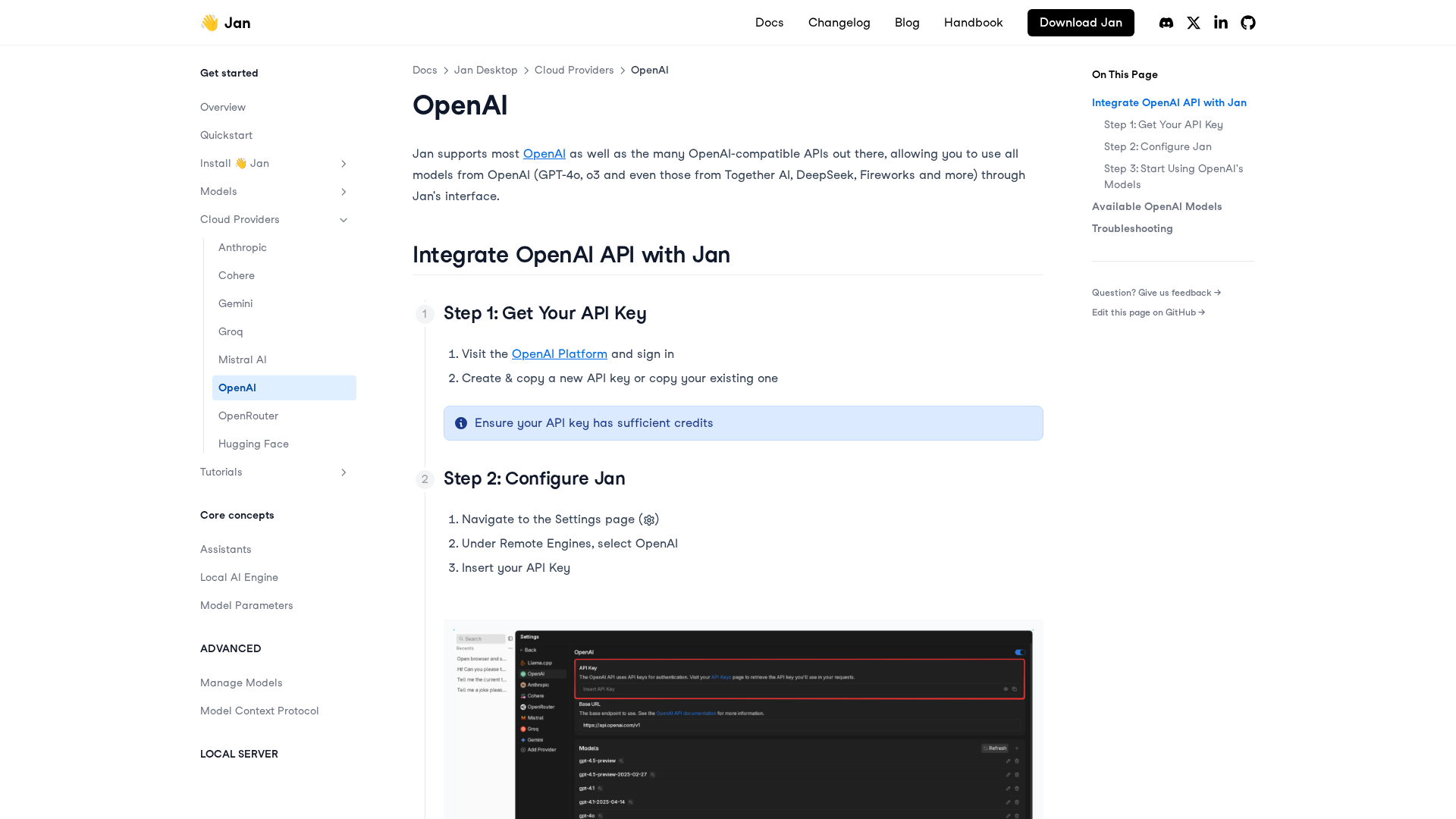
A practical, step-by-step guide to integrating OpenAI APIs with Jan for remote models, including setup, configuration, model selection, and troubleshooting.
LiveAction 25.3 launches LiveAssist AI Copilot, Network Resource Monitoring, and Security Insights for proactive, AI-driven NetOps.