Topic Overview
This topic covers the growing ecosystem of compact model families and purpose-built accelerators designed to run sophisticated AI outside traditional data centers—on phones, embedded vision devices, and distributed infrastructure. It focuses on two complementary trends: smaller, instruction‑tuned model families (Bonsai-style and code-specialized variants) and hardware accelerators optimized for low-latency, energy‑efficient inference (examples include Groq‑class chips and vendor ASICs from major platform providers such as Meta). Relevance and timeliness (2026): demand for private, low-latency, and offline AI has accelerated adoption of edge‑optimized models and silicon. Edge AI Vision Platforms increasingly require model/hardware co‑design to meet power, thermal, and real‑time constraints, while Decentralized AI Infrastructure benefits from compact models that reduce bandwidth and compute costs. Key tools and categories: Stable Code (Stability AI) and Code Llama (Meta) represent code-focused, edge‑ready LLM families for fast on‑device completion, instruction following, and code infill. EchoComet is an on‑device developer tool for constructing local code context and preserving privacy. The nlpxucan/WizardLM family offers open‑source instruction‑tuned variants useful for customization and edge deployment. Together these models/tools illustrate a spectrum: proprietary and open families that trade off size, latency, and capability, paired with developer workflows that prioritize local context and privacy. Practical considerations include model quantization, sparsity, compiler and runtime support for accelerator instruction sets, and secure update mechanisms. Evaluating options requires matching application constraints (vision vs. language, real‑time vs. batch, privacy vs. connectivity) to the right model family and accelerator stack to achieve predictable, on‑device performance without relying on data‑center inference.
Tool Rankings – Top 4

Edge-ready code language models for fast, private, and instruction‑tuned code completion.
Feed your code context directly to AI
Code-specialized Llama family from Meta optimized for code generation, completion, and code-aware natural-language tasks

Open-source family of instruction-following LLMs (WizardLM/WizardCoder/WizardMath) built with Evol-Instruct, focused on
Latest Articles (20)
EchoComet's contact page provides fast support, license recovery, and device limits for macOS.
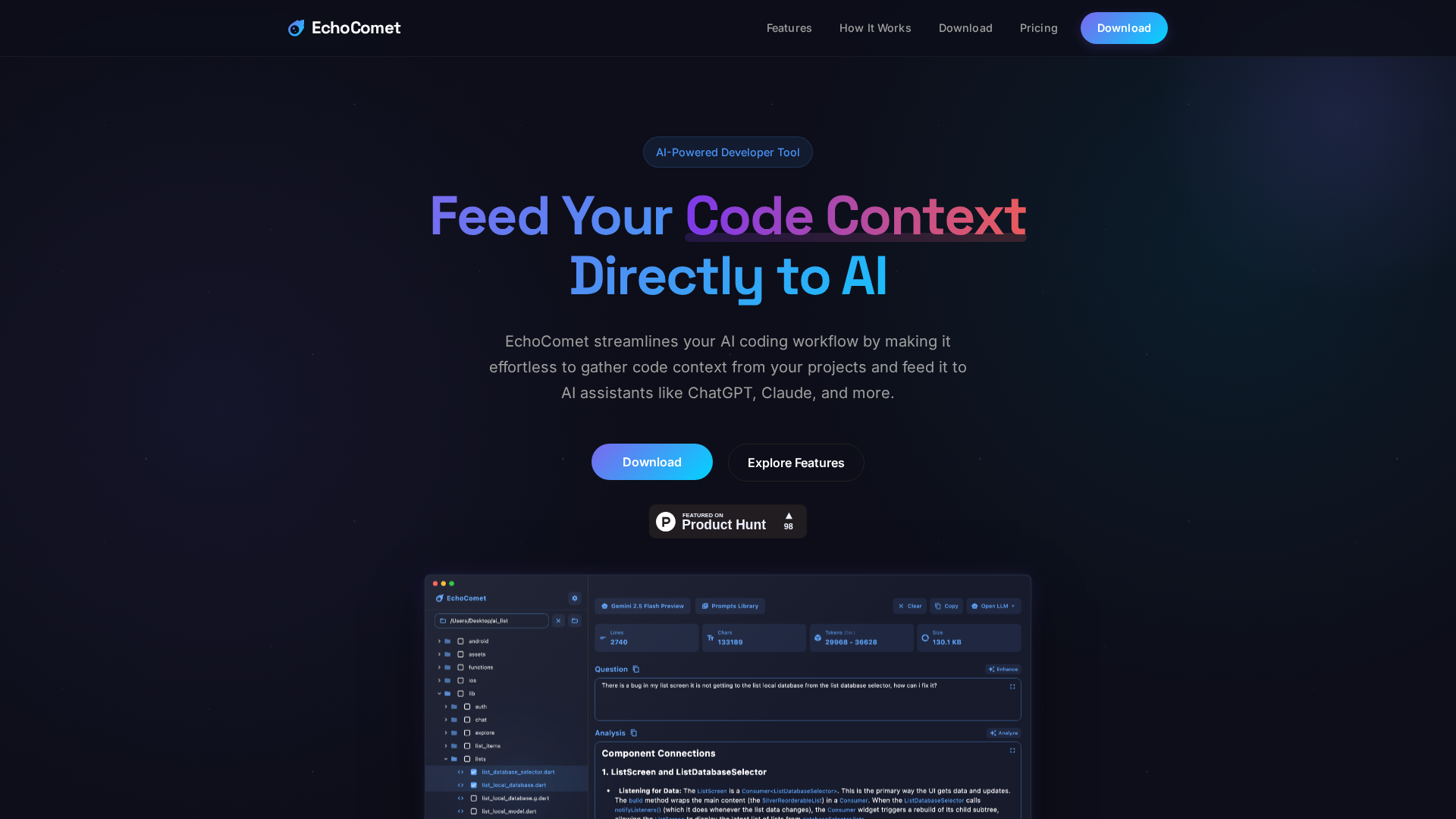
EchoComet lets you gather code context locally and feed it to AI with large-context prompts for smarter, private AI assistance.

Adobe nears a $19 billion deal to acquire Semrush, expanding its marketing software capabilities, according to WSJ reports.
Adobe’s Semrush acquisition signals a major AI-driven shift and potential consolidation in SEO tools.
A practical guide to WizardLM-2 7B: performance, training, and deployment options.