Topic Overview
This topic covers the stack and ecosystem for deploying large language models and multimodal inference at scale: specialized inference silicon (NVIDIA, IREN, Groq‑3 and purpose‑built accelerators), energy‑aware hardware and server designs (e.g., Rebellions.ai’s chiplets/SoCs and GPU‑class software stacks), and the cloud and on‑prem orchestration layers that operate them. It intersects two trends — Decentralized AI Infrastructure (distributed racks, edge and self‑hosted clusters) and AI Data Platforms (model lifecycle, observability, governance and data pipelines) — that determine cost, latency, and compliance for production workloads. Why it matters in 2026: model sizes and multimodal workloads keep pushing compute and power requirements, raising operational cost and carbon concerns. At the same time, demand for private or geodistributed deployments and tighter governance is increasing adoption of non‑hyperscaler and self‑hosted options. This makes accelerator efficiency, software compatibility, and integration with cloud partners and MLOps tooling central evaluation criteria. Key tools and roles: Rebellions.ai provides energy‑efficient inference accelerators and a GPU‑class software stack for hyperscale and on‑prem servers; NVIDIA, IREN and Groq‑3 represent different design tradeoffs in throughput, latency and software ecosystem; StationOps targets AWS DevOps workflows for deployment automation; Windsurf (formerly Codeium) and agentic IDEs help developer workflows and multi‑model testing; Tabby and Tabnine enable self‑hosted or enterprise‑governed coding assistants; MindStudio offers low‑code visual pipelines for agent deployment and operations. Evaluations should weigh throughput, latency, power efficiency, model compatibility, software maturity, and governance—then map those to workload patterns (real‑time low‑latency vs. batch high‑throughput) and deployment constraints (cost, residency, and observability).
Tool Rankings – Top 6
Energy-efficient AI inference accelerators and software for hyperscale data centers.
The AI DevOps Engineer for AWS
AI-native IDE and agentic coding platform (Windsurf Editor) with Cascade agents, live previews, and multi-model support.
.avif)
Open-source, self-hosted AI coding assistant with IDE extensions, model serving, and local-first/cloud deployment.

Enterprise-focused AI coding assistant emphasizing private/self-hosted deployments, governance, and context-aware code.

No-code/low-code visual platform to design, test, deploy, and operate AI agents rapidly, with enterprise controls and a
Latest Articles (31)
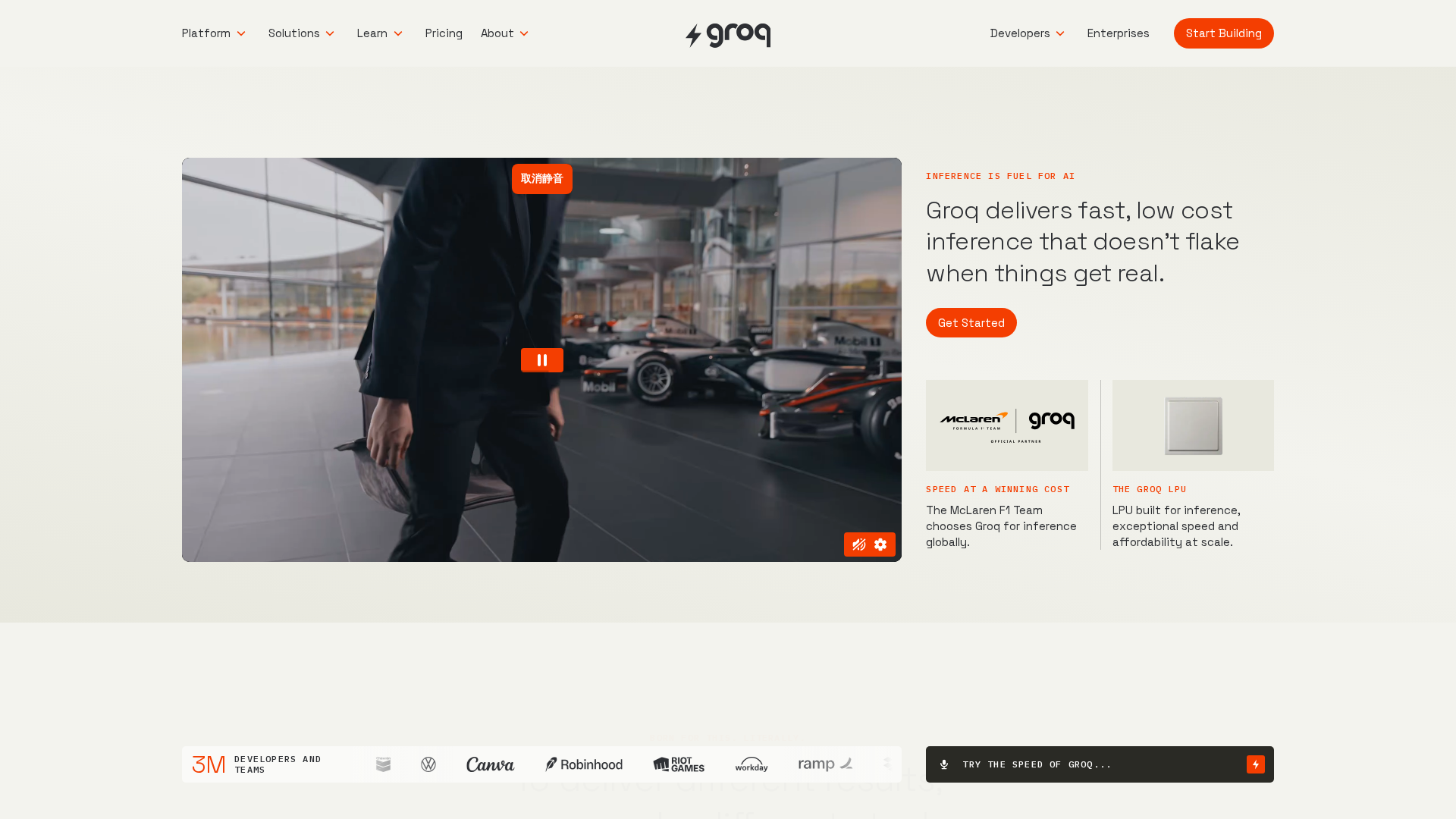
A concise look at how an internal developer platform on AWS accelerates delivery with governance and self-service.
An AWS-centric internal developer platform comparison between StationOps and Netlify.
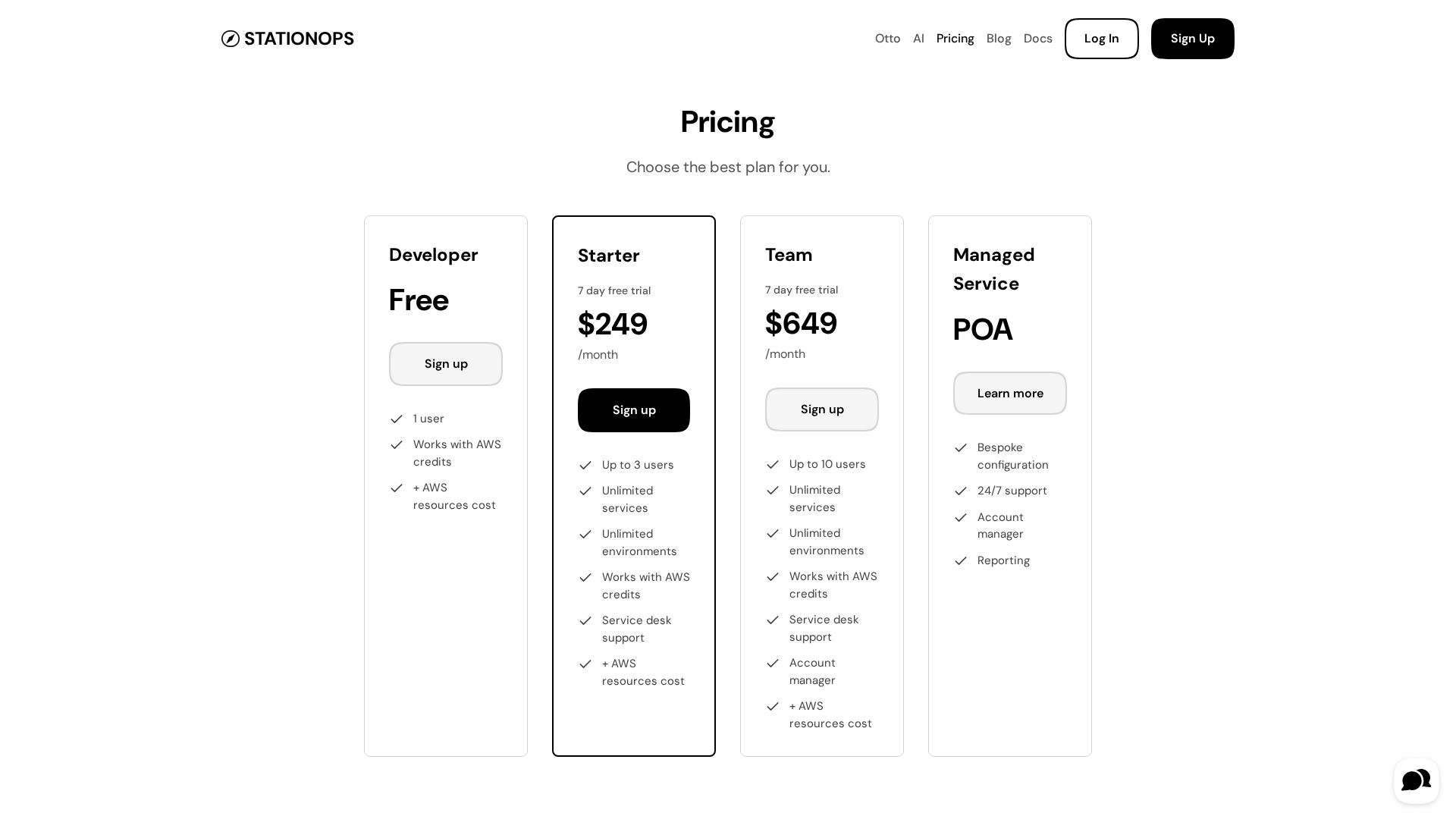
Pricing details for StationOps' AWS Internal Developer Platform, including tiers and features.
A guided look at StationOps’ internal Dev Platform for AWS—enabling governed, self‑serve environments at scale.
A managed internal developer platform for AWS that simplifies provisioning, deployment, and governance to accelerate software delivery.