
Topic Overview
This topic covers the techniques, runtimes, and toolchains used to run large language models (LLMs) in memory‑constrained environments—on laptops, edge devices, and privacy‑sensitive local servers. Core approaches include model quantization (reducing numeric precision to 8/4/2 bits or using post‑training/quantization‑aware methods), parameter offloading (moving weights or activations between GPU, CPU and storage), and specialized low‑RAM runtimes and kernels that minimize peak memory and latency. These methods are increasingly relevant as demand grows for local‑first, low‑latency, and cost‑sensitive AI: smaller 3B‑class models (for example, edge‑ready code models) enable on‑device code completion and private assistants without expensive cloud GPU usage. Key tools and categories: LangChain (Agent Frameworks) provides standard model interfaces and orchestration for hybrid pipelines that can combine local and remote inference; Stable Code (Decentralized AI Infrastructure/Research Tools) represents families of smaller, instruction‑tuned code models optimized for fast, private completion; EchoComet, remio, and Znote are examples of local‑first developer and knowledge applications that benefit from privacy‑preserving, memory‑efficient inference by keeping context and model execution on device. Current trends include wider adoption of 4–8‑bit quantization and GPTQ‑style compression, runtime support for NVMe/CPU offloading to trade latency for memory capacity, and integration of these techniques into agent frameworks and data platforms so apps can route workloads between local runtimes and cloud services. Practitioners should weigh trade‑offs among model quality, latency, and operational complexity when choosing quantization and offloading strategies for production workloads.
Tool Rankings – Top 5

Edge-ready code language models for fast, private, and instruction‑tuned code completion.
Feed your code context directly to AI

An open-source framework and platform to build, observe, and deploy reliable AI agents.
Local-first AI note taker & personal knowledge hub
Continue your ChatGPT chats inside smart notes
Latest Articles (28)
EchoComet's contact page provides fast support, license recovery, and device limits for macOS.
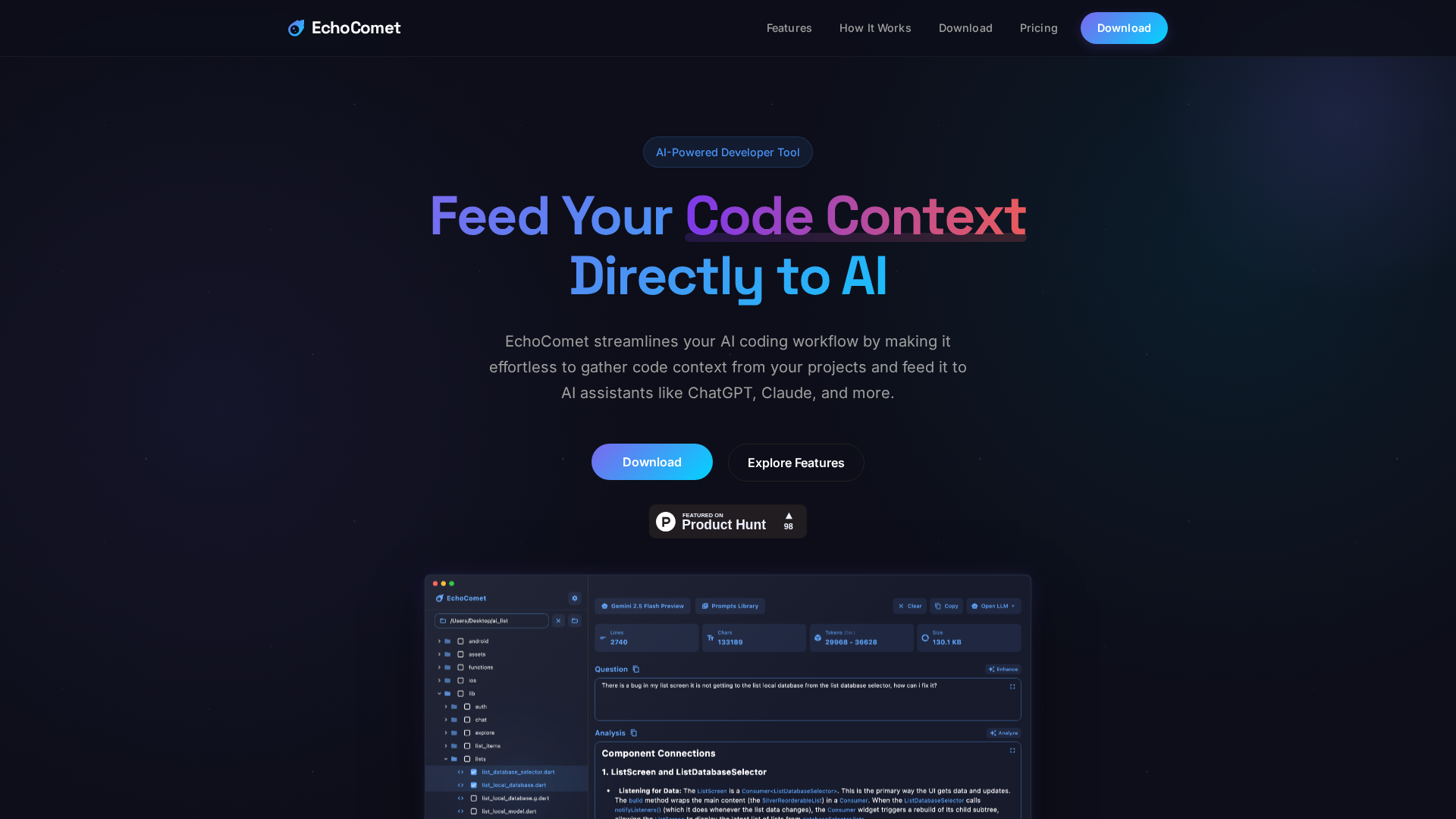
EchoComet lets you gather code context locally and feed it to AI with large-context prompts for smarter, private AI assistance.
Analyzes why the Nvidia–OpenAI $100B deal is not binding yet and what that means for investors.
A provocative analysis of Moltbook AI’s machine-only subculture, governance, and security implications.
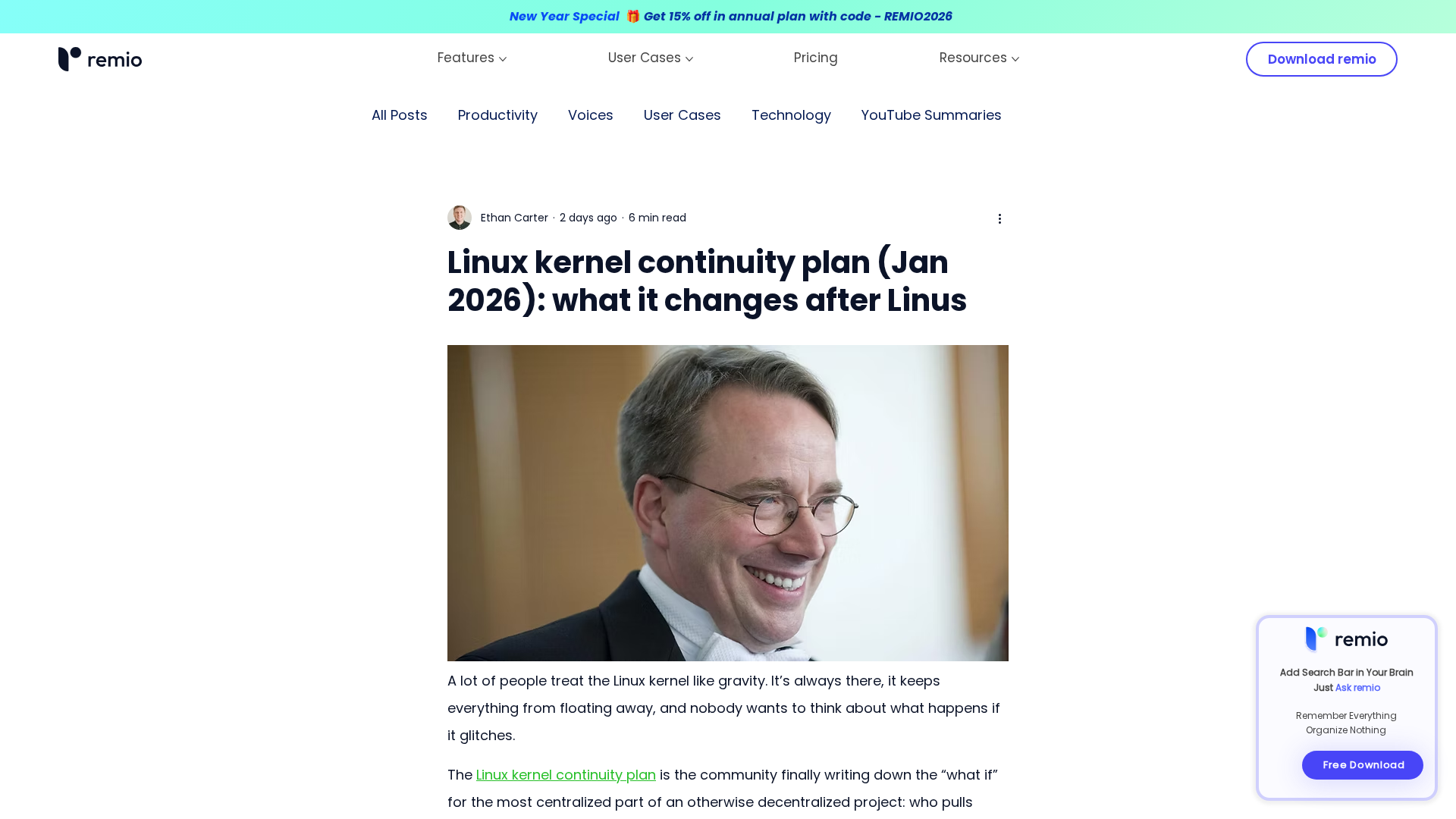
Explains the Jan 2026 Linux kernel continuity plan and how it reshapes governance if the top maintainer can’t lead.