Topic Overview
AI voice cloning and deepfake detection cover the technologies that create, transcribe, deploy and verify synthetic speech. By 2026, production‑grade text‑to‑speech (TTS) and voice cloning are widely used for media, customer service and accessibility, while parallel advances in detection and provenance tools aim to manage fraud, misinformation and privacy risk. Key categories include voice synthesis and transcription (real‑time TTS, emotion control, multilingual support) and AI content detectors (forensic audio analysis, watermarking and model‑level signatures). Representative tools illustrate the landscape: ElevenLabs provides expressive TTS, high‑fidelity voice cloning, transcription and voice agents geared toward production use; Smallest.ai emphasizes low‑latency, hyper‑realistic TTS with emotion control and a growing accent and language set; ACE‑Step focuses on fast, coherent generative audio for music (relevant where audio authenticity matters); Vocea and Sophie deploy voice agents and automated phone assistants for service providers and SMEs, streamlining booking and lead qualification. Contemporary trends driving relevance include broader deployment of voice agents in business workflows, improvements in multilingual and emotional synthesis, and increasing misuse of synthetic voices in fraud and manipulation. Detection approaches have matured into multi‑layered strategies: embedded watermarks and provenance metadata, acoustic and statistical forensics, speech‑to‑text cross‑checks, and specialized AI detectors. Organizations need integrated workflows—combining detection, consent/verification processes, secure logging and user education—to balance innovation with risk mitigation. This topic is essential for developers, compliance teams and content platforms navigating the technical and policy challenges of synthetic audio in 2026.
Tool Rankings – Top 5
Industry-leading AI audio platform for ultra-realistic text-to-speech, voice cloning, transcription, and voice agents.
Hyper-realistic AI voiceovers
Fast, high-coherence AI music, now more accessible
AI Voice Assistant for Service Providers

24×7 AI voice operator that qualifies leads, books meetings
Latest Articles (33)
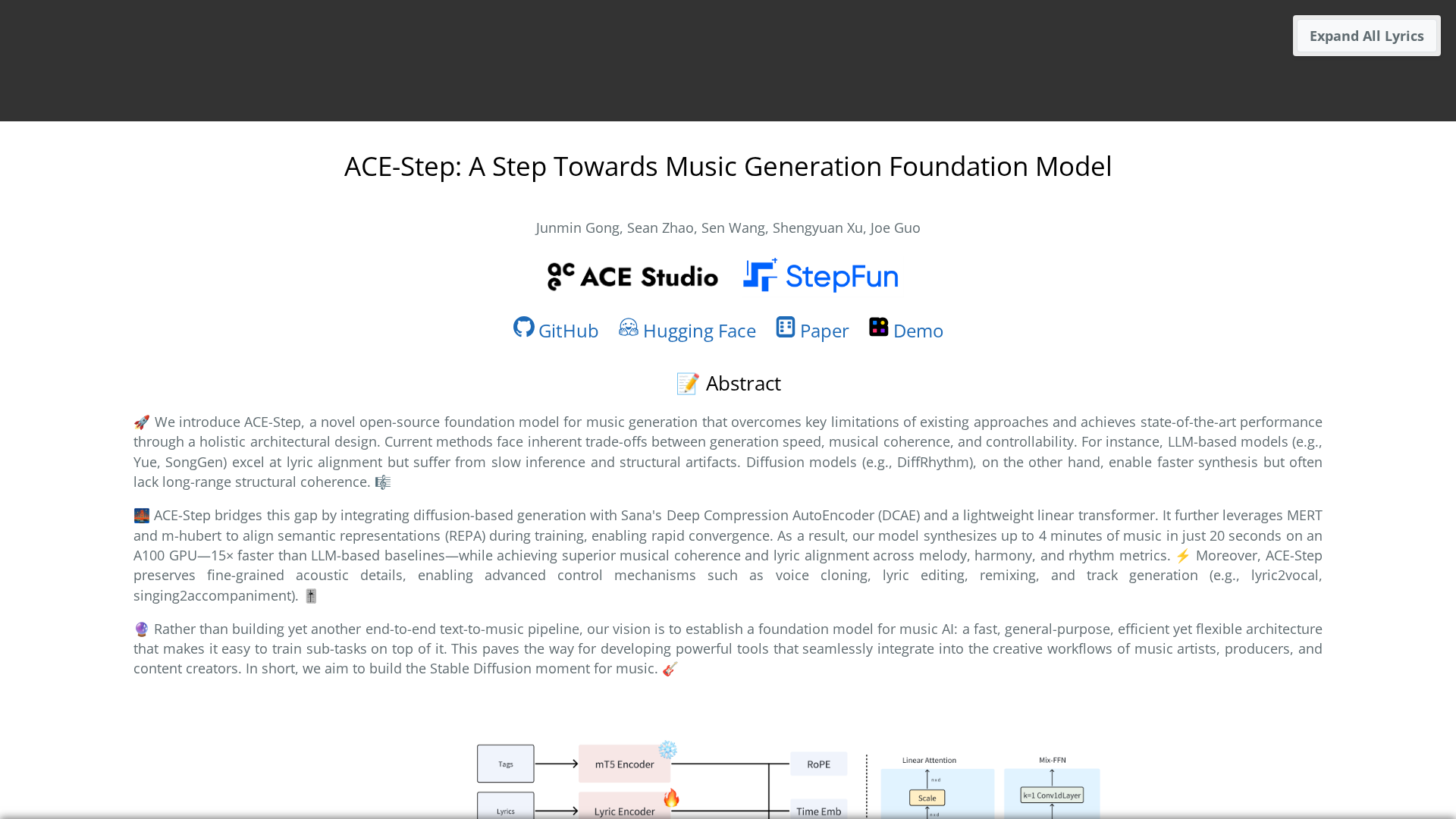
Open-source foundation model for fast, coherent, and controllable music generation blending diffusion, DCAE, and lightweight transformers.
ACE-StepとComfyUIのネイティブおよびカスタムノードで多言語対応の音楽生成を解説するチュートリアル
A practical guide to implementing ACE-Step in ComfyUI using native and custom nodes, including multilingual inputs, LoRA, and prompts.
A practical tutorial comparing native and custom-node ACE-Step workflows in ComfyUI, with multilingual input and step-by-step usage.
Early Ace-Step 1.5 preview focusing on fast setup and new features.