Topic Overview
This topic covers on‑device LoRA (Low‑Rank Adaptation) and edge training frameworks that enable parameter‑efficient fine‑tuning and localized learning for billion‑parameter models. As model architectures scale, techniques such as LoRA, quantization, distillation and sparsity make it feasible to adapt large models on phones, gateways and localized edge servers without full retraining. This matters in 2026 because improved mobile/edge accelerators, standardized low‑precision runtimes, and increasing regulatory and enterprise privacy requirements are driving demand for decentralized model adaptation and low‑latency personalization. Key tools and platform roles: Together AI provides cloud and hybrid acceleration for fast inference, fine‑tuning and scalable GPU training—useful when edge workflows require staged cloud-to-edge pipelines. Mistral AI supplies efficient open foundation models and production tooling focused on privacy and governance, making their models good targets for on‑device LoRA and secure edge deployments. Cohere offers enterprise LLM services (customizable models, embeddings, retrieval) that can pair with edge adapters for private, searchable deployments. No‑code/low‑code platforms such as Anakin.ai and StackAI accelerate application assembly, batch processing and governance for edge agents and workflows, lowering the integration burden for non‑ML teams. Developer tooling like Amazon CodeWhisperer (now in Amazon Q Developer) helps engineers generate and optimize code for deployment, model adapters and runtime integration. Practical considerations include memory and compute budgets, communication cost for decentralized updates (federated or P2P), quantization compatibility with LoRA adapters, and governance/traceability. Evaluations should weigh on‑device latency and privacy gains against accuracy drift and orchestration complexity. The most effective deployments combine lightweight on‑device adapters with cloud or hub‑based orchestration to balance performance, privacy and manageability.
Tool Rankings – Top 6
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
Enterprise-focused provider of open/efficient models and an AI production platform emphasizing privacy, governance, and
A no-code AI platform with 1000+ built-in AI apps for content generation, document search, automation, batch processing,
Enterprise-focused LLM platform offering private, customizable models, embeddings, retrieval, and search.

End-to-end no-code/low-code enterprise platform for building, deploying, and governing AI agents that automate work onun
AI-driven coding assistant (now integrated with/rolling into Amazon Q Developer) that provides inline code suggestions,
Latest Articles (50)

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.

A practical, prompt-based playbook showing how Gemini 3 reshapes work, with a 90‑day plan and guardrails.
...
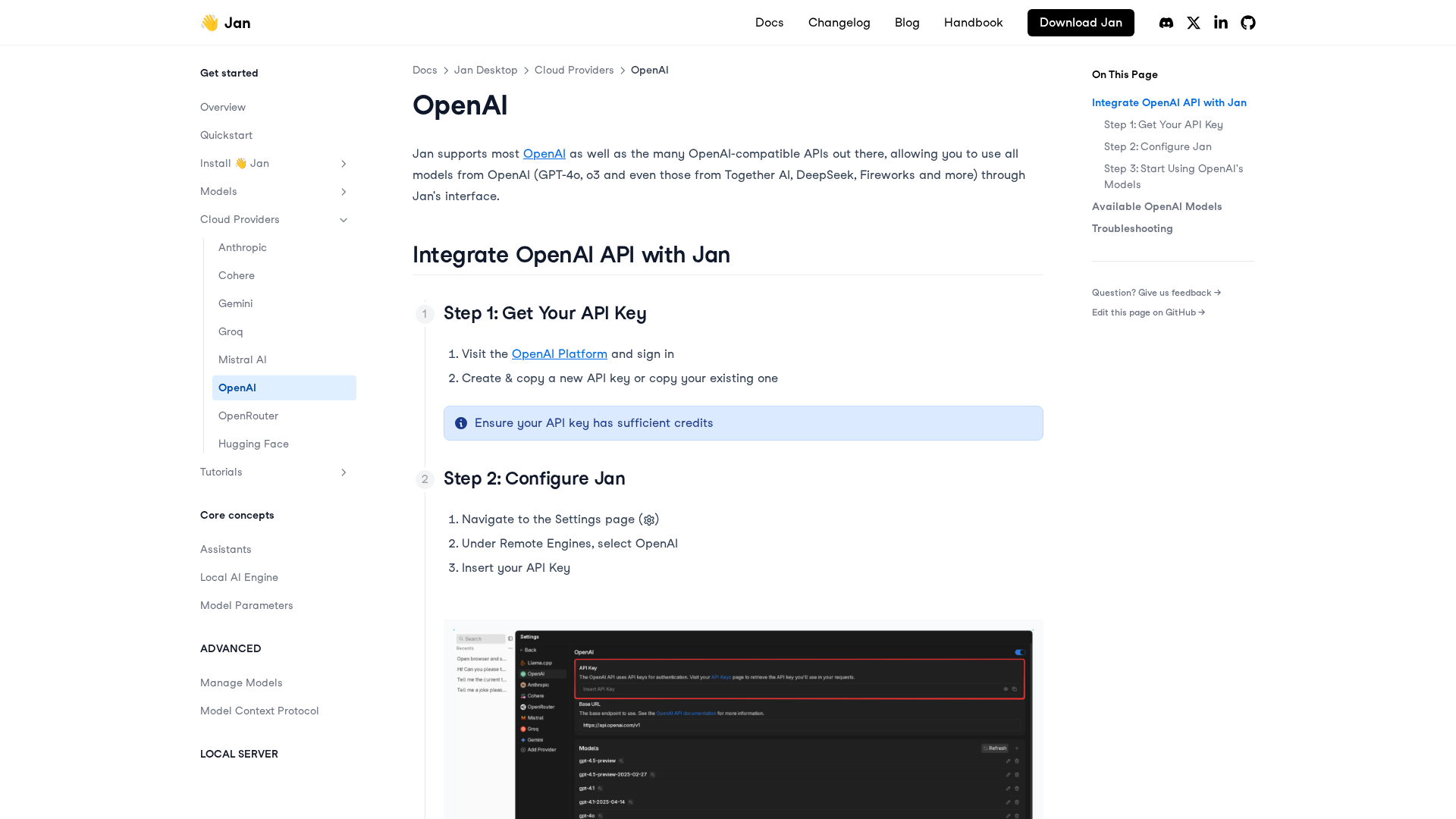
A practical, step-by-step guide to integrating OpenAI APIs with Jan for remote models, including setup, configuration, model selection, and troubleshooting.
A reflective dive into AI Mina’s imagined future driving, exploring companionship, memory-making, and the evolving role of cars in human life.