Topic Overview
This topic compares modern inference chips and edge hardware from major vendors (NVIDIA plus in‑house silicon from Meta and Tesla, and Huawei’s accelerators) with a focus on Edge AI Vision Platforms and Decentralized AI Infrastructure. It covers the practical trade‑offs — latency, power, throughput, model compatibility, and deployment complexity — that determine whether inference runs in datacenters, on gateway devices, or fully on‑device at the edge. Relevance in 2026: specialized accelerators and model optimizations have proliferated, shifting many vision and LLM workloads off cloud GPUs into heterogeneous edge stacks. Enterprises now balance privacy and governance needs against cost and model fidelity; hybrid approaches (on‑device pre‑processing + cloud rerank/fallback) are common. Open and efficient models and production pipelines (e.g., Mistral AI’s enterprise models and platform) plus acceleration services (Together AI’s inference/fine‑tuning cloud) change which hardware choices are practical. Key tools and roles: Mistral AI — open, efficiency‑focused models and production tooling for private deployments; Cohere — enterprise LLMs, embeddings and retrieval services for secure customization; Together AI — end‑to‑end acceleration cloud for fast inference and scaling; StackAI and Anakin.ai — no‑code/low‑code platforms that simplify deploying and governing models across edge or cloud targets. These software layers interact with hardware toolchains (quantization, compilers, runtime frameworks) to unlock performance on different chips. This comparison emphasizes measurable criteria (TOPS/watt, model support, software ecosystem, security/partitioning), deployment patterns (edge vision nodes, gateway inference, decentralized fleets), and integration considerations that matter to architects choosing between NVIDIA, Meta, Tesla, and Huawei silicon.
Tool Rankings – Top 5
Enterprise-focused provider of open/efficient models and an AI production platform emphasizing privacy, governance, and

End-to-end no-code/low-code enterprise platform for building, deploying, and governing AI agents that automate work onun
Enterprise-focused LLM platform offering private, customizable models, embeddings, retrieval, and search.
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
A no-code AI platform with 1000+ built-in AI apps for content generation, document search, automation, batch processing,
Latest Articles (43)

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.

A practical, prompt-based playbook showing how Gemini 3 reshapes work, with a 90‑day plan and guardrails.
...
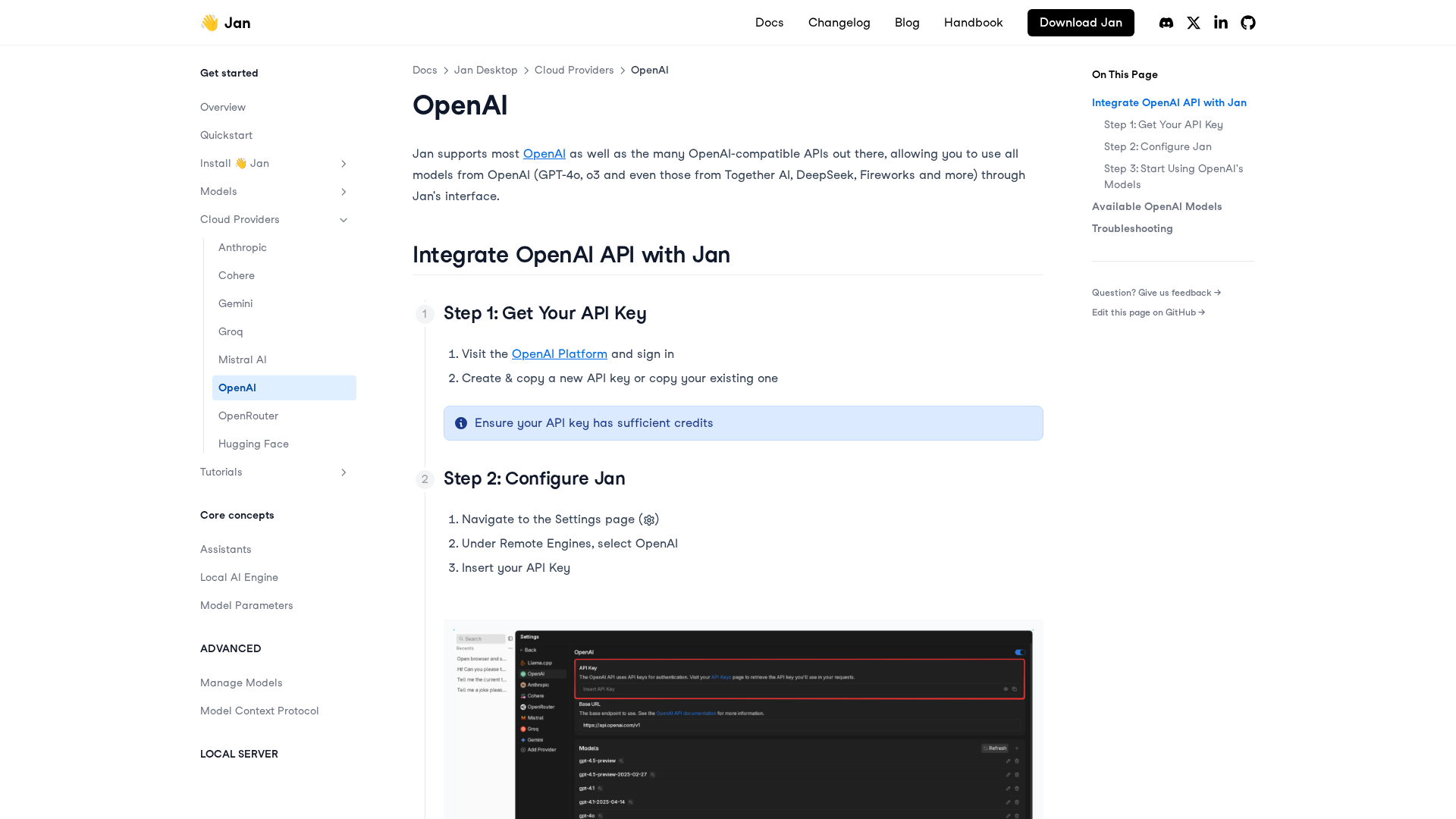
A practical, step-by-step guide to integrating OpenAI APIs with Jan for remote models, including setup, configuration, model selection, and troubleshooting.
A reflective dive into AI Mina’s imagined future driving, exploring companionship, memory-making, and the evolving role of cars in human life.