Topic Overview
This topic examines custom AI accelerators — exemplified by the Taalas HC1 — and the emerging class of edge inference chips that enable real‑time vision and on‑device AI. Edge AI vision platforms increasingly push compute out of the cloud to meet strict latency, bandwidth, power, and privacy requirements for use cases such as video analytics, robotics, AR, and industrial inspection. Next‑gen chips focus on high performance per watt, mixed‑precision math, model‑specific kernels and integrated NPUs/TPUs, while the software stack (compilers, quantization, runtimes) determines practical model support and deployment ease. Relevance (Feb 24, 2026): momentum toward heterogeneous, software‑hardware co‑design has accelerated as open and efficient models proliferate and enterprises demand private, cost‑predictable inference at the edge. Vendors and platforms now span hardware, orchestration, and model supply: Mistral AI supplies open, efficiency‑focused foundation models and enterprise tooling for governance and private deployments; Together AI offers a full‑stack acceleration cloud and serverless inference APIs for scalable low‑latency serving; Vertex AI provides an end‑to‑end managed stack for training, deployment, and model discovery; Cohere focuses on private, customizable LLMs, embeddings and retrieval; and Anakin.ai packages many no‑code AI apps for rapid prototyping and batch workflows. Key considerations when comparing accelerators include supported model formats (ONNX, TensorRT, MLIR), quantization/accuracy tradeoffs, thermal/power profiles, software toolchain maturity, and integration with enterprise governance and orchestration platforms. Selecting between custom chips like the HC1 and alternative silicon depends on workload shape (vision model size, frame rate), deployment constraints, and the surrounding software ecosystem for model optimization and secure, monitored inference.
Tool Rankings – Top 5
Enterprise-focused provider of open/efficient models and an AI production platform emphasizing privacy, governance, and
A no-code AI platform with 1000+ built-in AI apps for content generation, document search, automation, batch processing,
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
Unified, fully-managed Google Cloud platform for building, training, deploying, and monitoring ML and GenAI models.
Enterprise-focused LLM platform offering private, customizable models, embeddings, retrieval, and search.
Latest Articles (47)

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.

A practical, prompt-based playbook showing how Gemini 3 reshapes work, with a 90‑day plan and guardrails.
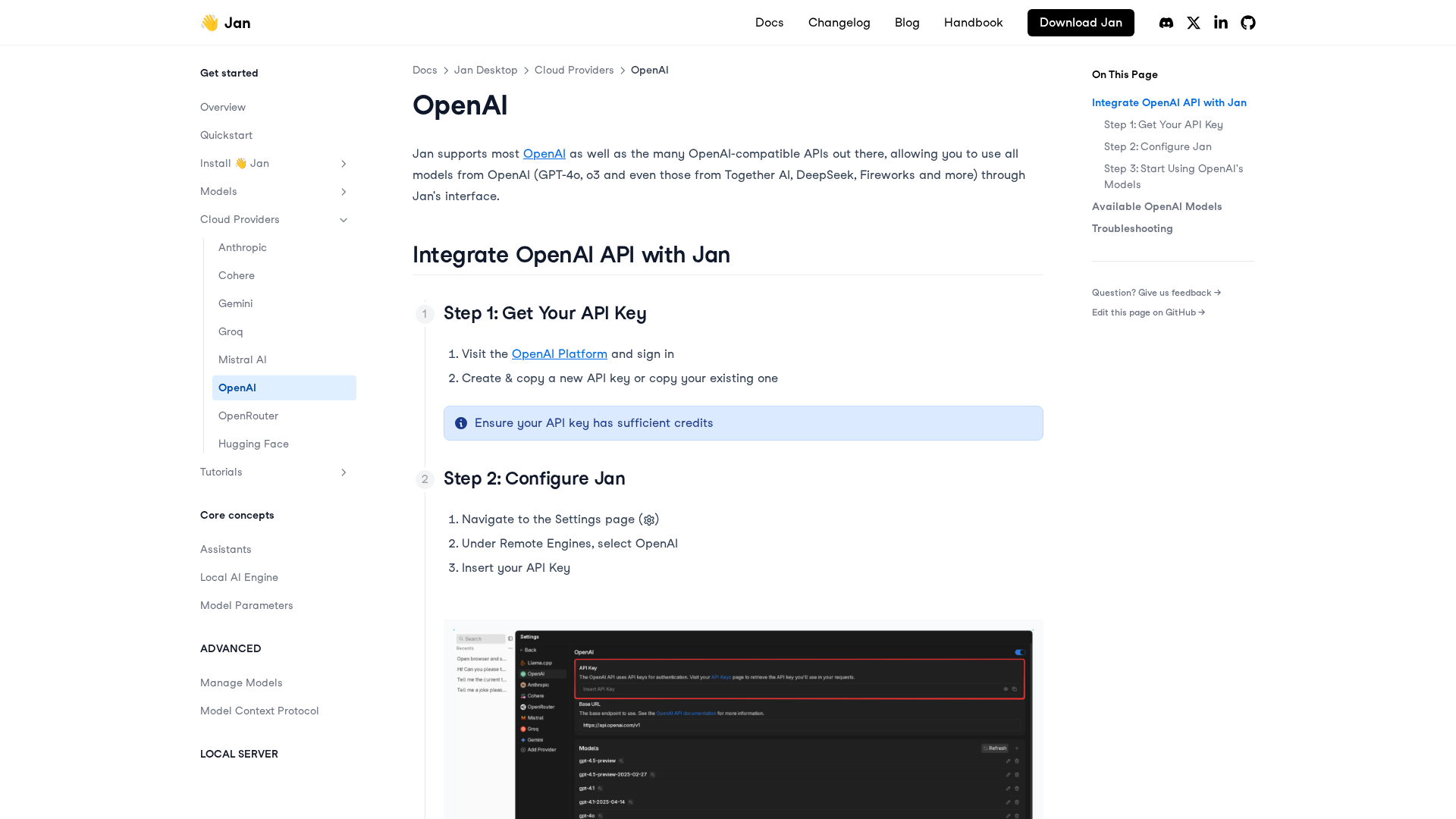
A practical, step-by-step guide to integrating OpenAI APIs with Jan for remote models, including setup, configuration, model selection, and troubleshooting.
...
LiveAction 25.3 launches LiveAssist AI Copilot, Network Resource Monitoring, and Security Insights for proactive, AI-driven NetOps.