Topic Overview
This topic covers providers and components that enable low‑latency satellite inference by combining on‑orbit/near‑edge compute, energy‑efficient accelerators, compact models, and distributed orchestration. Demand for on‑satellite and ground-proximate inference has grown as satellite constellations and real‑time Earth‑observation, comms routing, and autonomous payload tasks push processing closer to data sources to reduce downlink, improve responsiveness, and meet privacy constraints. Key categories include Edge AI Vision Platforms (vision pipelines, model serving and data‑preprocessing for satellite imagery) and Decentralized AI Infrastructure (distributed orchestration, visibility and governance across space and terrestrial nodes). Practical stacks pair hardware and software: Rebellions.ai provides purpose‑built inference accelerators and a GPU‑class stack for energy‑constrained, high‑throughput deployments; Xilos offers enterprise orchestration and visibility for agentic workflows across connected services; compact, edge‑tuned models such as Stability’s Stable Code family enable instruction‑tuned, low‑footprint code and inference tasks on constrained nodes. Developer and deployment tooling—EchoComet’s local, privacy‑focused context assembly and coding assistants like Tabnine (enterprise, private/self‑hosted) and Tabby (open‑source, local‑first model serving)—help teams build, test and govern models destined for space or edge hosts. Selecting the best provider requires matching mission constraints (power, thermal, radiation tolerance, latency, bandwidth, and governance) to a heterogeneous stack: accelerator silicon and software, compact/quantized models, secure local toolchains, and orchestration that supports decentralization and observability. This topic synthesizes current provider capabilities and practitioner tradeoffs for low‑latency satellite inference.
Tool Rankings – Top 6

Edge-ready code language models for fast, private, and instruction‑tuned code completion.
Intelligent Agentic AI Infrastructure
Energy-efficient AI inference accelerators and software for hyperscale data centers.
Feed your code context directly to AI

Enterprise-focused AI coding assistant emphasizing private/self-hosted deployments, governance, and context-aware code.
.avif)
Open-source, self-hosted AI coding assistant with IDE extensions, model serving, and local-first/cloud deployment.
Latest Articles (35)
EchoComet's contact page provides fast support, license recovery, and device limits for macOS.
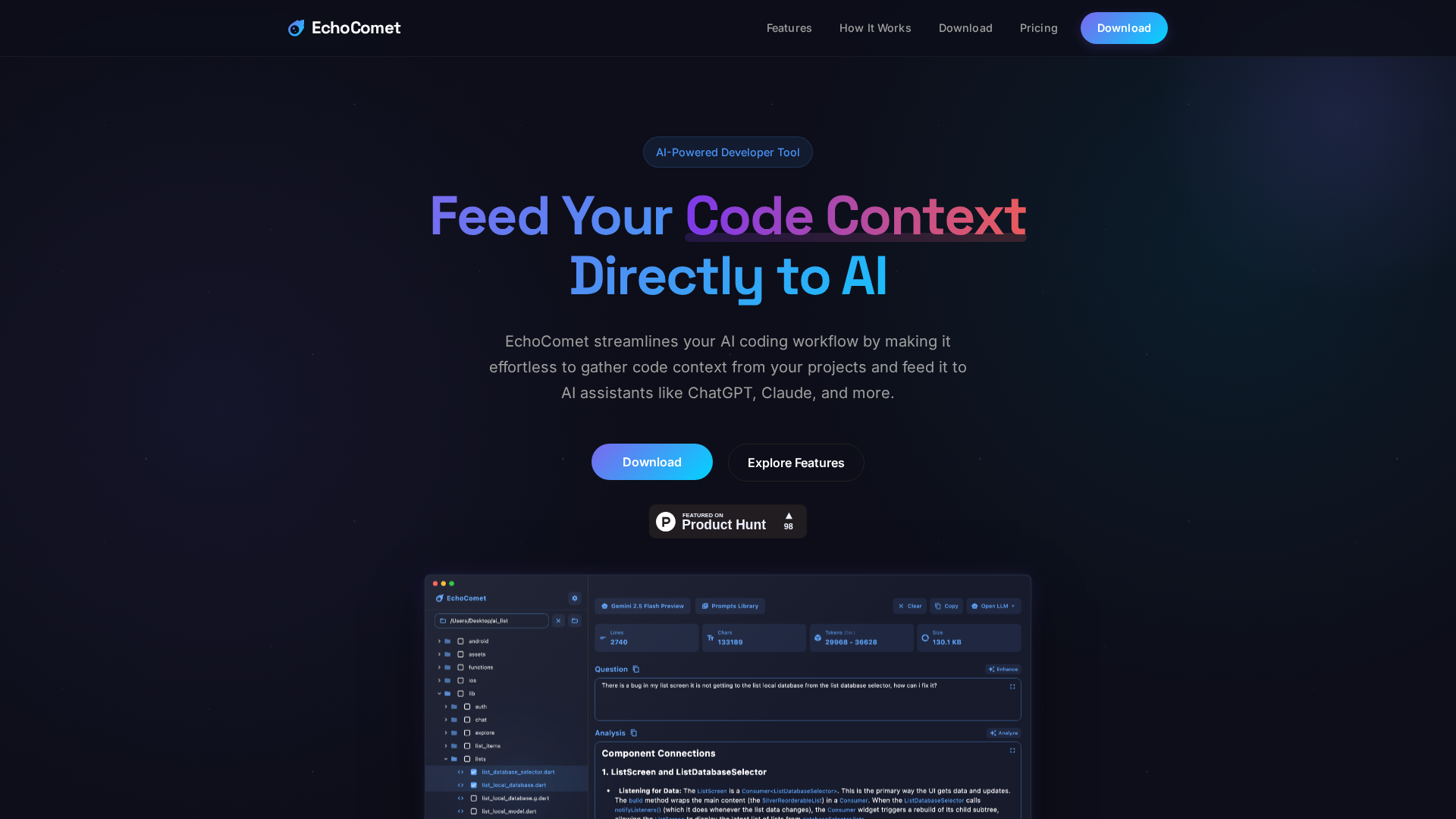
EchoComet lets you gather code context locally and feed it to AI with large-context prompts for smarter, private AI assistance.
OpenAI’s bypass moment underscores the need for governance that survives inevitable user bypass and hardens system controls.
A call to enable safe AI use at work via sanctioned access, real-time data protections, and frictionless governance.
Explores the human role behind AI automation and how Bell Cyber tackles AI hallucinations in security operations.