Topic Overview
This topic covers LLM features and products that perform model inference on local hardware—commonly called “use your computer” or on‑device AI—and the surrounding ecosystem for decentralized, privacy‑sensitive, and latency‑critical applications. Demand for local compute has grown as organizations and individuals balance data governance, offline operation, and cost control: regulators and enterprises increasingly require private processing, developers need low-latency in‑IDE assistance, and edge vision and personal assistant use cases often cannot rely on cloud connectivity. Key tools illustrate complementary approaches. Stable Code (Stability AI) and Code Llama (Meta) are code‑specialized model families optimized for fast, instruction‑tuned code completion and infilling; their smaller 3B‑class variants and quantization make local deployment feasible. nlpxucan/WizardLM provides open‑source instruction‑following weights useful for self‑hosting and customization. EchoComet and Tabnine emphasize privacy and context: EchoComet assembles and processes project context entirely on the developer’s device, while Tabnine targets enterprise self‑hosted deployments and governance. In‑IDE integrations like JetBrains AI Assistant and code review agents such as Bito show how local inference and private context improve developer workflows—providing context‑aware completion, refactorings, PR summaries, and suggested fixes without sending code to third‑party servers. The trend is pragmatic: tradeoffs include model size and capability versus hardware requirements and integration effort. Advances in model quantization, smaller but capable architectures, and instruction tuning are making local LLMs a practical option for decentralized AI infrastructure, personal assistants that keep data on‑device, and edge AI vision platforms that must operate offline or with strict privacy constraints.
Tool Rankings – Top 6

Edge-ready code language models for fast, private, and instruction‑tuned code completion.
Feed your code context directly to AI
Code-specialized Llama family from Meta optimized for code generation, completion, and code-aware natural-language tasks

Open-source family of instruction-following LLMs (WizardLM/WizardCoder/WizardMath) built with Evol-Instruct, focused on

Enterprise-focused AI coding assistant emphasizing private/self-hosted deployments, governance, and context-aware code.
In‑IDE AI copilot for context-aware code generation, explanations, and refactorings.
Latest Articles (29)
EchoComet's contact page provides fast support, license recovery, and device limits for macOS.
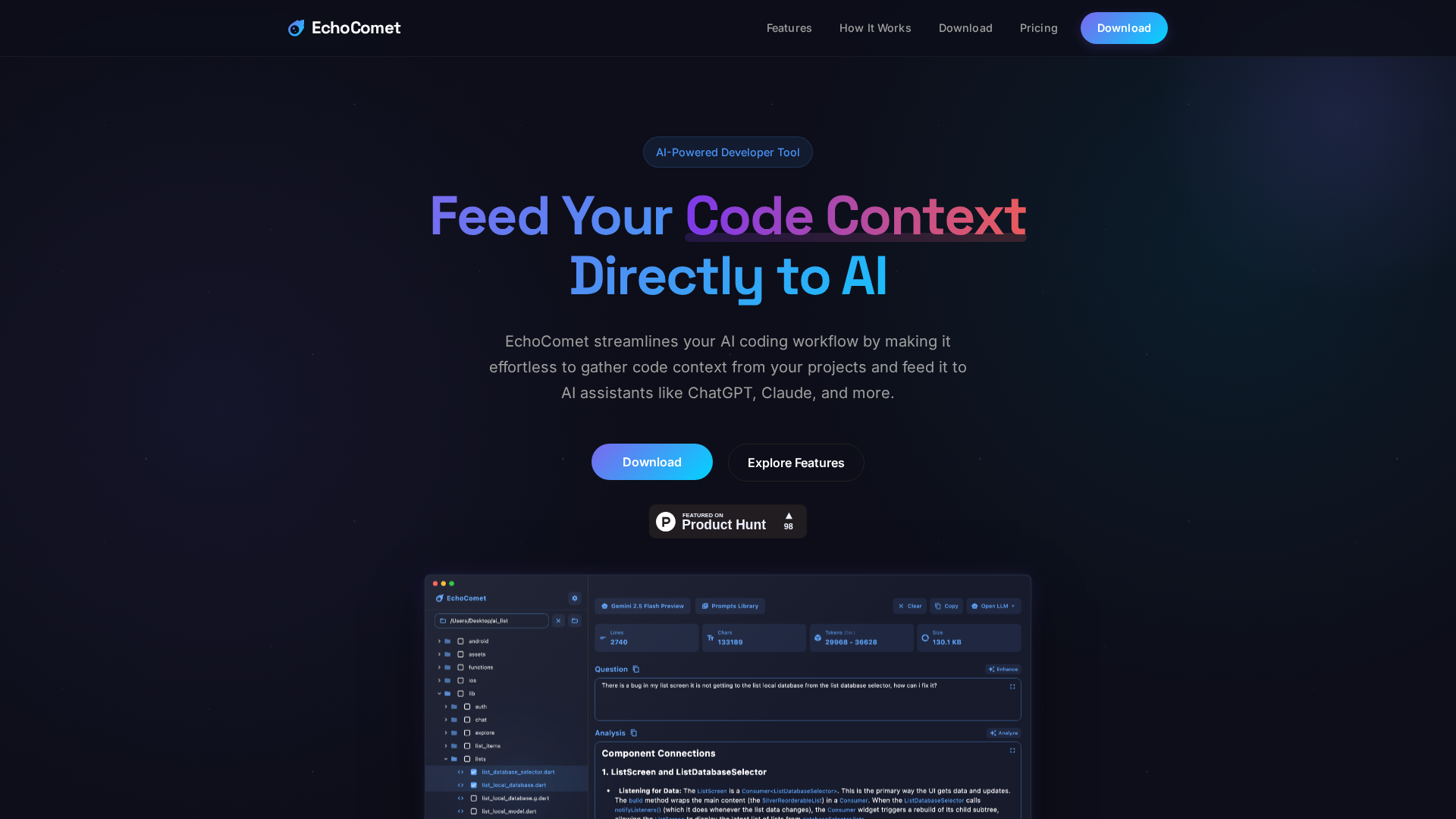
EchoComet lets you gather code context locally and feed it to AI with large-context prompts for smarter, private AI assistance.

Adobe nears a $19 billion deal to acquire Semrush, expanding its marketing software capabilities, according to WSJ reports.
AI-powered coding assistant integrated into IntelliJ IDEs to generate code, explain concepts, and streamline development.
Adobe’s Semrush acquisition signals a major AI-driven shift and potential consolidation in SEO tools.