
Topic Overview
This topic examines how different memory and storage technologies—DRAM, NAND flash, high-bandwidth memory (HBM) and emerging non‑volatile memories (MRAM, ReRAM, PCM/persistent memory)—affect AI workloads across hyperscale inference, training, edge deployment and decentralized AI platforms. It synthesizes current industry trends and the needs implied by modern tools: purpose‑built inference accelerators (e.g., Rebellions.ai’s chiplet/SoC stacks) demand HBM-like bandwidth and careful on‑chip SRAM budgeting; mid‑sized code models (Stable Code’s 3B class) target low‑latency, edge‑friendly memory footprints; large open models (StarCoder 15.5B) and server workloads highlight capacity and bandwidth tradeoffs; and privacy‑first local tools (EchoComet) emphasize efficient use of device NAND and persistent storage. Why it matters now: model sizes and inference throughput requirements continue to climb while energy, latency and cost constraints push architects to mix memory tiers and new interconnects. DRAM remains the baseline for low‑latency working sets; HBM provides necessary bandwidth for accelerators but is capacity‑limited and costly; NAND and storage‑class memory deliver affordable persistence for embeddings, checkpoints and vector stores at the cost of latency and endurance. Emerging memories promise lower power and byte‑addressable persistence that can blur the line between memory and storage for edge and decentralized nodes. Meanwhile, CXL and disaggregated memory architectures are maturing as ways to pool capacity across servers without duplicating DRAM. Practical takeaway: choose memory by workload—HBM for bandwidth‑bound accelerators, DRAM for general compute and latency‑sensitive contexts, NAND/SCM for high‑capacity persistent layers—and factor in software (quantization, memory compression, tiering, CXL) and tool targets (hyperscale inference, local privacy tools, or decentralized platforms) when designing systems.
Tool Rankings – Top 4
Energy-efficient AI inference accelerators and software for hyperscale data centers.

Edge-ready code language models for fast, private, and instruction‑tuned code completion.
StarCoder is a 15.5B multilingual code-generation model trained on The Stack with Fill-in-the-Middle and multi-query ува
Feed your code context directly to AI
Latest Articles (21)
EchoComet's contact page provides fast support, license recovery, and device limits for macOS.
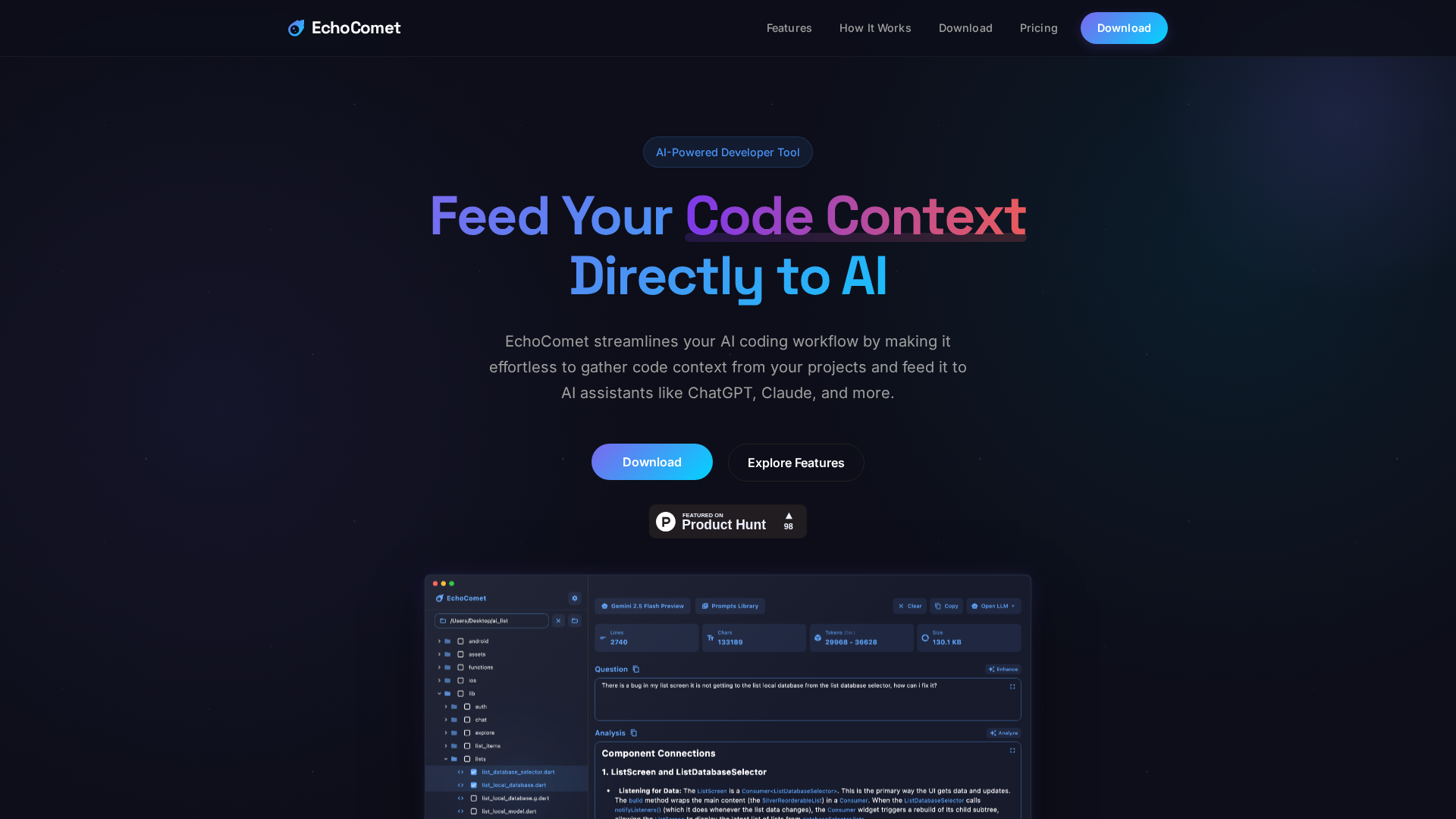
EchoComet lets you gather code context locally and feed it to AI with large-context prompts for smarter, private AI assistance.
ProteanTecs expands in Japan with a new office and Noritaka Kojima as GM Country Manager.
Rebellions names a new CBO and EVP to drive global expansion, while NST commends Qatar’s sustainability leadership.
Rebellions appoints Marshall Choy as CBO to drive global expansion and establish a U.S. market hub.