Topic Overview
AI inference platforms and managed inference services provide the infrastructure and software to run trained models at scale—balancing latency, cost, reliability, and governance for production applications. This topic covers cloud and on‑prem inference, serverless APIs, specialized inference hardware, model marketplaces, and emerging decentralized deployment models. As of early 2026, demand for predictable, energy‑efficient inference has driven diversification: managed hosts and marketplaces (Replicate, Baseten) offer hosted model serving and simple APIs for rapid integration; enterprise and open‑source servers (Red Hat AI Inference Server, NVIDIA’s inference stacks including Triton‑style runtimes) provide production controls, hardware acceleration, and compliance features for on‑prem or hybrid deployments. Hardware vendors and accelerator startups (Rebellions.ai, Together AI’s end‑to‑end acceleration cloud) optimize throughput and power efficiency with purpose‑built SoCs and scalable GPU fleets. Developer frameworks (LangChain) continue to standardize model interfaces and orchestration patterns, while enterprise assistants and platform models (IBM watsonx Assistant, Google Gemini) increase the variety and scale of inference workloads. Key tradeoffs are operational complexity versus ease of use: managed services reduce DevOps burden but can limit visibility and cost control; on‑prem and accelerator solutions require more integration but improve latency, data locality, and energy efficiency. Marketplaces and decentralized projects (Tensorplex Labs) introduce new distribution and monetization paths—combining governance primitives, model discovery, and cross‑node execution. Observability, quantized/multi‑precision serving, model governance, and hybrid deployment patterns are central operational considerations. For teams choosing a path, the right mix depends on latency, compliance, energy targets, and the need for extensible orchestration and model governance.
Tool Rankings – Top 6
A full-stack AI acceleration cloud for fast inference, fine-tuning, and scalable GPU training.
Energy-efficient AI inference accelerators and software for hyperscale data centers.

An open-source framework and platform to build, observe, and deploy reliable AI agents.
Open-source, decentralized AI infrastructure combining model development with blockchain/DeFi primitives (staking, cross
Enterprise virtual agents and AI assistants built with watsonx LLMs for no-code and developer-driven automation.
Google’s multimodal family of generative AI models and APIs for developers and enterprises.
Latest Articles (75)

A vendor‑agnostic guide to the 14 best AI governance platforms in 2025, with criteria, comparisons, and practical buying guidance.
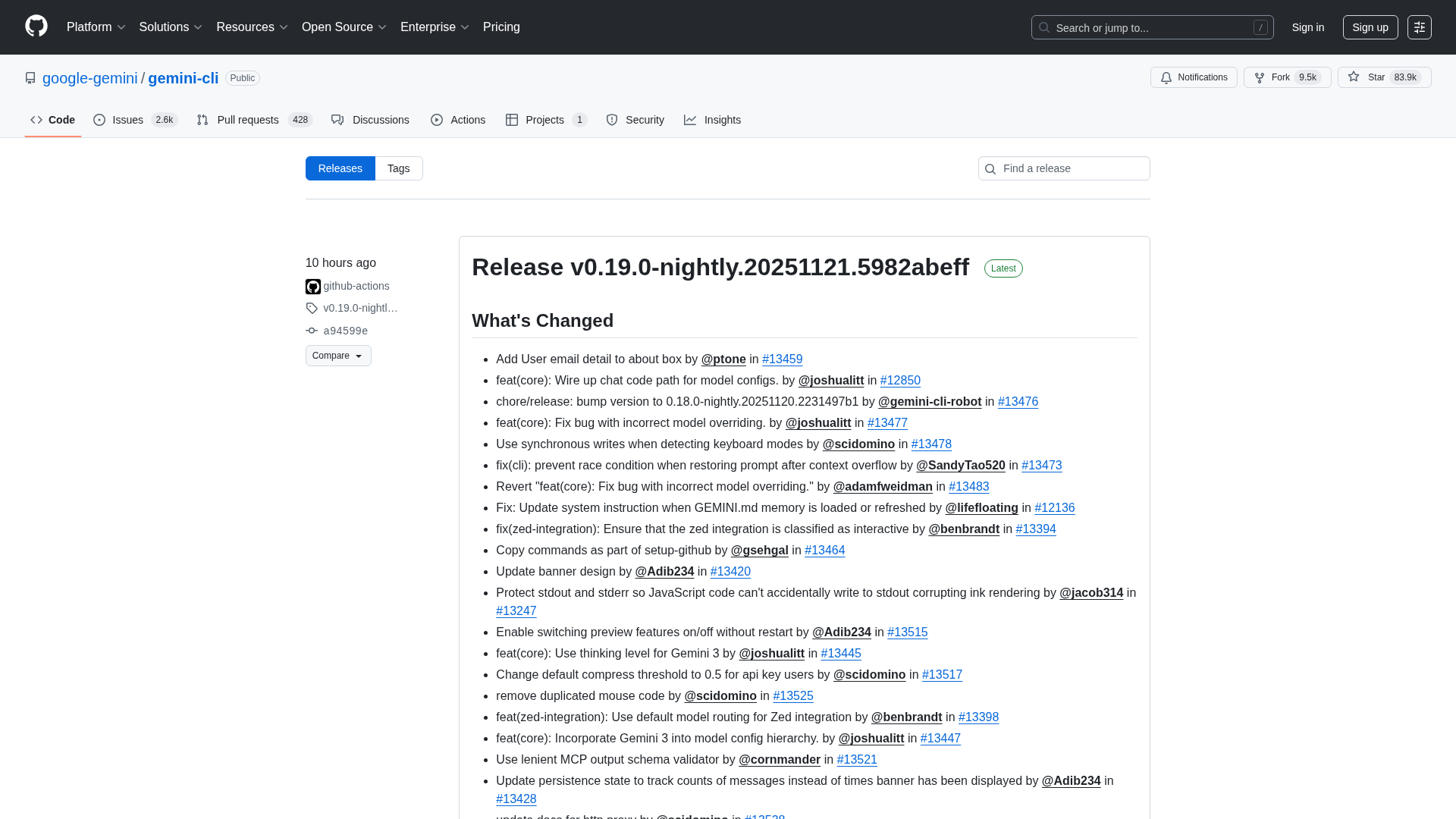
Overview of the Gemini CLI v0.36.0-preview release series, highlighting architectural, CLI, and UI changelogs across multiple pre-release versions.

Baseten launches an AI training platform to compete with hyperscalers, promising simpler, more transparent ML workflows.
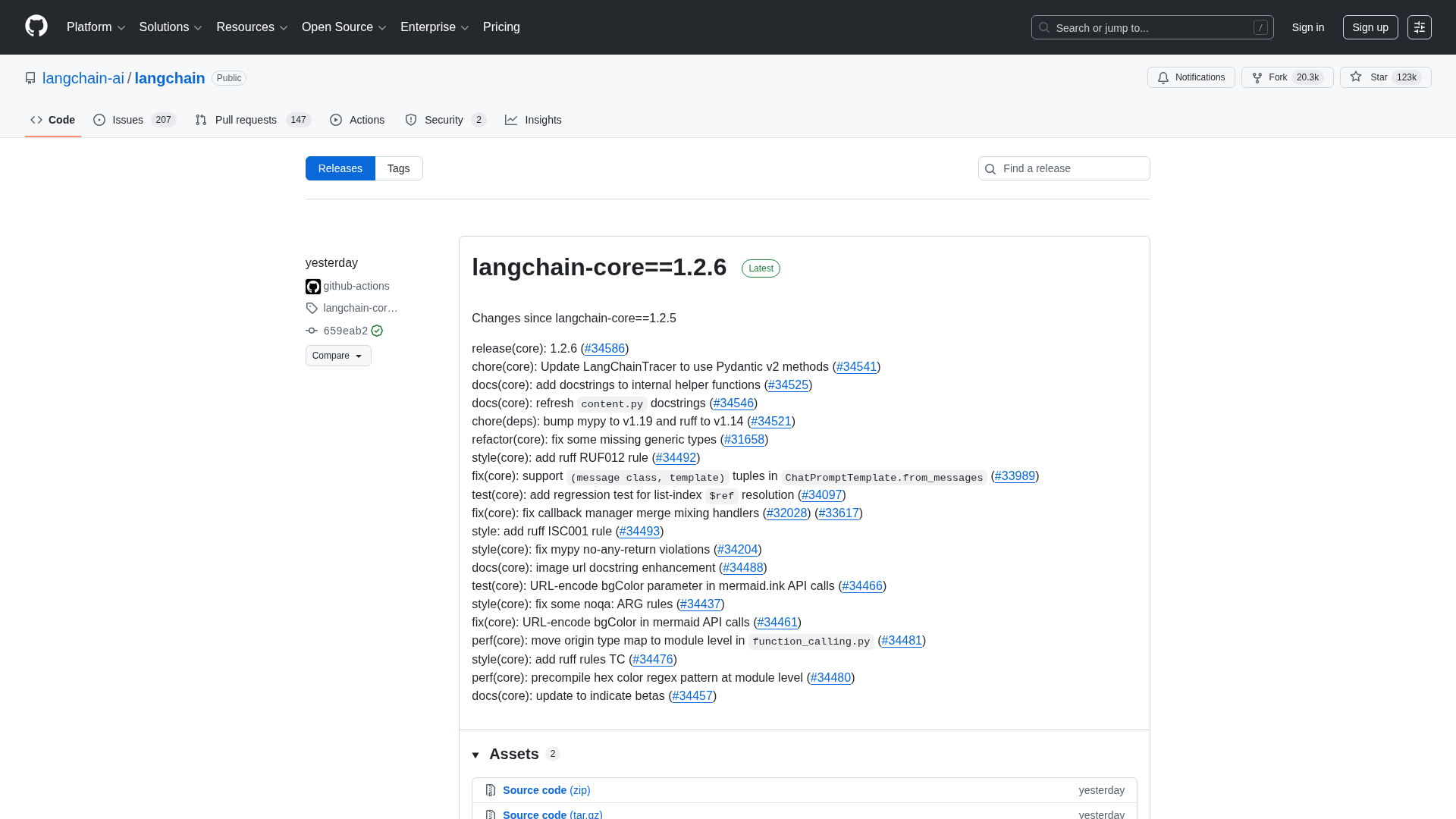
A comprehensive LangChain releases roundup detailing Core 1.2.6 and interconnected updates across XAI, OpenAI, Classic, and tests.
A reproducible bug where LangGraph with Gemini ignores tool results when a PDF is provided, even though the tool call succeeds.