Topic Overview
Multimodal audio AI combines speech-to-text, text-to-speech (TTS), voice cloning, real‑time voice agents, and music generation to automate and scale spoken‑word and musical content. This topic covers platforms and tools that produce, transform, transcribe, and commercialize audio across use cases such as podcasts, localized dubbing, meeting intelligence, voice assistants, and original music production. Key categories include Voice Synthesis and Transcription, Text-to-Speech Tools, AI Music Creation Tools, Audio Asset Marketplaces, and Conversation Intelligence Tools. Representative platforms illustrate the range of capabilities: ElevenLabs offers production‑grade expressive TTS, high‑fidelity voice cloning, and speech transcription with deployment options for voice agents; Podcastle (Async) provides an all‑in‑one studio for recording, multi‑track editing, dubbing, and cloning focused on spoken‑word workflows; Murf AI delivers a cloud TTS studio and APIs with multilingual voices for dubbing and real‑time integrations; Krisp centers on meeting audio quality, noise suppression and live transcription; Prolumios and similar meeting assistants extract outcomes and insights from calls; EchoPod automates article-to‑podcast production; open‑source projects like ACE‑Step and Voila expand access to fast music synthesis and low‑latency expressive voice models. As adoption grows, considerations such as audio fidelity, latency, multilingual support, licensing, privacy/consent for cloned voices, model provenance, and API and workflow integration have become central. The landscape is shaped by a mix of production‑grade commercial services and increasingly capable open‑source models, making it timely for content creators, product teams, and enterprises to evaluate tradeoffs between quality, control, cost, and compliance when choosing tools.
Tool Rankings – Top 6
Industry-leading AI audio platform for ultra-realistic text-to-speech, voice cloning, transcription, and voice agents.

A single AI platform to record, edit, dub, subtitle, clip, and clone voices for audio, video, and voice content.

Realistic AI text-to-speech, dubbing, and voice APIs with 200+ voices and multilingual support.
AI audio/meeting platform for noise cancellation, real-time transcription, meeting notes, accent conversion, and voice/音
Revolutionize your meetings with prolumios
Transform written content into captivating AI podcasts
Latest Articles (25)
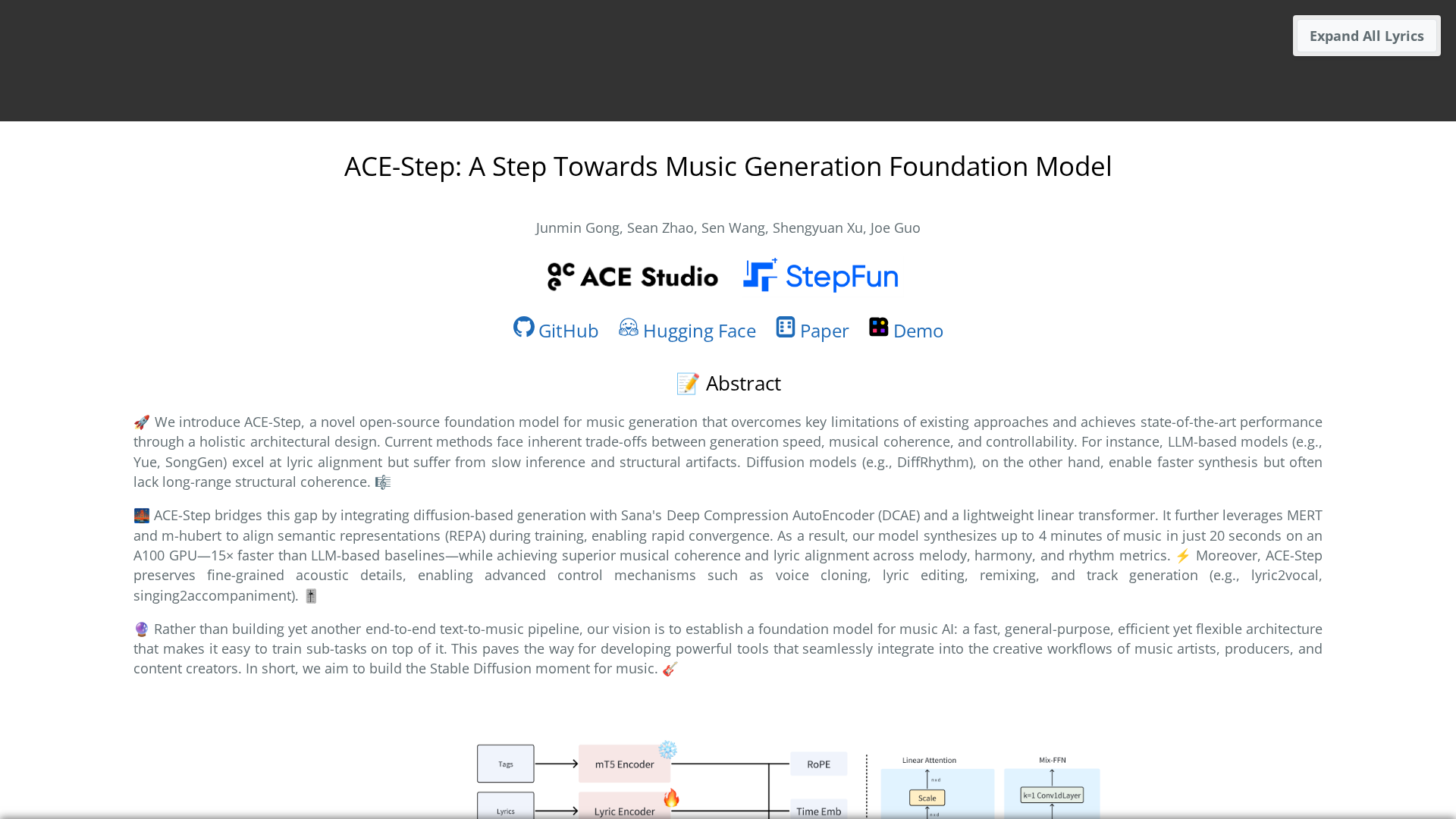
Open-source foundation model for fast, coherent, and controllable music generation blending diffusion, DCAE, and lightweight transformers.
ACE-StepとComfyUIのネイティブおよびカスタムノードで多言語対応の音楽生成を解説するチュートリアル
A practical guide to implementing ACE-Step in ComfyUI using native and custom nodes, including multilingual inputs, LoRA, and prompts.
A practical tutorial comparing native and custom-node ACE-Step workflows in ComfyUI, with multilingual input and step-by-step usage.
Early Ace-Step 1.5 preview focusing on fast setup and new features.