Topic Overview
Cost‑optimized AI inference and specialized compute providers focus on reducing the money, latency, and energy required to run large language and multimodal models in production. By 2026, model sizes and usage patterns have pushed inference costs and power consumption into the foreground, driving adoption of heterogeneous hardware, software stacks that squeeze more throughput from each watt, and deployment patterns that place compute where it’s cheapest or fastest (cloud, on‑prem, edge or decentralized pools). Key providers typify these trends: Together AI offers an end‑to‑end acceleration cloud with scalable GPU training, fine‑tuning, and serverless inference APIs for consumption‑based deployment; Rebellions.ai builds energy‑efficient inference accelerators (chiplets, SoCs and server designs) plus a GPU‑class software stack aimed at hyperscale throughput and lower power per token; Cohere provides enterprise‑grade LLMs and tooling—private, customizable models, embeddings and retrieval services—that let organizations trade model specialization for lower downstream cost. Across categories—decentralized AI infrastructure, edge AI vision platforms, and AI tool marketplaces—cost optimization is achieved by matching model architecture, quantization and compiler techniques to specialized hardware; by moving inference to regional or edge nodes to cut bandwidth and latency; and by using marketplaces or pooled infrastructure to access spot or specialized accelerators. Operational priorities include predictable billing models, compliance for private models, energy efficiency and workload orchestration. This topic matters now because operational scale and sustainability concerns are reshaping architecture decisions: choosing the right mix of specialized accelerators, serverless inference, and enterprise model services can materially reduce total cost of ownership while meeting latency, privacy and energy goals.
Tool Rankings – Top 3
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
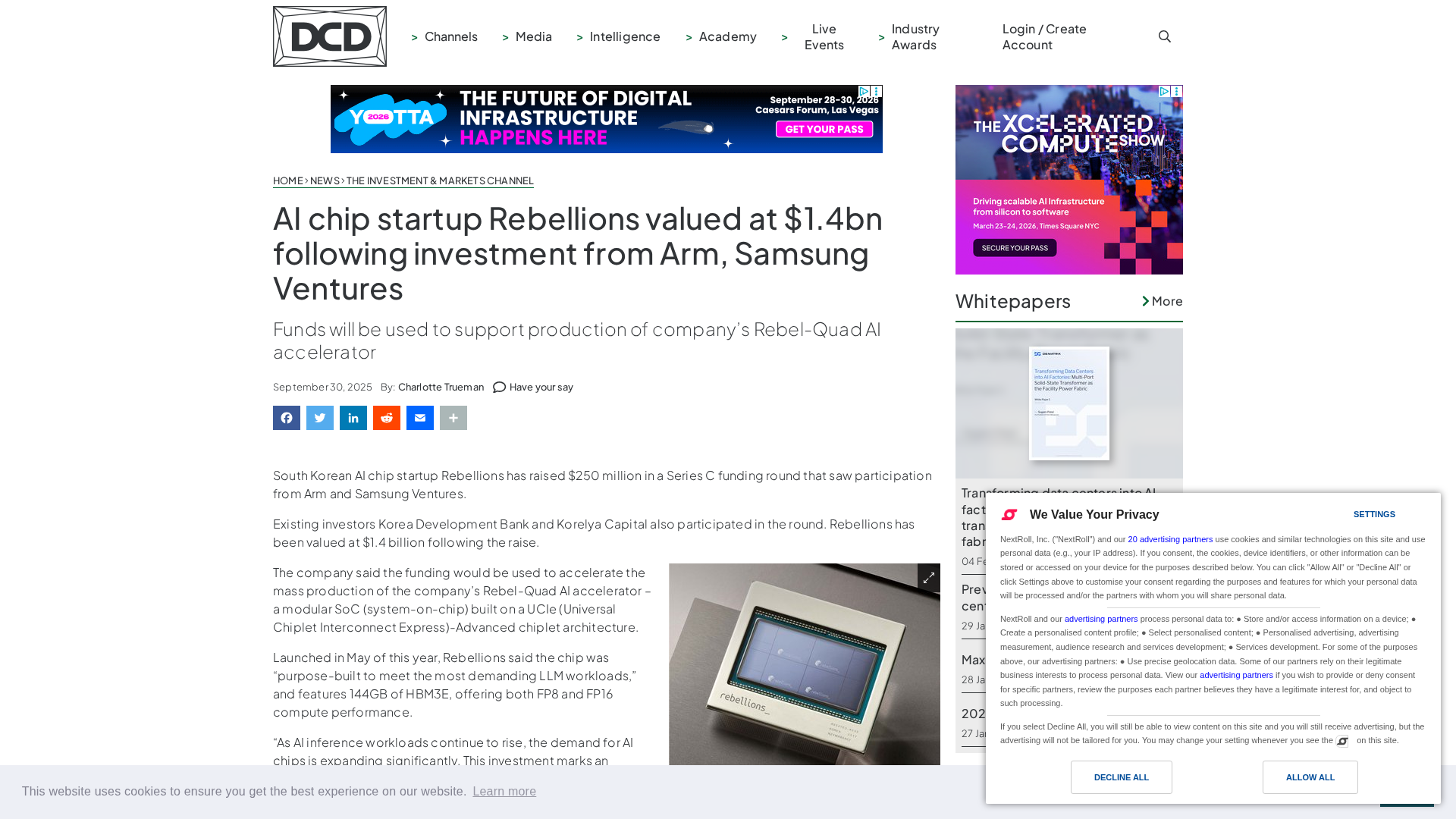
Energy-efficient AI inference accelerators and software for hyperscale data centers.
Enterprise-focused LLM platform offering private, customizable models, embeddings, retrieval, and search.
Latest Articles (38)

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.

A practical, prompt-based playbook showing how Gemini 3 reshapes work, with a 90‑day plan and guardrails.
ProteanTecs expands in Japan with a new office and Noritaka Kojima as GM Country Manager.
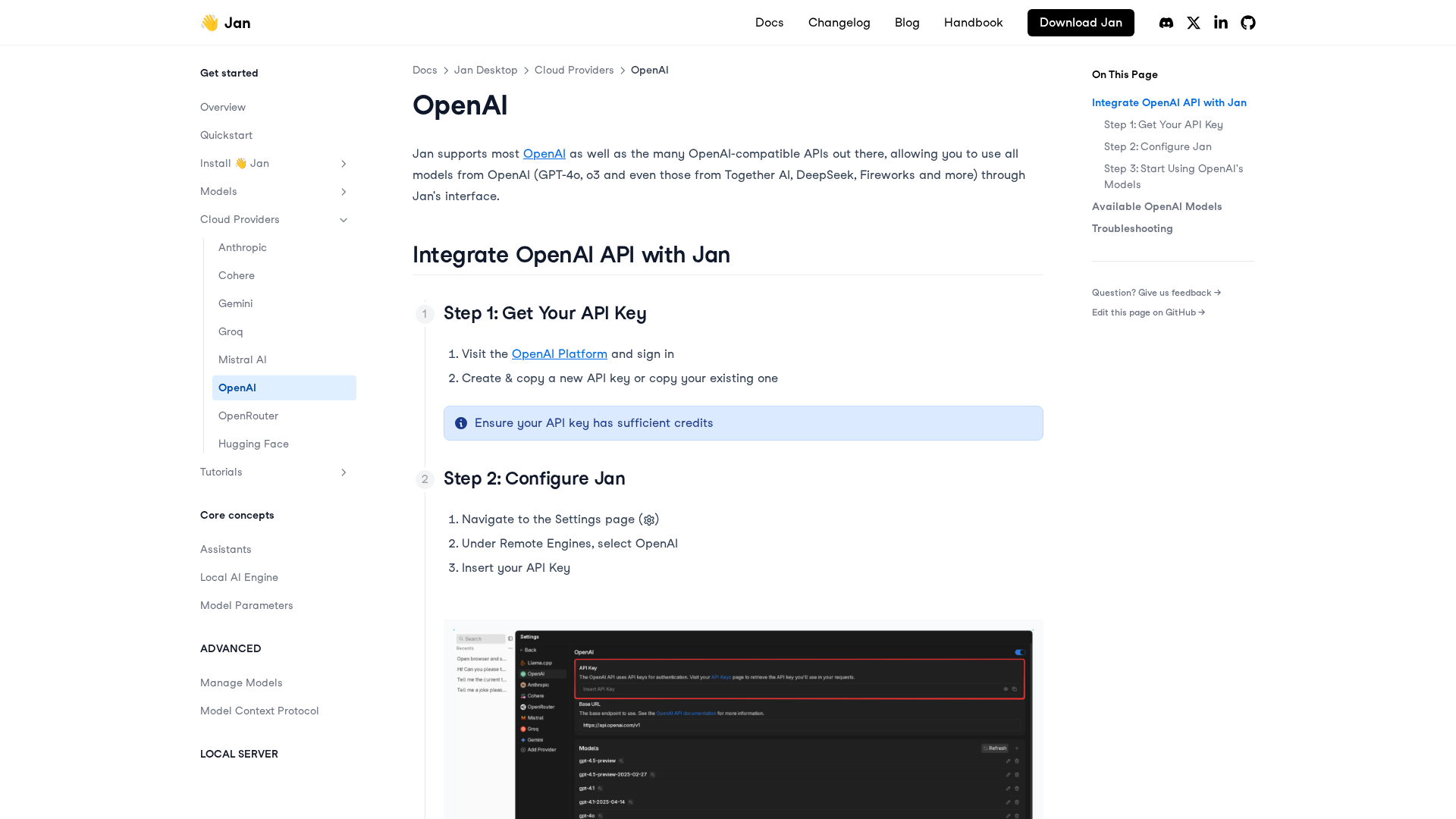
A practical, step-by-step guide to integrating OpenAI APIs with Jan for remote models, including setup, configuration, model selection, and troubleshooting.
...