Topic Overview
This topic focuses on comparing the newest generation of enterprise and edge large language models — Mistral 3, Anthropic Claude Opus 4.5, and Amazon Nova (2025) — to help teams weigh trade‑offs around performance, safety, deployment, and operational costs. By late 2025 enterprises must choose models not only for raw capabilities but for governance, observability, on‑prem or edge inference, and integration into retrieval‑augmented workflows. That makes model comparison a cross‑functional task spanning Competitive Intelligence, AI Governance, and AI Data Platforms. Practical tool categories and examples: Cabina.AI provides a multimodel workspace for parallel chats and output comparisons, useful for human evaluations and competitive benchmarking. LangChain supplies engineering primitives for building, testing, and deploying agentic applications and enforcing deterministic behavior. LlamaIndex helps convert documents into production RAG agents for enterprise knowledge access. OpenPipe captures interaction logs and pipelines data for fine‑tuning and evaluation, and RagaAI offers end‑to‑end testing, observability, and guardrail enforcement for agentic systems. Key trends to consider: enterprises increasingly prioritize latency and privacy (edge/offline inference), measurable safety and audit trails for regulatory compliance, instrumentation for continuous evaluation, and cost‑performance trade‑offs across cloud and edge deployments. A repeatable comparison workflow uses multimodel sandboxing (Cabina.AI), structured prompts and agents (LangChain), RAG and indexing (LlamaIndex), interaction capture and fine‑tuning datasets (OpenPipe), and automated evaluation and guardrails (RagaAI). This integrated approach helps teams make defensible choices about which of the new LLMs best fits their technical constraints, governance requirements, and operational objectives.
Tool Rankings – Top 5
An all-in-one AI workspace for chatting with many LLMs, comparing outputs, organizing conversations, and using token‑dr
Engineering platform and open-source frameworks to build, test, and deploy reliable AI agents.

Developer-focused platform to build AI document agents, orchestrate workflows, and scale RAG across enterprises.

Managed platform to collect LLM interaction data, fine-tune models, evaluate them, and host optimized inference.

The All‑in‑One Platform to Evaluate, Debug, and Scale AI Agents
Latest Articles (48)
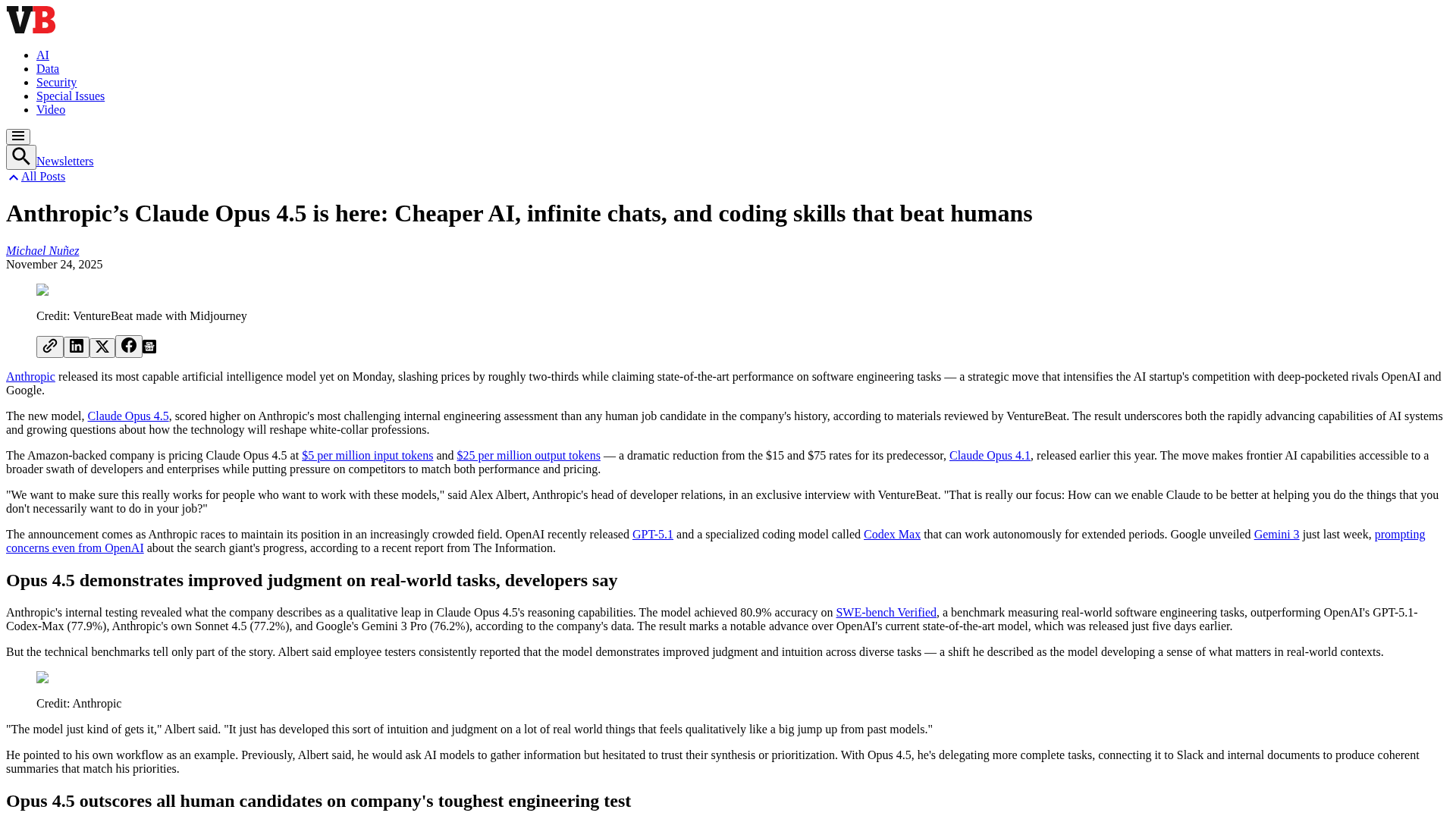
A comprehensive LangChain releases roundup detailing Core 1.2.6 and interconnected updates across XAI, OpenAI, Classic, and tests.

null
Video update highlighting Claude Opus, Anthropic's flagship model designed for complex reasoning.
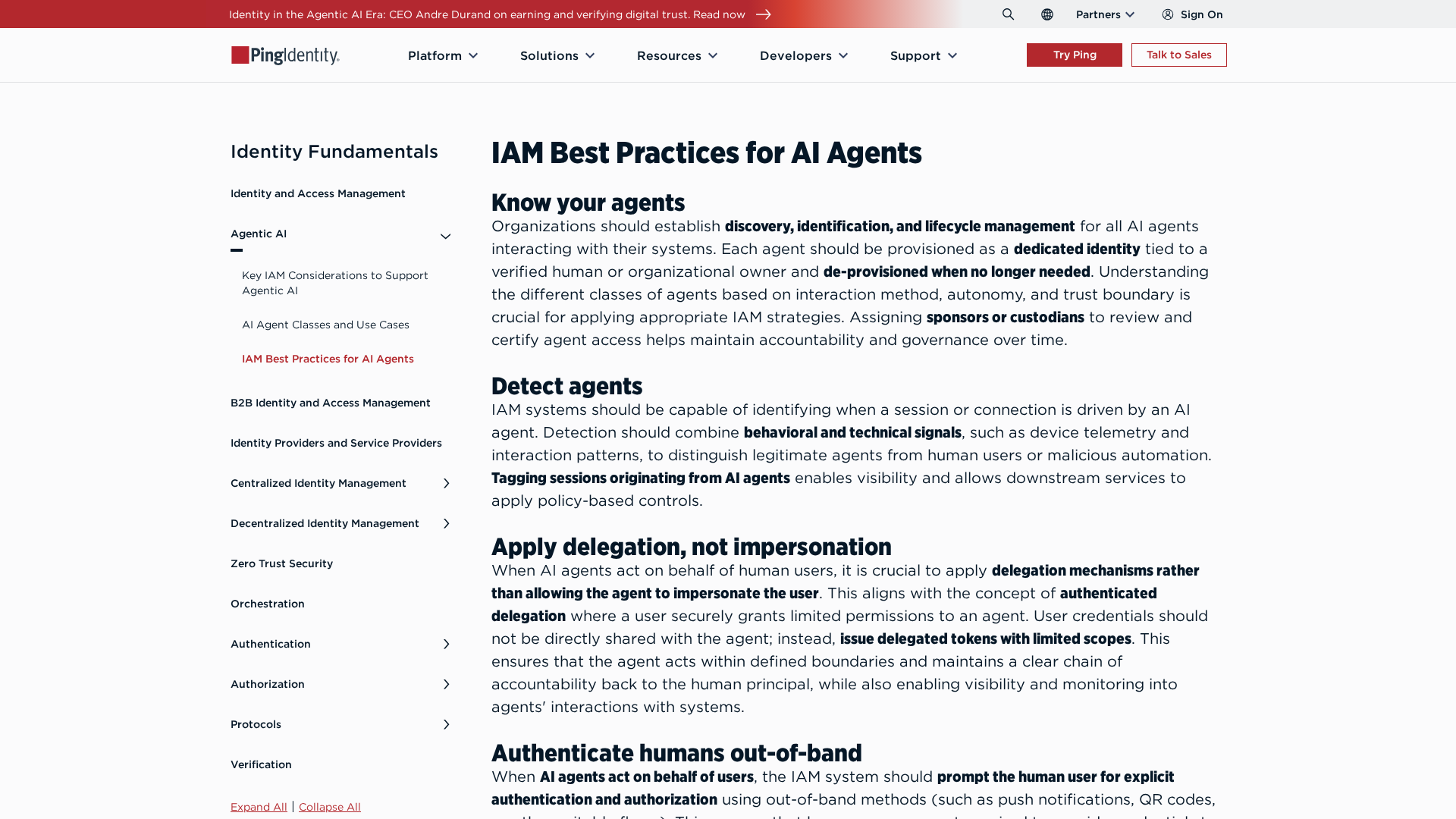
Best-practices for securing AI agents with identity management, delegated access, least privilege, and human oversight.

Cannot access the article content due to an access-denied error, preventing summarization.