Topic Overview
This topic covers the hardware and software choices that determine how large models are trained and served: GPU/accelerator design, memory hierarchies (DRAM, HBM, NAND/flash), composable/disaggregated memory, and the AI data platforms and orchestration frameworks that use them. It is timely because model sizes, multimodal workloads, and edge/edge-cloud inference requirements continue to push traditional DRAM-bound architectures toward mixed memory strategies and purpose-built inference silicon. Key trends include memory-centric system design (HBM for peak bandwidth, DRAM for working sets, NVMe/NAND for large persistent model storage), emerging interconnects and pooling (CXL, NVMe-oF) that enable disaggregated memory and faster model swapping, and accelerator-specialized silicon for energy-efficient inference. Vendors across the stack matter: GPU and DPU vendors provide compute and memory-coherent platforms; storage/system vendors such as NetApp address persistent storage and data orchestration; component suppliers such as Samsung produce DRAM and NAND that shape cost and capacity trade-offs. Rebellions.ai exemplifies the move to energy-efficient, accelerator-first inference at hyperscale. Edge and developer tooling — Stable Code for compact code models, Tabby and JetBrains AI Assistant for local and IDE-integrated inference — demonstrate demand for smaller, fast models that relieve datacenter memory pressure. On the software side, AI data platforms and frameworks like LangChain and LlamaIndex influence infrastructure needs by enabling retrieval-augmented workflows and fine-grained data access patterns that change memory and I/O demands. Architects should evaluate workload profiles (training vs. streaming inference), memory tiering strategies, and vendor trade-offs (latency, energy, cost, availability of DRAM/NAND). The practical objective is a balanced stack where compute, memory tiers, and data-platform orchestration align to reduce bottlenecks and total cost of ownership while meeting latency and privacy requirements.
Tool Rankings – Top 6
Energy-efficient AI inference accelerators and software for hyperscale data centers.

Edge-ready code language models for fast, private, and instruction‑tuned code completion.

An open-source framework and platform to build, observe, and deploy reliable AI agents.

Developer-focused platform to build AI document agents, orchestrate workflows, and scale RAG across enterprises.
.avif)
Open-source, self-hosted AI coding assistant with IDE extensions, model serving, and local-first/cloud deployment.
In‑IDE AI copilot for context-aware code generation, explanations, and refactorings.
Latest Articles (35)
A comprehensive LangChain releases roundup detailing Core 1.2.6 and interconnected updates across XAI, OpenAI, Classic, and tests.
A reproducible bug where LangGraph with Gemini ignores tool results when a PDF is provided, even though the tool call succeeds.
A practical guide to debugging deep agents with LangSmith using tracing, Polly AI analysis, and the LangSmith Fetch CLI.
A CLI tool to pull LangSmith traces and threads directly into your terminal for fast debugging and automation.
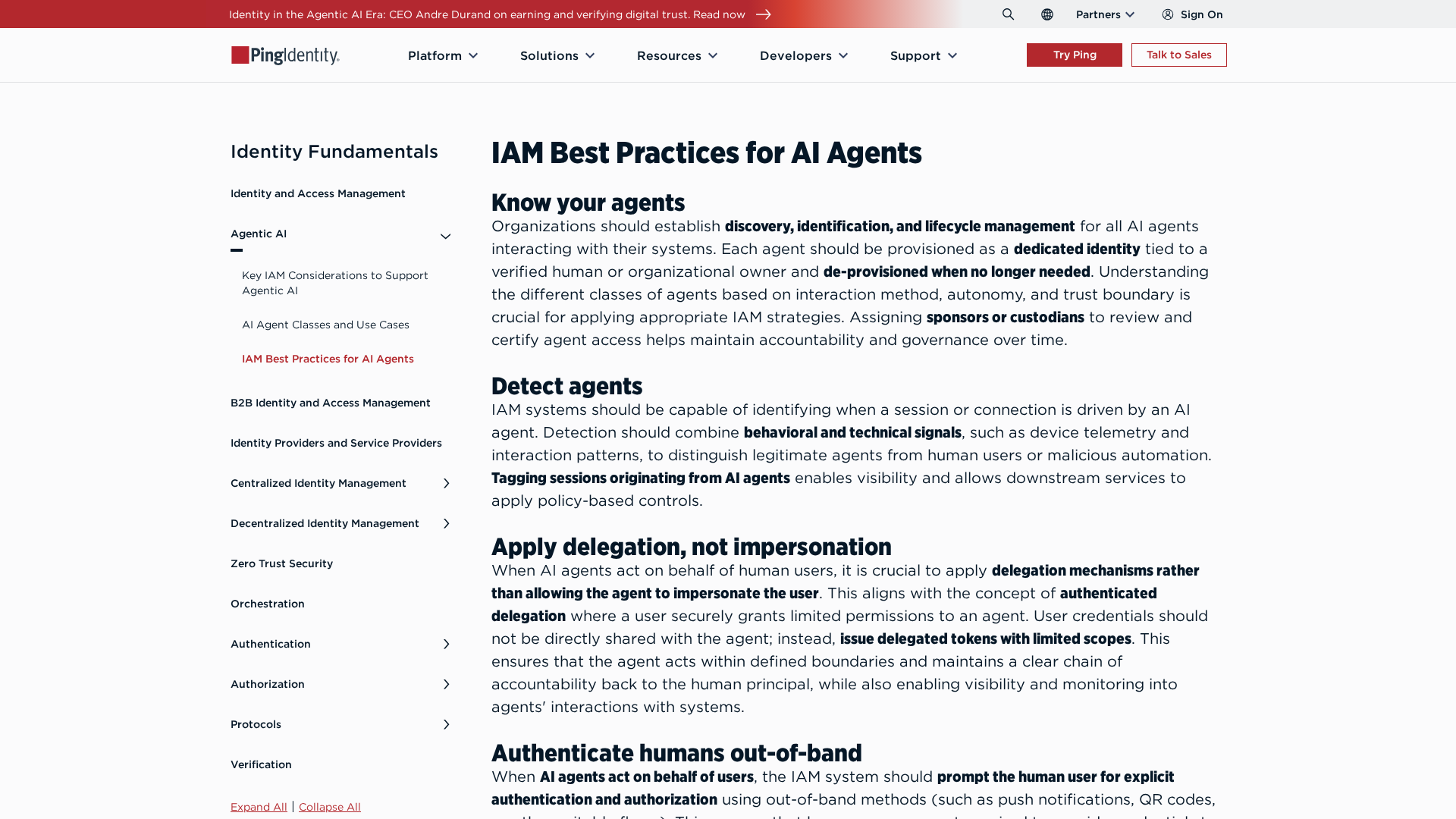
Best-practices for securing AI agents with identity management, delegated access, least privilege, and human oversight.