Topic Overview
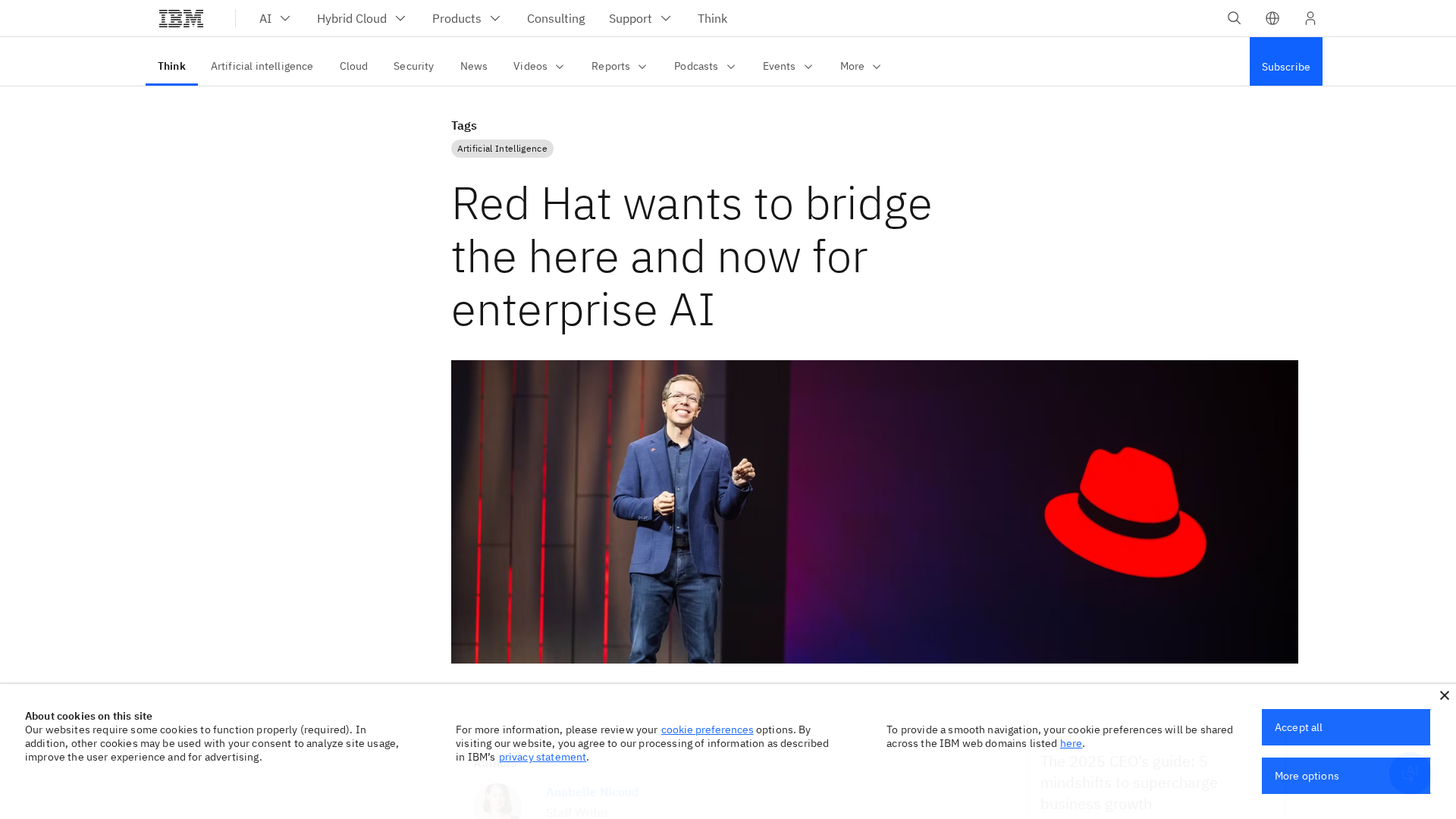
This topic examines how enterprises optimize GenAI inference for cost and performance by choosing between a Kubernetes‑native inference stack such as Red Hat AI Inference Server and hosted cloud provider offerings. The decision space now spans on‑prem and hybrid deployments, serverless and managed cloud inference, and edge vision and automation platforms that prioritize latency, energy use, and data residency. Why it matters in 2026: model sizes and multimodal workloads continue to grow, while purpose‑built accelerators and software stacks have materially reduced per‑inference energy and throughput costs. Providers and vendors address different tradeoffs: cloud providers (with managed APIs and services like Google’s Gemini via Vertex AI) simplify operations and scale elastically, but can lead to higher long‑term unit costs for predictable, high‑throughput workloads. Kubernetes‑native servers such as Red Hat AI Inference Server give enterprises tighter control over hardware utilization, network topology, and model placement—helpful for steady, latency‑sensitive production workloads and regulatory constraints. Key tools and categories: Together AI provides an end‑to‑end acceleration cloud with serverless inference and scalable GPU training; Rebellions.ai focuses on energy‑efficient inference accelerators for hyperscale/edge deployments; IBM watsonx Assistant targets enterprise automation and virtual agents; Anthropic’s Claude and Google Gemini supply multimodal and conversational models via managed APIs; Stable Code offers compact, edge‑ready code models for private inference; Tensorplex Labs experiments with decentralized, open infrastructure. Practical considerations include total cost of ownership (hardware amortization, energy, licensing), utilization patterns (burst vs steady), integration complexity (Kubernetes/OpenShift vs managed APIs), and emerging options like specialized accelerators and hybrid architectures that mix on‑prem inference for predictable load with cloud for peak capacity.
Tool Rankings – Top 6
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
Energy-efficient AI inference accelerators and software for hyperscale data centers.
Enterprise virtual agents and AI assistants built with watsonx LLMs for no-code and developer-driven automation.
Google’s multimodal family of generative AI models and APIs for developers and enterprises.

Edge-ready code language models for fast, private, and instruction‑tuned code completion.
Anthropic's Claude family: conversational and developer AI assistants for research, writing, code, and analysis.
Latest Articles (92)

A vendor‑agnostic guide to the 14 best AI governance platforms in 2025, with criteria, comparisons, and practical buying guidance.
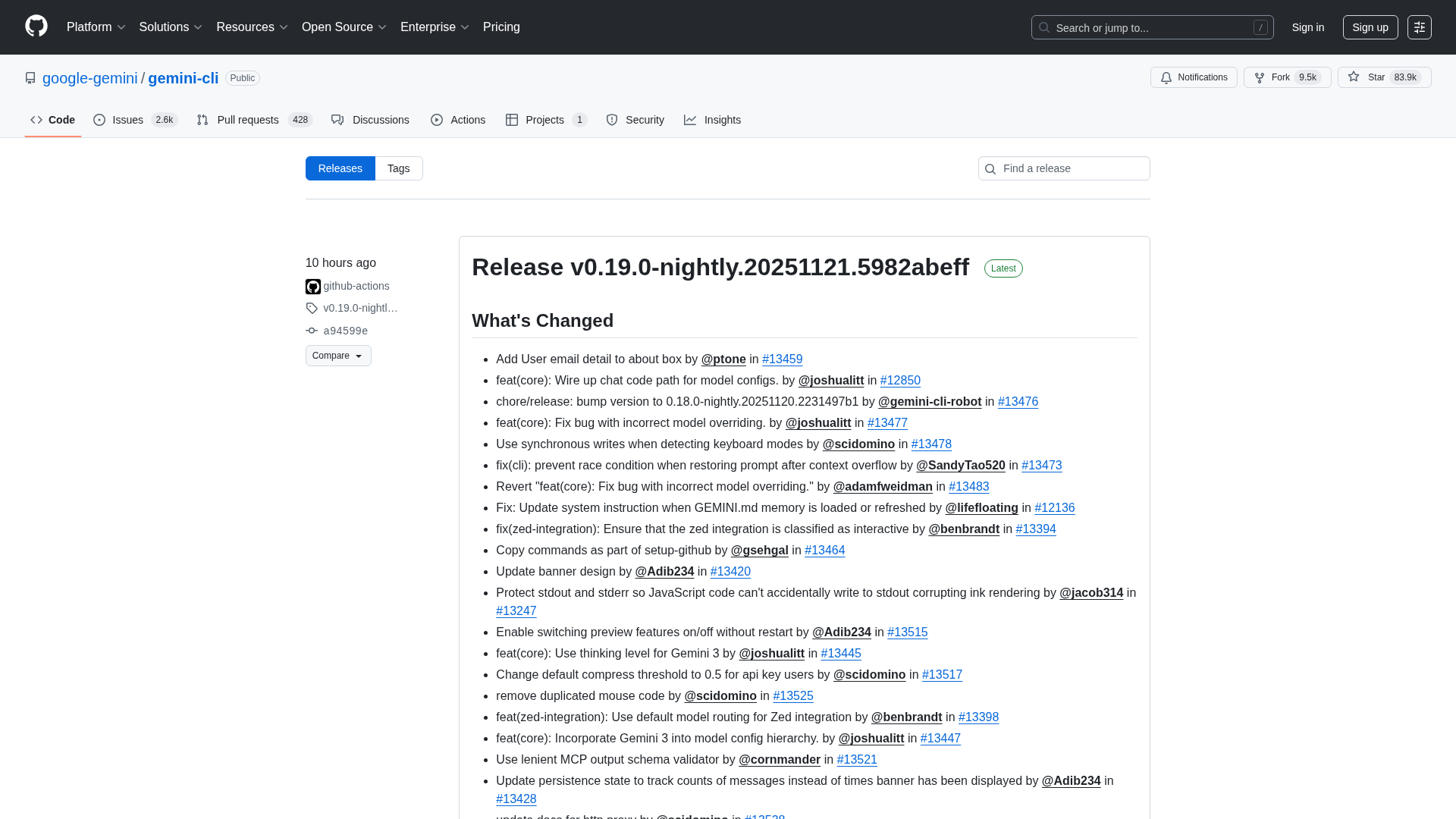
Overview of the Gemini CLI v0.36.0-preview release series, highlighting architectural, CLI, and UI changelogs across multiple pre-release versions.

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.

Adobe nears a $19 billion deal to acquire Semrush, expanding its marketing software capabilities, according to WSJ reports.
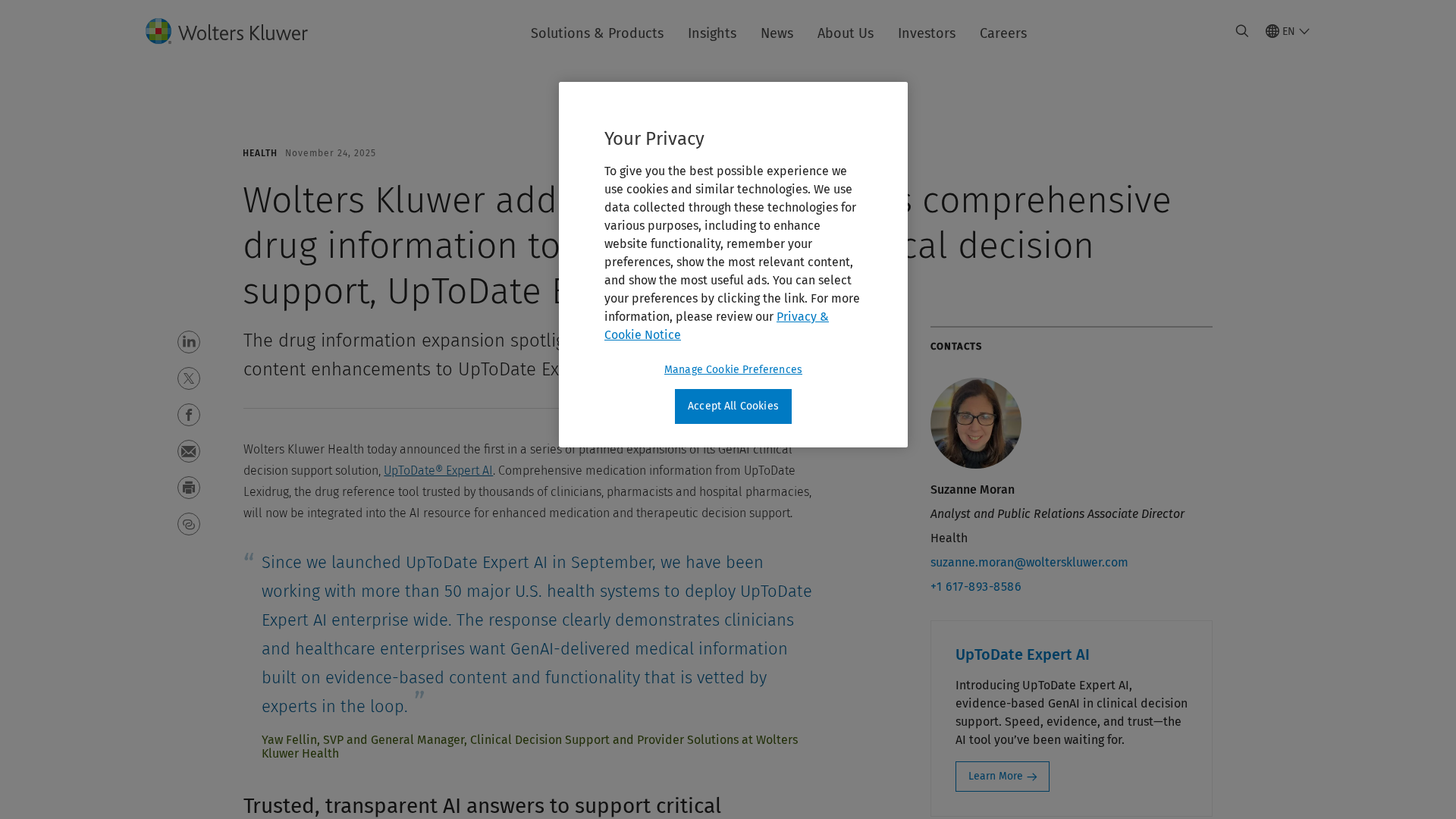
Wolters Kluwer expands UpToDate Expert AI with UpToDate Lexidrug to bolster drug information and medication decision support.