
Topic Overview
This topic examines the emerging generation of foundation models—commonly framed as GPT‑5 and successors to GPT‑4o—focusing on their architectural advances, multimodal and code‑centric capabilities, and how they are measured by contemporary benchmarks. As of 2026, organizations and developer platforms are shifting from model‑only comparisons to system‑level evaluation that incorporates inference cost, safety, retrieval augmentation, and test automation. That makes rigorous benchmarking (e.g., MMLU, MT‑Bench, HumanEval and specialized code tests) central to choosing models for production. Key tool categories and examples illustrate how next‑gen models are being applied: Code Llama, Salesforce CodeT5 and StarCoder represent code‑specialized LLMs and research releases optimized for generation, infilling, and program understanding; Amazon CodeWhisperer (now integrated into Amazon Q Developer) and Phind demonstrate developer‑centric integrations that surface model assistance and multimodal search; Qodo (formerly Codium) exemplifies quality‑first pipelines for automated code review, test generation, and governance across repos. These tools show the growing demand for models tuned for software engineering workflows and test automation. Current trends emphasize hybrid evaluation (benchmarks + real‑world synthetic workloads), modular tool use (RAG, tool invocation), efficient deployment (quantization, sparse/dense inference tradeoffs), and transparency around data and safety. For researchers and platform teams, the priority is not only raw capability but reproducible benchmarks, fine‑tuning and instruction cascades for code, and integrated data platforms that track performance and risks. This overview helps technical decision‑makers compare next‑gen foundation models by features, deployment constraints, and the practical benchmarks that matter in production AI stacks.
Tool Rankings – Top 6
Code-specialized Llama family from Meta optimized for code generation, completion, and code-aware natural-language tasks

Official research release of CodeT5 and CodeT5+ (open encoder–decoder code LLMs) for code understanding and generation.
StarCoder is a 15.5B multilingual code-generation model trained on The Stack with Fill-in-the-Middle and multi-query ува
AI-driven coding assistant (now integrated with/rolling into Amazon Q Developer) that provides inline code suggestions,

Quality-first AI coding platform for context-aware code review, test generation, and SDLC governance across multi-repo,팀
AI-powered search for developers that returns visual, interactive, and multimodal answers focused on coding queries.
Latest Articles (40)
A step-by-step guide to building an AI-powered Reliability Guardian that reviews code locally and in CI with Qodo Command.
A developer chronicles switching to Zed on Linux, prototyping on a phone, and a late-night video correction.
A comprehensive releases page for VSCodium with multi-arch downloads and versioned changelogs across 1.104–1.106 revisions.
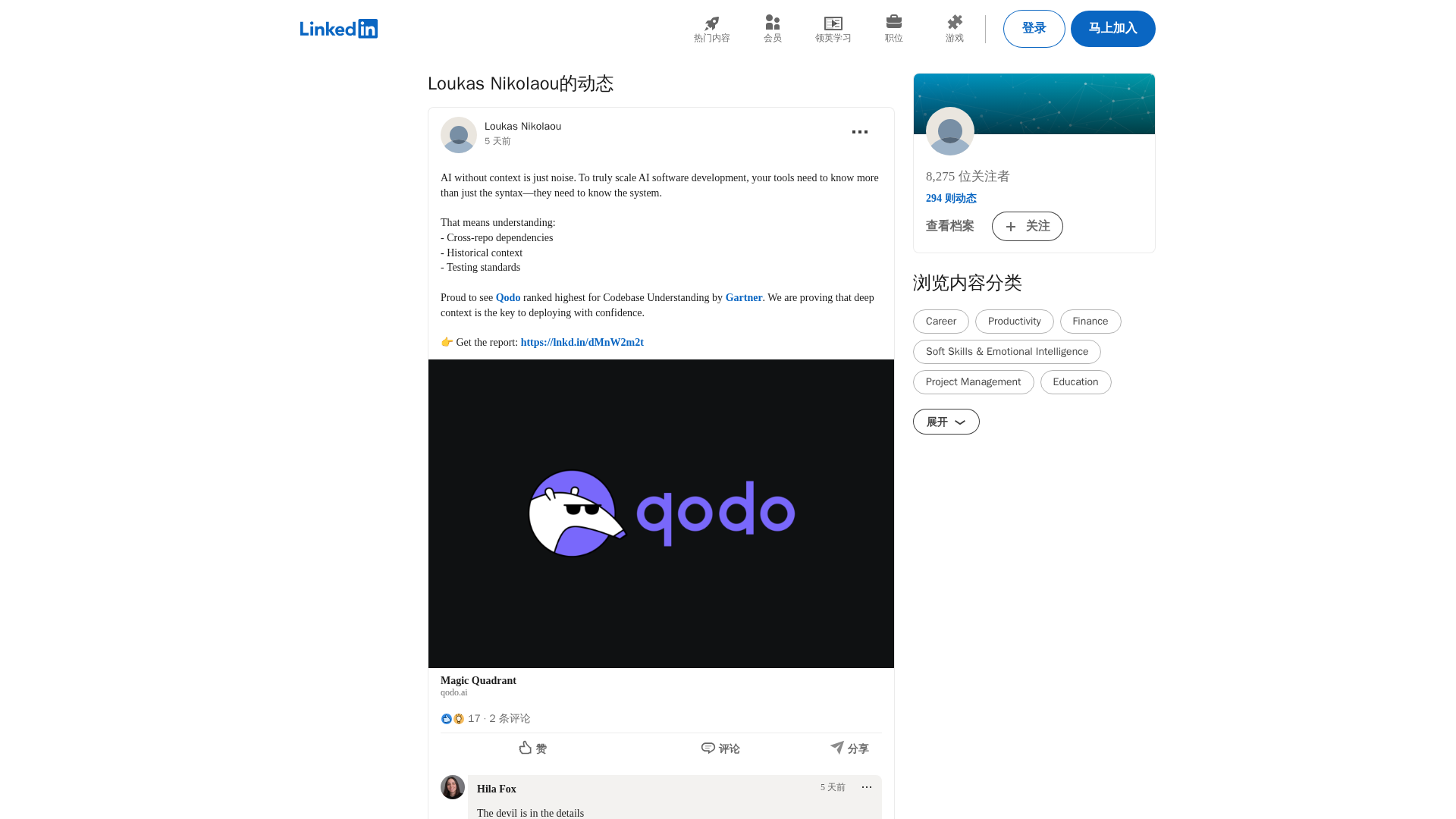
Qodo ranks highest for Codebase Understanding by Gartner, highlighting cross-repo context as essential for scalable AI development.
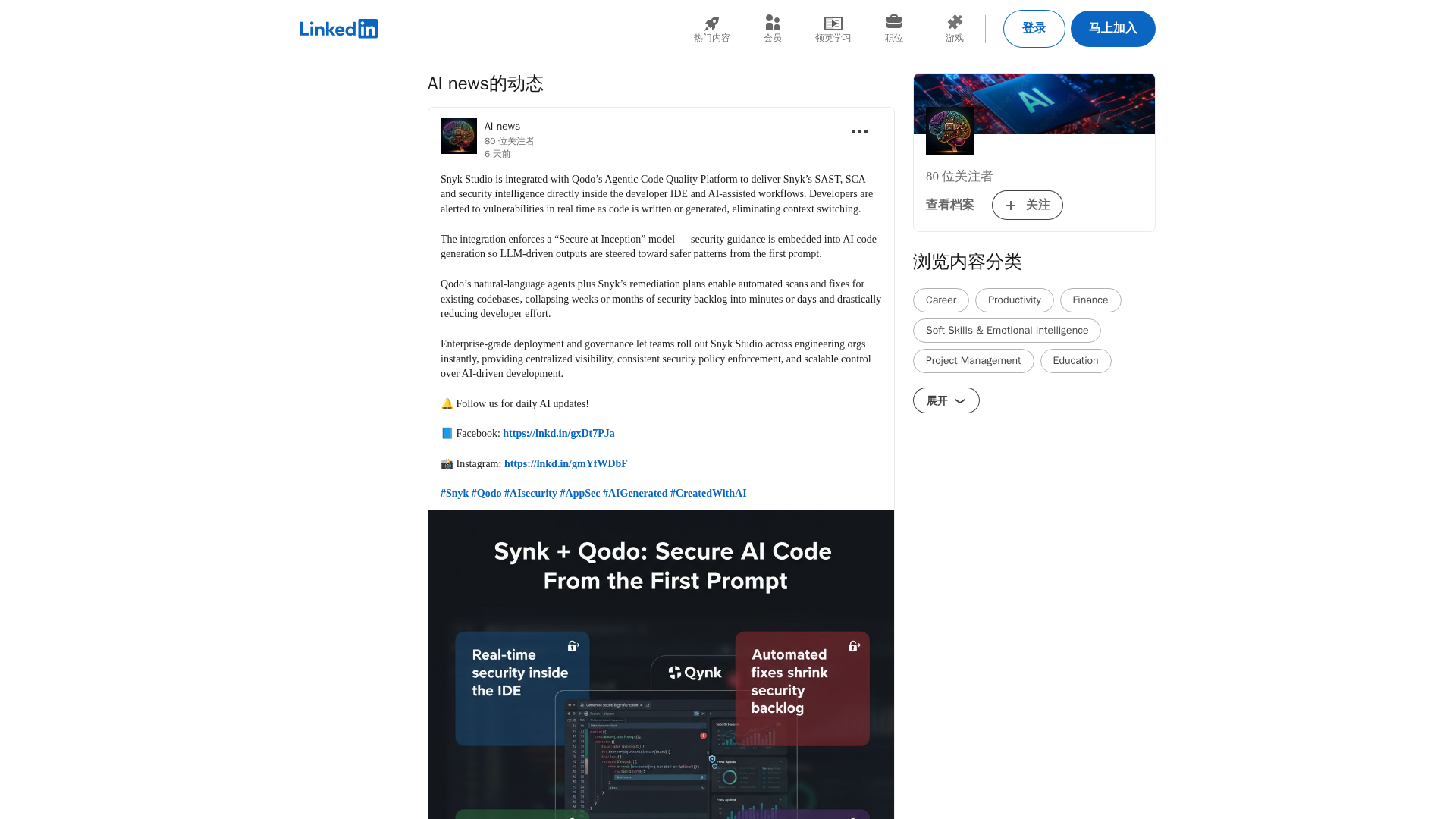
Real-time security alerts and automated fixes for AI-assisted coding inside your IDE.