Topic Overview
This topic covers architectures and ecosystems that combine confidential compute, blockchain settlement, and decentralized inference networks to run AI models in a privacy-preserving, auditable way. It spans on‑device and edge inference, off‑chain execution with on‑chain verification/settlement, and emerging marketplaces (e.g., Acurast-style execution layers and networks built on Layer‑2 chains such as Base) that coordinate and pay providers for inference. Core technical approaches include TEEs (confidential enclaves), MPC/secure aggregation, zero‑knowledge proofs for verifiable execution, and hybrid edge/cloud orchestration to balance latency, cost, and data privacy. Relevance and timing: demand for private, auditable inference has increased as organizations adopt LLMs in regulated settings (code generation, legal/health workflows) and as on‑chain primitives (L2s and execution marketplaces) mature. Developers and enterprises are looking for stacks that let them keep sensitive context local while still monetizing or verifying inference outcomes via tokenized settlement and decentralized trust layers. Key tools and roles: model providers and edge‑ready families such as Stability’s Stable Code target fast, private code completion; self‑hosted assistants like Tabby and privacy‑first tools such as EchoComet enable local context handling and reduced attack surface; enterprise offerings like Tabnine and Qodo emphasize governance, testing, and multi‑repo compliance for private deployments. In‑IDE assistants (JetBrains AI Assistant) and AI‑native IDEs/agent platforms (Windsurf) integrate inference into developer workflows, while LangChain provides orchestration and observability for agentic pipelines that may span local models, decentralized compute nodes, and on‑chain coordinators. Practical trade‑offs remain: latency vs. confidentiality, attestation and cost of TEEs, incentive and reputational design for decentralized provers, and standards for verifiable outputs. For practitioners, the current landscape favors hybrid deployments—local or enclave‑based inference for sensitive context combined with blockchain‑backed marketplaces and orchestration frameworks to enable auditable, payable, and composable decentralized AI infrastructure.
Tool Rankings – Top 6

Edge-ready code language models for fast, private, and instruction‑tuned code completion.
.avif)
Open-source, self-hosted AI coding assistant with IDE extensions, model serving, and local-first/cloud deployment.
In‑IDE AI copilot for context-aware code generation, explanations, and refactorings.
AI-native IDE and agentic coding platform (Windsurf Editor) with Cascade agents, live previews, and multi-model support.

Enterprise-focused AI coding assistant emphasizing private/self-hosted deployments, governance, and context-aware code.
Feed your code context directly to AI
Latest Articles (46)
EchoComet's contact page provides fast support, license recovery, and device limits for macOS.
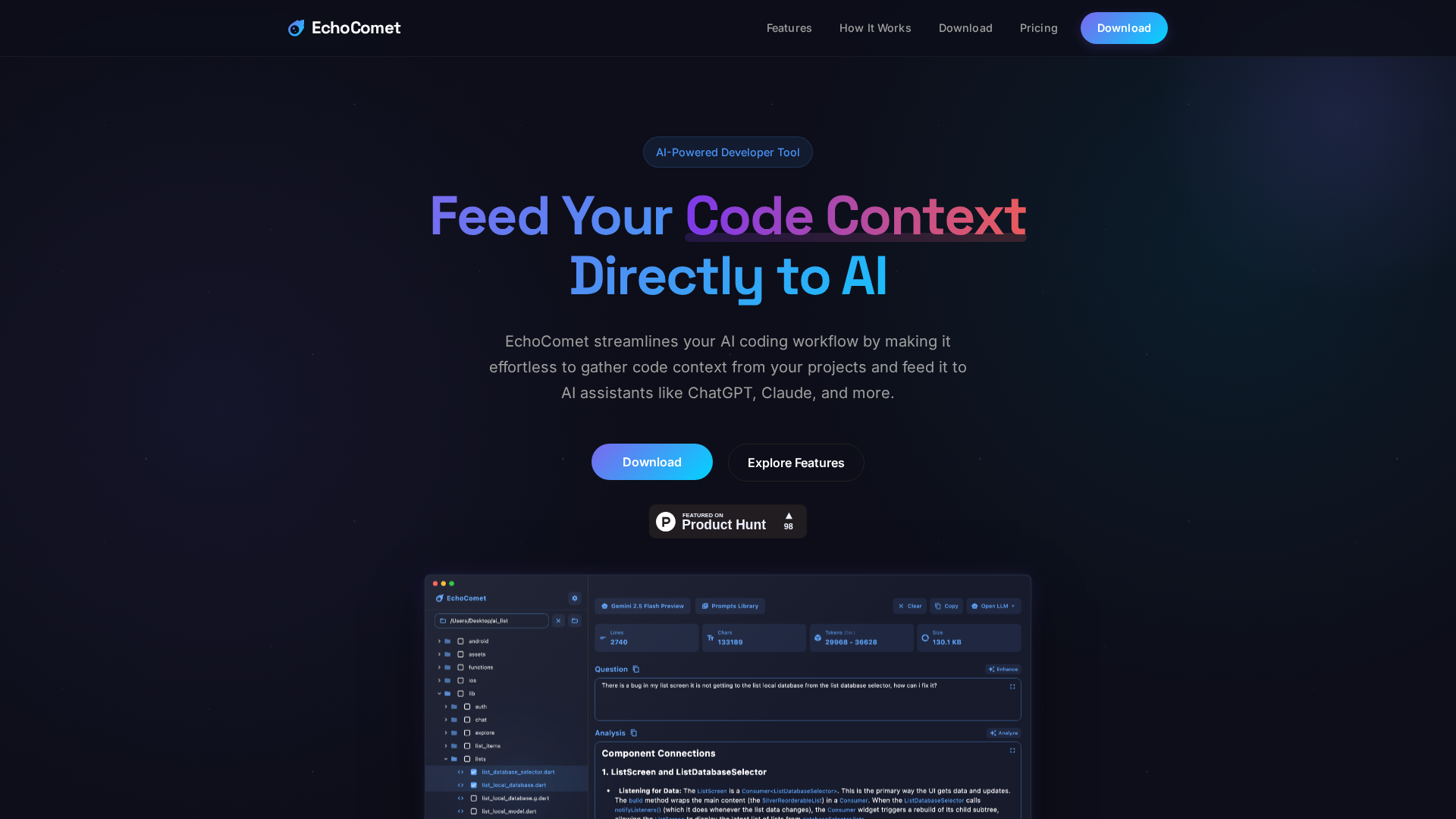
EchoComet lets you gather code context locally and feed it to AI with large-context prompts for smarter, private AI assistance.
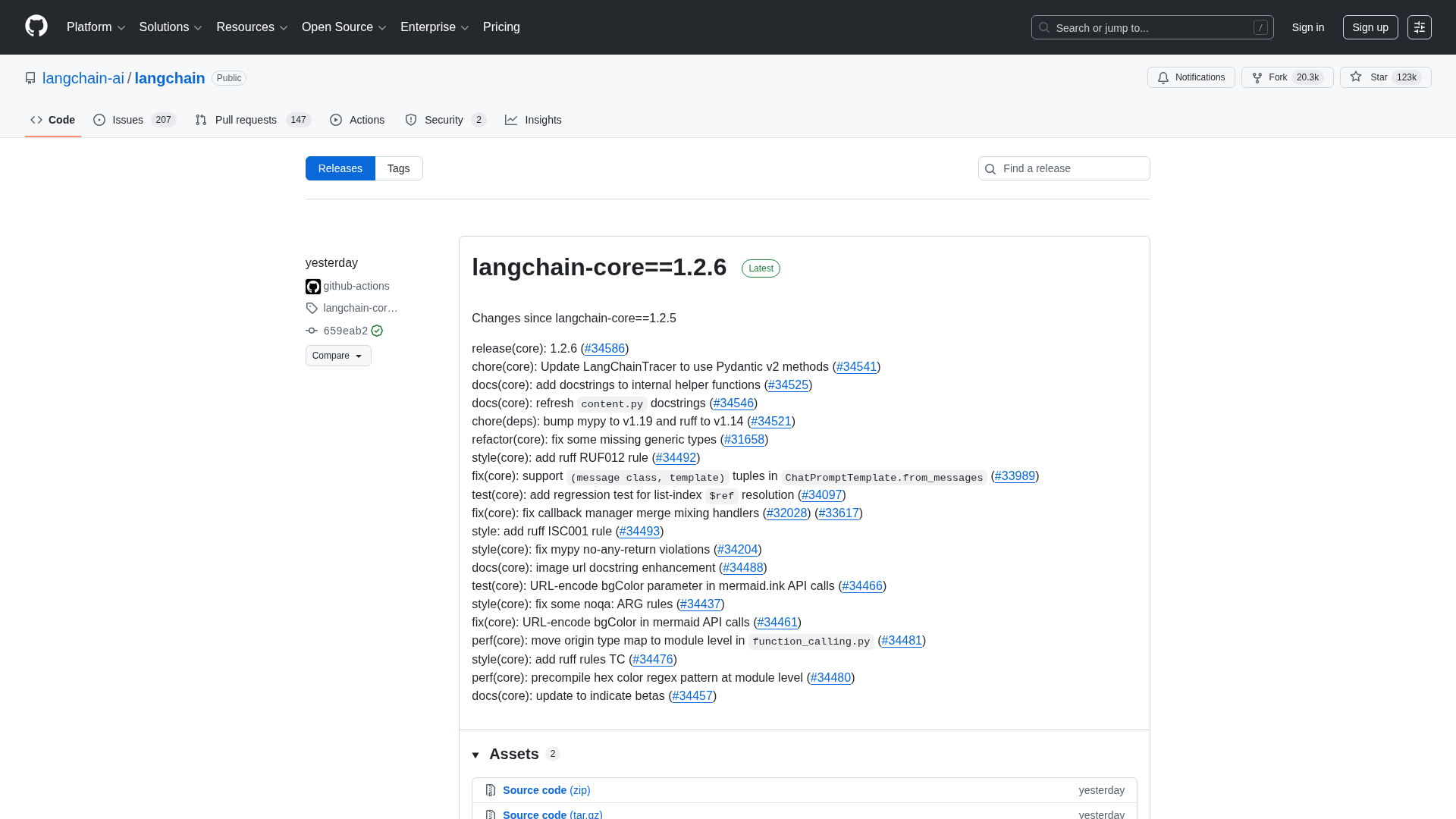
A comprehensive LangChain releases roundup detailing Core 1.2.6 and interconnected updates across XAI, OpenAI, Classic, and tests.
A reproducible bug where LangGraph with Gemini ignores tool results when a PDF is provided, even though the tool call succeeds.
A CLI tool to pull LangSmith traces and threads directly into your terminal for fast debugging and automation.