Topic Overview
Enterprise GenAI inference servers and platforms are the runtime layer that turns large language and multimodal models into production services with predictable latency, throughput, cost and governance. By 2026, deployments increasingly combine vendor runtimes (NVIDIA Triton), cloud-optimized servers (Red Hat AI Inference Server for AWS Trainium/Inferentia), and managed low‑latency offerings (Hugging Face Infinity) to meet divergent enterprise SLAs and cost targets. Key trends: specialized inference silicon and software stacks (e.g., Rebellions.ai’s energy‑efficient accelerators) are driving lower operating cost and emissions for hyperscale deployments; model optimizations (quantization, compilation, multi-backend serving) and standardized runtimes (Triton, ONNX/ORT integrations) reduce friction for multi-cloud and hybrid setups; and the rise of multimodal and Retrieval-Augmented Generation (RAG) workloads increases demand for integrated data and vector stores (Activeloop Deep Lake) plus robust interaction-logging and fine-tuning pipelines (OpenPipe). Enterprise toolchains now span hardware, inference runtimes, data platforms and observability: LlamaIndex and MindStudio help build and orchestrate document agents and no/low-code agent workflows; OpenPipe and Deep Lake handle interaction capture and multimodal data; RagaAI provides testing, observability and guardrails for agentic systems; developer productivity tools (e.g., GitHub Copilot) accelerate integration and deployment. Together these components address real-world requirements—latency, throughput, energy efficiency, model governance, and continuous evaluation—while enabling safe scaling of GenAI services. This topic is timely because operational costs, regulatory scrutiny, and heterogeneity of accelerator hardware are reshaping inference architecture choices; enterprises must evaluate both server runtimes and surrounding data and observability platforms to deploy GenAI reliably at scale.
Tool Rankings – Top 6
Energy-efficient AI inference accelerators and software for hyperscale data centers.

Managed platform to collect LLM interaction data, fine-tune models, evaluate them, and host optimized inference.
Deep Lake: a multimodal database for AI that stores, versions, streams, and indexes unstructured ML data with vector/RAG

The All‑in‑One Platform to Evaluate, Debug, and Scale AI Agents

No-code/low-code visual platform to design, test, deploy, and operate AI agents rapidly, with enterprise controls and a

An AI pair programmer that gives code completions, chat help, and autonomous agent workflows across editors, theterminal
Latest Articles (57)
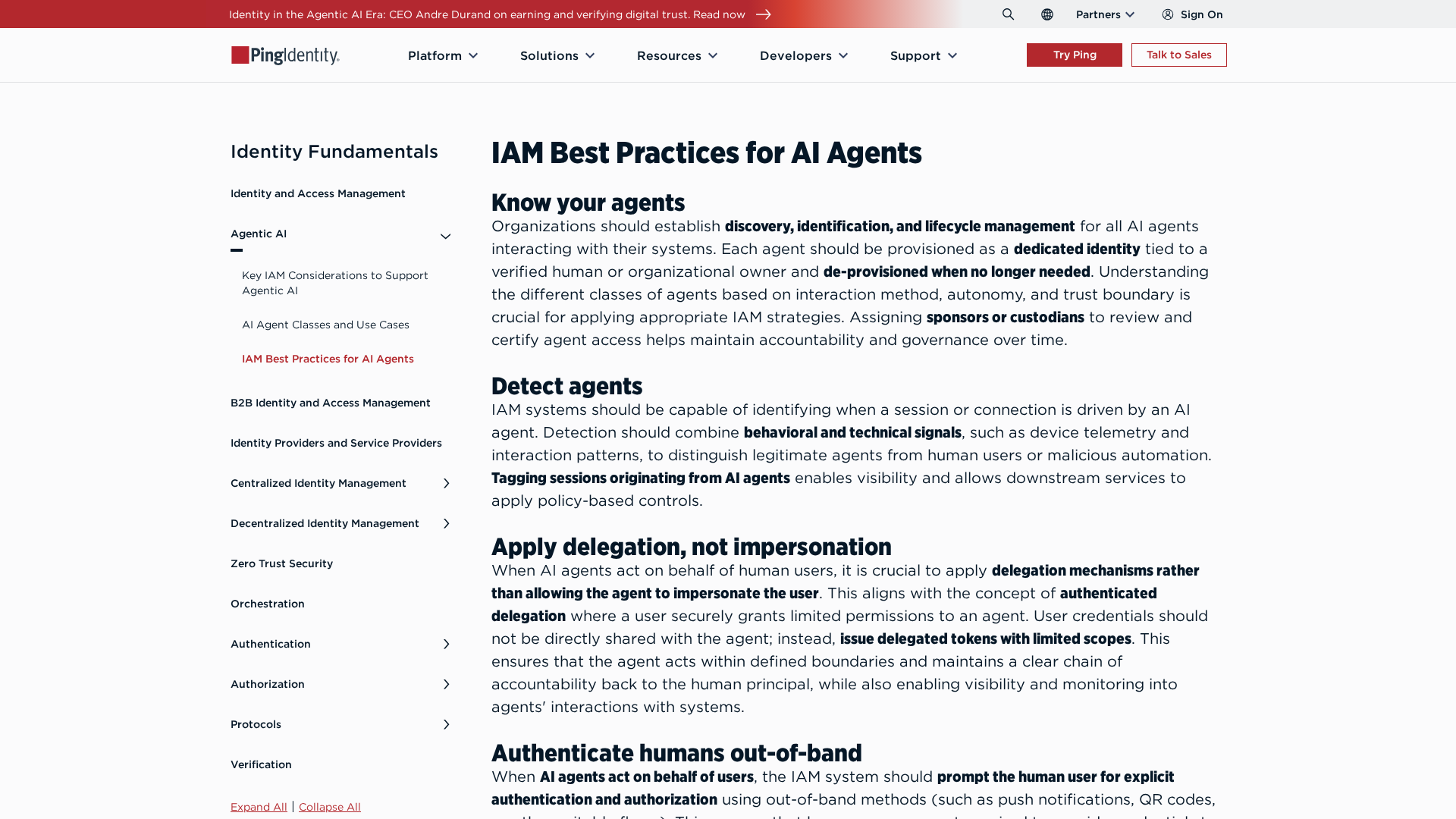
Best-practices for securing AI agents with identity management, delegated access, least privilege, and human oversight.
A foundational Core overhauL that speeds up development, simplifies authentication with JWT, and accelerates governance for Akash's decentralized cloud.
Meta plans a 500MW AI data center in Visakhapatnam with Sify, linked to the Waterworth subsea cable.
Meta to lease 500 MW Visakhapatnam data centre capacity from Sify and land Waterworth submarine cable.
Understand AI model marketplaces and how they speed development by leveraging ready-to-use models from leading platforms.