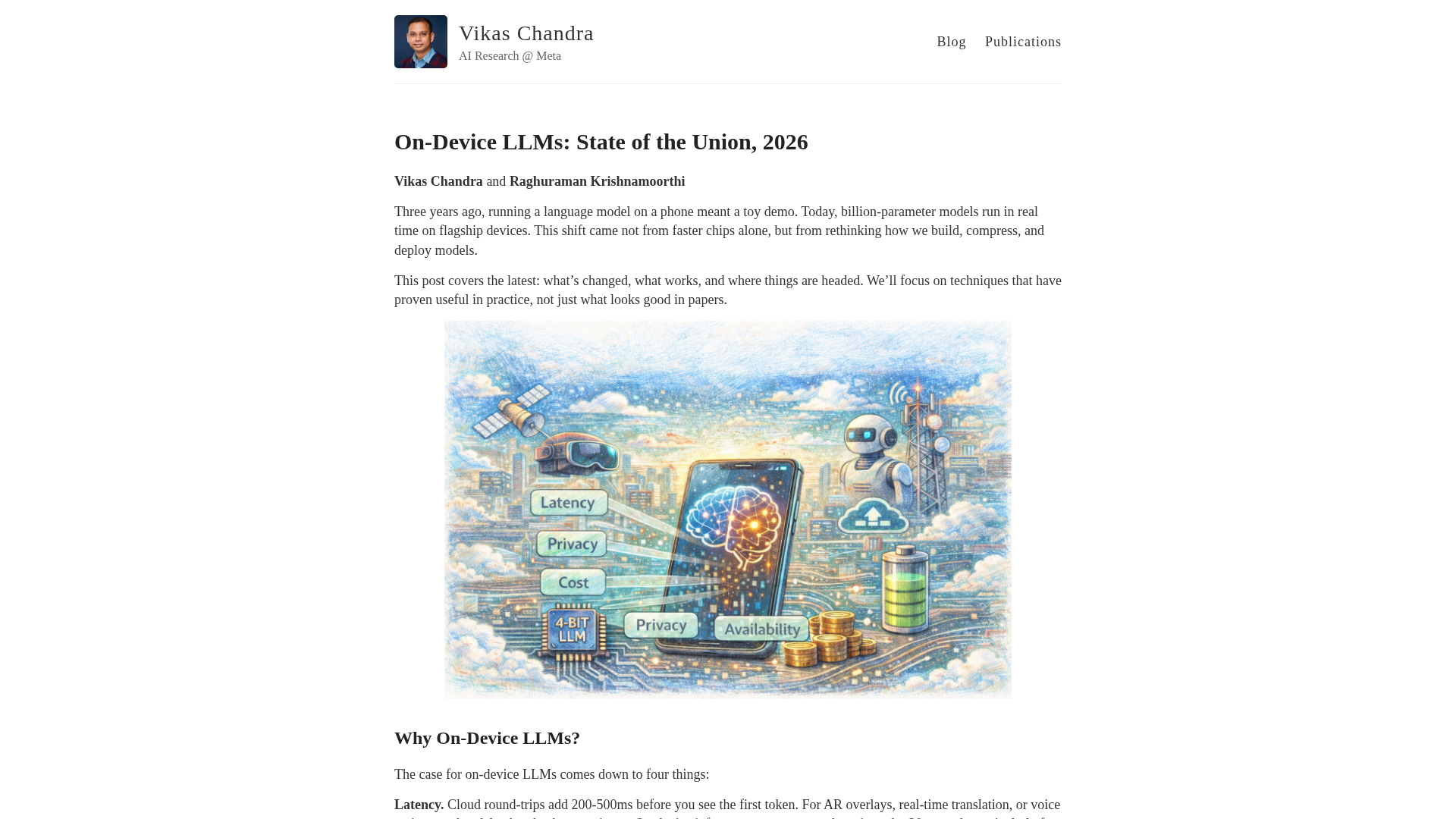
Topic Overview
This topic covers combining low‑rank adaptation (LoRA) with low‑bit inference runtimes (here called “BitNet” frameworks) to enable fine‑tuning and serving of billion‑parameter models directly on consumer and edge devices. LoRA adapters let developers personalize large models by adding and training small, efficient delta matrices instead of updating full weights; BitNet-style quantization/runtime stacks reduce memory and compute by representing activations and weights in few bits and optimizing kernels for on‑device accelerators. Together these techniques make it possible to run, adapt, and iterate on otherwise large models with far lower resource cost. The approach is timely in 2026 because device hardware, model architectures, and ecosystem tooling have matured toward local‑first AI: code‑specialized models like Code Llama, local notebooks and note agents (Znote, Remio), privacy‑focused context builders (EchoComet), and engineering platforms and agent frameworks (LangChain, AutoGPT, Aider) all push workloads toward client or hybrid edge/cloud execution. Integrating LoRA and BitNet lets coding assistants, code review agents (Bito, Qodo), and multi‑repo developer tooling run with lower latency, better privacy, and simpler update flows. Practical trade‑offs are central: adapter fidelity vs. base‑model quality, and accuracy vs. bit‑width in quantization. Tooling maturity—standardized adapter formats, robust quantized kernels, and orchestration layers from agent frameworks—determines how easily organizations can adopt on‑device loops. For practitioners, the pattern is clear: use a compact base (e.g., Code Llama), deploy LoRA adapters for personalization, run on a BitNet‑style quantized runtime, and orchestrate behavior with agent frameworks (LangChain, AutoGPT) to build responsive, private, and maintainable developer and agent applications.
Tool Rankings – Top 6
Code-specialized Llama family from Meta optimized for code generation, completion, and code-aware natural-language tasks
Continue your ChatGPT chats inside smart notes
Feed your code context directly to AI

Quality-first AI coding platform for context-aware code review, test generation, and SDLC governance across multi-repo,팀
AI-powered, codebase-aware code review agent that provides PR summaries, line-by-line reviews, suggested fixes, and an R
Open-source AI pair-programming tool that runs in your terminal and browser, pairing your codebase with LLM copilots to:
Latest Articles (63)
EchoComet's contact page provides fast support, license recovery, and device limits for macOS.
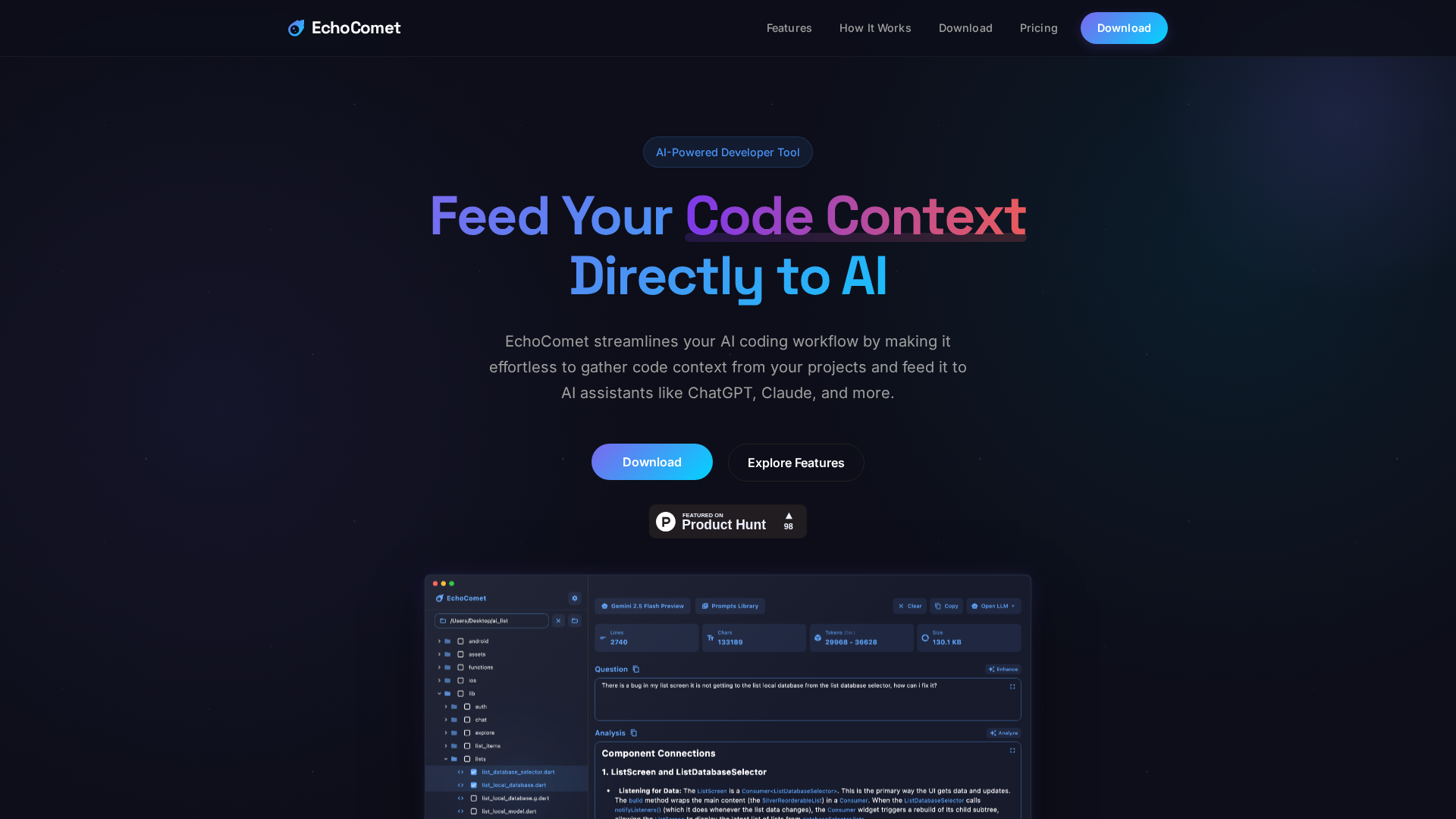
EchoComet lets you gather code context locally and feed it to AI with large-context prompts for smarter, private AI assistance.
Analyzes why the Nvidia–OpenAI $100B deal is not binding yet and what that means for investors.
A provocative analysis of Moltbook AI’s machine-only subculture, governance, and security implications.
Explains the Jan 2026 Linux kernel continuity plan and how it reshapes governance if the top maintainer can’t lead.